

Si tuviéramos que definir el concepto de un API en una línea, la mejor aproximación podría ser:
Una interfaz hecha para desarrolladores que expone nuestros recursos de una forma entendible y accesible para otros.
La parte clave en esta frase es ”hecha para desarrolladores". Todo el diseño que planeemos y todo el código que escribamos para nuestra API tiene que crearse pensando en eso. Cuando construimos nuestras primeras APIs el diseño no era tan importante. Pero a medida que vamos creciendo como desarrolladores, y los proyectos son cada vez más grandes; nos enteramos de que hay toda una serie de convenciones y para construir un API. En este artículo, tocaremos algunos de los puntos más comunes e importantes a la hora de construir un API.
Sustantivos sí, verbos no.
Cuando escribimos código, estamos acostumbrados a nombrar a los métodos con verbos que describan su funcionalidad. Por ejemplo, una función que regresa un objeto con todos los usuarios llevaría el nombre de get_users o **getUsers. ** Esto está bien en el código. Pero también es común en las URLs y no es una buena práctica. Supongamos que crearemos el API de Platzi en donde tendremos una URL que nos regresará un JSON con todos los cursos disponibles. Entonces, lo primero que nos vendría a la mente sería crear una URL así:
<pre>/getCourses</pre>
De igual manera, si llegamos a necesitar más URL’s para crear cursos, editarlos, borrarlos u obtener la información de uno en específico; nuestras URLs serían algo parecido a esto:
<pre>/getCourses /createCourse /editCourse /deleteCourse /getCourse/:id</pre>
Con el paso del tiempo y al crear más y más URLs, esto comenzará a tornarse aburrido y difícil de recordar. Una mejor solución podría ser mantener sólo **2 URL’s base por recurso. **De esta manera, nuestras URL’s lucirían algo así.
<pre>/courses y /courses/:id</pre>
Lo importante aquí es no usar verbos y enfocarnos en los sustantivos que describen a cada recurso. Ahora, para operar sobre nuestro recurso podemos usar los verbos HTTP. Un **CRUD **(Create - Read - Update - Delete) puede ser representado por los verbos **POST, GET, PATCH **(antes PUT) y **DELETE. ** Continuando con el ejemplo de los cursos y teniendo únicamente 2 URLs base, podemos realizar las mismas acciones de una manera más intuitiva. Funcionaría así: 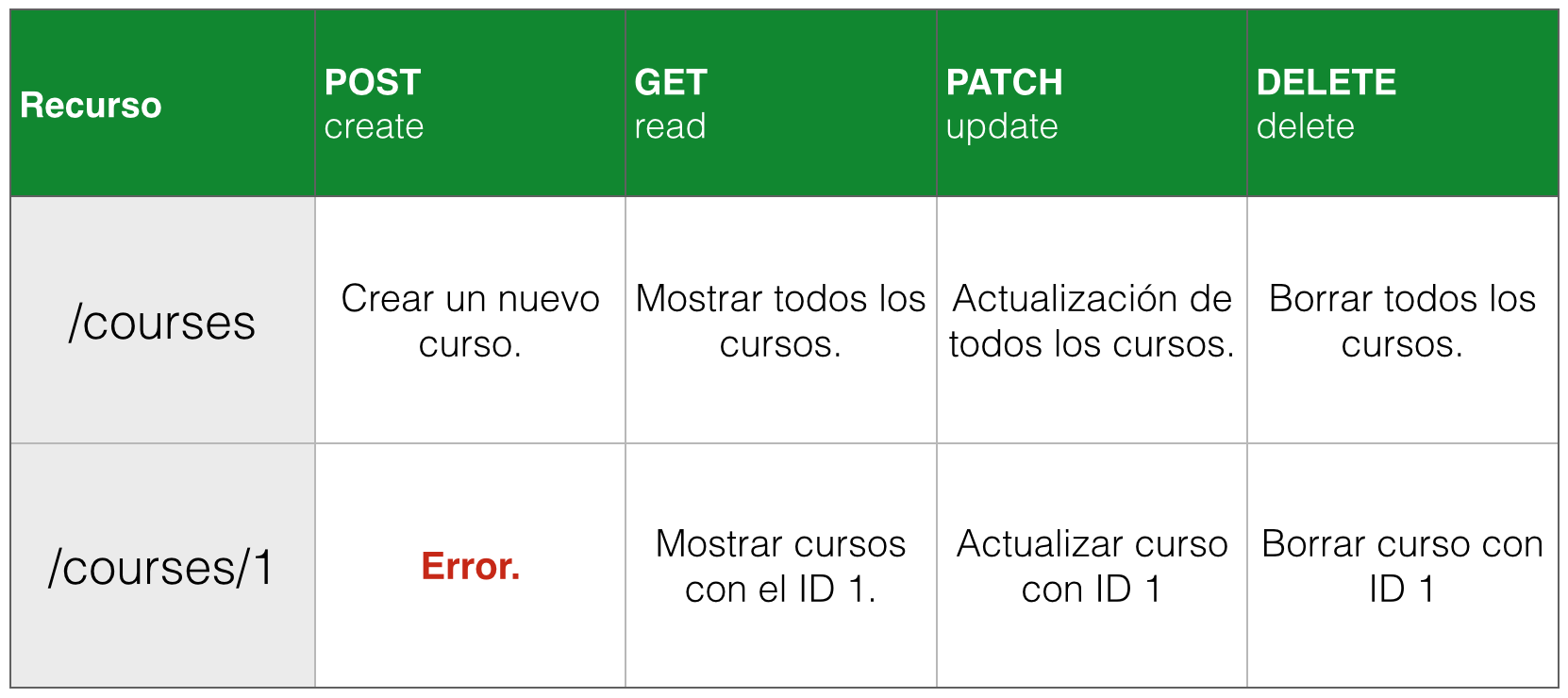 Recordatorio: Mantengamos lo simple, simple. Cuando elegimos el nombre de nuestro recurso, es mejor usar nombres concretos que definan a nuestras entidades con sólo leerlas en lugar de alguna abstracción más compleja. Pensemos ahora que tenemos que exponer los artículos, videos y tweets de Platzi. Considerando lo anterior, sería una mala idea escribir una URL del tipo /items o /content, ya que es se trata de sustantivos bastante abstractos y no indican qué tipo de recurso se está consumiendo. Si, por el contrario, configuramos URLs como /posts, /videos, /tweets, nuestros desarrolladores sabrán inmediatamente de qué va cada URL. Elegir el sustantivo que identificará un recurso suele ser sencillo. Mi última recomendación sería mantenerlos en plural. Tal como lo hacen muchas otras APIs. Evitemos la mezcla de singulares y plurales. En resumen, mantengamos las URLs simples y concretas.
Recordatorio: Mantengamos lo simple, simple. Cuando elegimos el nombre de nuestro recurso, es mejor usar nombres concretos que definan a nuestras entidades con sólo leerlas en lugar de alguna abstracción más compleja. Pensemos ahora que tenemos que exponer los artículos, videos y tweets de Platzi. Considerando lo anterior, sería una mala idea escribir una URL del tipo /items o /content, ya que es se trata de sustantivos bastante abstractos y no indican qué tipo de recurso se está consumiendo. Si, por el contrario, configuramos URLs como /posts, /videos, /tweets, nuestros desarrolladores sabrán inmediatamente de qué va cada URL. Elegir el sustantivo que identificará un recurso suele ser sencillo. Mi última recomendación sería mantenerlos en plural. Tal como lo hacen muchas otras APIs. Evitemos la mezcla de singulares y plurales. En resumen, mantengamos las URLs simples y concretas.
Te explicamos: Qué es una API RESTful.
Relaciones entre recursos
Hasta este punto, estas recomendaciones podrían parecer sencillas. Pero, ¿qué pasa cuando nuestros recursos se relacionan entre sí? Imaginemos que queremos construir una URL para obtener los nombres de usuario de todos los estudiantes que han terminado un curso en específico. Quedaría algo así:
<pre>/courses/:id/students
</pre>
¿Y cómo sería si ahora queremos obtener un JSON con todos los estudiantes que hayan terminado un curso en específico pero que también hayan comprado la membresía de navidad? La URL sería un poco más larga. Algo parecido a esto:
<pre>/memberships/:id/courses/:id/students</pre>
Como puedes observar, esta URL no sigue la recomendación de mantener nuestra API intuitiva. Para el caso anterior, y en general para relaciones entre recursos; podríamos definir una simple regla que nos será muy útil a la hora de diseñar. La profundidad máxima de nuestras URLs debe ser de 2 niveles. Es decir, recurso-identificador-recurso. Y aún así, deberíamos evitar a toda costa tener URLs de este tipo.
<pre>/recurso/:id/recurso</pre>
Este problema podría resolverse de una manera un poco más inteligente y limpia. Haciendo uso de los parámetros por medio de ‘?’.
<pre>/courses/:id/students/?membership=:id</pre>
O incluso aprovechando mucho más los parámetros y eliminando la concatenación de recursos de la siguiente manera:
<pre>/students/?membership=:id&finished_courses=[":id", “:id”]</pre>
Usando los parámetros a través de la URL también podríamos aplicar filtros en nuestras consultas y mantener las URLs lo más simple posible.
¡Manejemos errores!
Cuando un desarrollador trabaja con nuestra API, todo lo que pasa por dentro es una caja negra para él. Sí algo falla y no le damos la suficiente información, el uso de nuestra API comenzará a ser frustrante y aburrido. Recordemos cómo fue nuestro proceso al aprender a programar o a usar una nueva tecnología. Los desarrolladores solemos aprender en la práctica y de los errores. Así que el manejo de errores de nuestra API se convertirá en una de las herramientas principales de los que nos consuman. Así como usamos los verbos HTTP para manejar las operaciones (un CRUD) a un recurso, también podemos manejar los códigos HTTP para mostrar el estado de una petición. Por otro lado, si nuestra API es muy grande y compleja, es recomendable manejar códigos internos de error. Generalmente tenemos tres tipos de estados en una respuesta:
- Todo funcionó a la perfección
- Ocurrió un error producido por una mala petición del usuario
- Ocurrió un error de nuestro lado
Podemos manejar todos los códigos de estado que queramos. Pero es recomendable no excedernos en este número. Por ejemplo, Google en su GData API usa sólo 10 códigos de estado; mientras que el API de Netflix sólo usa 9. Esa decisión la podrás tomar tú, dependiendo de la complejidad de tu sistema. Pero siempre recuerda **mantener las cosas****simples **. En caso de que manejes códigos de error internos, recuerda que estás comunicándote con humanos por lo que procura escribir mensajes que puedan ser entendidos por otros.
Usando versiones
Que nuestra API cuente con una versión, y mantenerla siempre a la vista en las peticiones es una buena práctica. Por ejemplo, Facebook en su Graph API mantiene la versión en la URL así:
<pre>https://graph.facebook.com/v2/me</pre>
Por lo general, estamos acostumbrados a versionar así: _0.0.0 _. Pero para las URLs es recomendable mantener la versión en el más alto nivel. Por otro lado, cuando liberamos una nueva versión de nuestra API no podemos simplemente sustituirla por la versión existente y olvidar que tenemos desarrolladores usando la _versión vieja. _ Mantener al menos una versión anterior a la más actual, es y será siempre una buena práctica. Cuando manejamos versiones, siempre nos surgirá la pregunta ¿y si mantengo la URL más limpia eliminando la versión? Esta sería una buena solución e incluso estaría más apegada a los estándares de HTTP. Sin embargo, agregaría complejidad a la hora de hacer peticiones por el navegador y podría hacer su uso un poco más complicado. Empresas como Facebook, Google y Yahoo suelen mantener la versión siempre en la URL. Recordemos, el uso de nuestra API tiene que ser intuitivo. Para definir esto, podríamos usar otra regla. Si cambia directamente la lógica de una respuesta, es preferible que se ponga en la URL. Si por el contrario, no cambia la lógica y sólo se transporta información, es recomendable poner la versión en las cabeceras.
Respuestas Parciales
Imaginemos ahora que solicitamos todos los estudiantes de Platzi de la siguiente manera: GET https://api.platzi.com/v1/students La respuesta regresa algo así. 