

La mayoría de los modelos de Machine Learning son bastante complejos, con una serie de los llamados hiperparámetros, como las capas de una red neuronal, el número de neuronas en las capas ocultas o la tasa de abandono. Para crear el mejor modelo, es necesario elegir la combinación de los hiperparámetros que funcionan mejor. Este proceso suele ser bastante tedioso y consume muchos recursos, pero Azure Machine Learning puede simplificarlo.
En mi publicación anterior sobre Azure Machine Learning, describí cómo empezar a usar Azure ML desde Visual Studio Code. Seguiremos explorando el ejemplo descrito ahí y entrenaremos el modelo sencillo para realizar la clasificación de dígitos en el conjunto de datos de MNIST.
Lee más sobre: ¿Qué es Azure?
Automatización con el SDK de Azure ML para Python
La optimización de los hiperparámetros significa que es necesario realizar un gran número de experimentos con parámetros diferentes. Sabemos que Azure ML nos permite acumular todos los resultados de los experimentos (incluidas las métricas obtenidas) en un solo lugar, el área de trabajo de Azure ML. Lo único que debemos hacer es enviar muchos experimentos con hiperparámetros diferentes.
En lugar de hacerlo manualmente desde VS Code, podemos hacerlo mediante programación a través del SDK de Azure ML para Python. Todas las operaciones, incluida la creación del clúster, la configuración del experimento y la obtención de los resultados se pueden realizar con unas pocas líneas de código de Python. Este código puede parecer un poco complejo al principio, pero una vez que lo escriba (o lo comprenda) verá que es cómodo de usar.
Ejecución del código
El código que menciono en esta publicación está disponible en el repositorio Azure ML Starter. La mayor parte del código que describiré aquí se encuentra dentro del cuaderno submit.ipynb. Puede ejecutarlo de varias maneras:
- Si tiene instalado un entorno de Python local, puede simplemente iniciar la instancia local de Jupyter mediante la ejecución de
jupyter notebooken el directorio consubmit.ipynb. En este caso, debe instalar el SDK de Azure ML mediante la ejecución depip install azureml-sdk - Cargándolo a la sección Notebook del portal de Azure ML y ejecutándolo desde ahí. También tendrá que crear una máquina virtual para ejecutar cuadernos desde el área de trabajo de Azure ML, pero esto se puede hacer sin problemas desde la misma interfaz web.
- Cargándolo en Azure Notebooks.
Si prefiere trabajar con archivos de Python sin formato, el mismo código está disponible también en submit.py.
Conexión con el área de trabajo y el clúster
Lo primero que debe hacer al usar el SDK de Azure ML para Python es conectarse al área de trabajo de Azure ML. Para ello, debe proporcionar todos los parámetros necesarios, como el identificador de la suscripción, el área de trabajo y el nombre del grupo de recursos más información en la documentación:
ws = Workspace(subscription_id,resource_group,workspace_name)
La forma más sencilla de conectarse es almacenar todos los datos requeridos en el archivo config.json y, luego, crear instancias de la referencia del área de trabajo de esta manera:
ws = Workspace.from_config()
Puede descargar el archivo config.json en Azure Portal si va a la página del área de trabajo de Azure ML:

Una vez que obtenemos la referencia del área de trabajo, podemos obtener la referencia al clúster de proceso que queremos usar:
cluster_name = "AzMLCompute"
cluster = ComputeTarget(workspace=ws, name=cluster_name)
En este código se presupone que ya creó manualmente el clúster (tal como se describe en la publicación anterior). También puede crear el clúster con los parámetros requeridos mediante programación y el código correspondiente se proporciona en submit.ipynb.
Preparación y carga del conjunto de datos
En el ejemplo de entrenamiento de MNIST, descargamos el conjunto de datos de MNIST desde el repositorio OpenML de Internet dentro del script de entrenamiento. Si queremos repetir muchas veces el experimento, sería lógico almacenar los datos en algún lugar cerca del proceso: dentro del área de trabajo de Azure ML.
En primer lugar, vamos a crear un conjunto de datos de MNIST como archivo en el disco en la carpeta dataset. Para ello, ejecute el archivo create_dataset.pyy observe que se crea la carpetadataset` y que todos los archivos de datos se almacenan ahí.
Cada área de trabajo de Azure ML tiene asociado un almacén de datos predeterminado. Para cargar el conjunto de datos al almacén de datos predeterminado, solo necesitamos un par de líneas de código:
ds = ws.get_default_datastore()
ds.upload('./dataset', target_path='mnist_data')
Envío automático de los experimentos
En este ejemplo, entrenaremos el modelo de red neuronal de dos capas en Keras, con el script de entrenamiento train_keras.py. Este script puede tomar una serie de parámetros de la línea de comandos, lo que nos permite establecer distintos valores para los hiperparámetros del modelo durante el entrenamiento:
--data_folder, que especifica la ruta de acceso al conjunto de datos.--batch_sizeque se va a usar (el valor predeterminado es 128).--hidden, el tamaño de la capa oculta (el valor predeterminado es 100).--dropoutque se va a usar después de la capa oculta.
Para enviar el experimento con los parámetros especificados, primero tenemos que crear el objeto Estimator para representar el script:
script_params = {
'--data_folder': ws.get_default_datastore(),
'--hidden': 100
}
est = Estimator(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_keras.py',
pip_packages=['keras','tensorflow'])
En este caso, solo se especificó explícitamente un hiperparámetro pero, por supuesto, podemos pasar cualquier parámetro al script para entrenar el modelo con hiperparámetros distintos. Además, tenga en cuenta que el estimador define los paquetes de PIP (o Conda) que se deben instalar para ejecutar el script.
Ahora bien, para ejecutar realmente el experimento, es necesario ejecutar lo siguiente:
exp = Experiment(workspace=ws, name='Keras-Train')
run = exp.submit(est)
Después puede supervisar el experimento directamente en el cuaderno si imprime la variable run (se recomienda tener instalada la extensión azureml.widgets en Jupyter si la ejecuta localmente) o en el portal de Azure ML.

Optimización de los hiperparámetros con HyperDrive
La optimización de los hiperparámetros implica cierto tipo de búsqueda de barrido paramétrico, lo que significa que hay que ejecutar muchos experimentos con distintas combinaciones de hiperparámetros y comparar los resultados. Esto se puede hacer manualmente con el enfoque que acabamos de analizar, o también se puede automatizar con la tecnología denominada Hyperdrive .
En Hyperdrive es necesario definir un espacio de búsqueda para los hiperparámetros y el algoritmo de muestreo, que controla la manera en que se seleccionan los hiperparámetros desde ese espacio de búsqueda:
param_sampling = RandomParameterSampling({
'--hidden': choice([50,100,200,300]),
'--batch_size': choice([64,128]),
'--epochs': choice([5,10,50]),
'--dropout': choice([0.5,0.8,1])})
En nuestro caso, el espacio de búsqueda lo define un conjunto de alternativas (choice), aunque también es posible usar intervalos continuos con distribuciones de probabilidad diferentes (uniform, normal, etc. Más detalles aquí). Además del muestreo aleatorio, también es posible usar el muestreo de cuadrícula (para obtener todas las combinaciones de parámetros posibles) y el muestreo bayesiano.
Además, también se puede especificar la directiva de terminación anticipada. Tiene sentido si el script informa periódicamente las métricas durante la ejecución. En este caso, podemos detectar que la precisión que se logra con una combinación determinada de hiperparámetros es menor que la precisión mediana y dar término anticipado al entrenamiento:
early_termination_policy = MedianStoppingPolicy()
hd_config = HyperDriveConfig(estimator=est,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name='Accuracy',
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=16,
max_concurrent_runs=4)
Una vez que se definen todos los parámetros de un experimento de HyperDrive, podemos enviarlo:
experiment = Experiment(workspace=ws, name='keras-hyperdrive')
hyperdrive_run = experiment.submit(hd_config)
En el portal de Azure ML, la optimización de los hiperparámetros se representa mediante un experimento. Para ver todos los resultados en un grafo, active la casilla Incluir ejecuciones secundarias:

Elección del mejor modelo
Podemos comparar los resultados y seleccionar el mejor modelo de manera manual en el portal. En el script de entrenamiento train_keras.py, después de entrenar el modelo, almacenamos el resultado en la carpeta outputs:
hist = model.fit(...)
os.makedirs('outputs',exist_ok=True)
model.save('outputs/mnist_model.hdf5')
Una vez hecho esto, podemos ubicar el mejor experimento en el portal de Azure ML y obtener el archivo .hdf5 correspondiente que se usará en la inferencia:
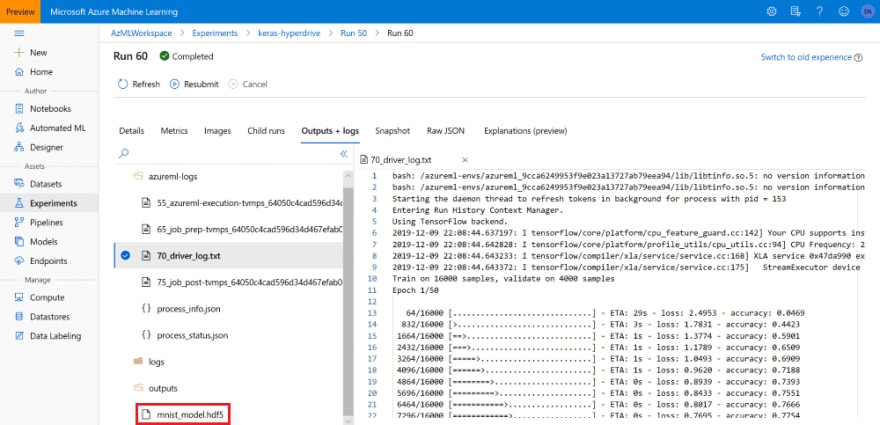
También se puede usar la Administración de modelos de Azure Machine Learning para registrar el modelo, lo que nos podría permitir llevar un mejor seguimiento del mismo y usarlo durante la implementación de Azure ML. Podemos encontrar el mejor modelo y registrarlo mediante programación con el código siguiente:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
print('Best accuracy: {}'.format(best_run_metrics['Accuracy']))
best_run.register_model(model_name='mnist_keras',
model_path='outputs/mnist_model.hdf5')
Conclusión
Aprendimos a enviar experimentos de Azure ML mediante programación a través del SDK de Python y a realizar la optimización de los hiperparámetros con HyperDrive. Aunque acostumbrarse a este proceso tarda un poco, pronto se dará cuenta de que Azure ML simplifica el proceso de ajuste del modelo si lo compara con hacerlo “a mano” en una instancia de Data Science Virtual Machine.
Referencias
Curso de Inteligencia Artificial con IBM Watson
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE






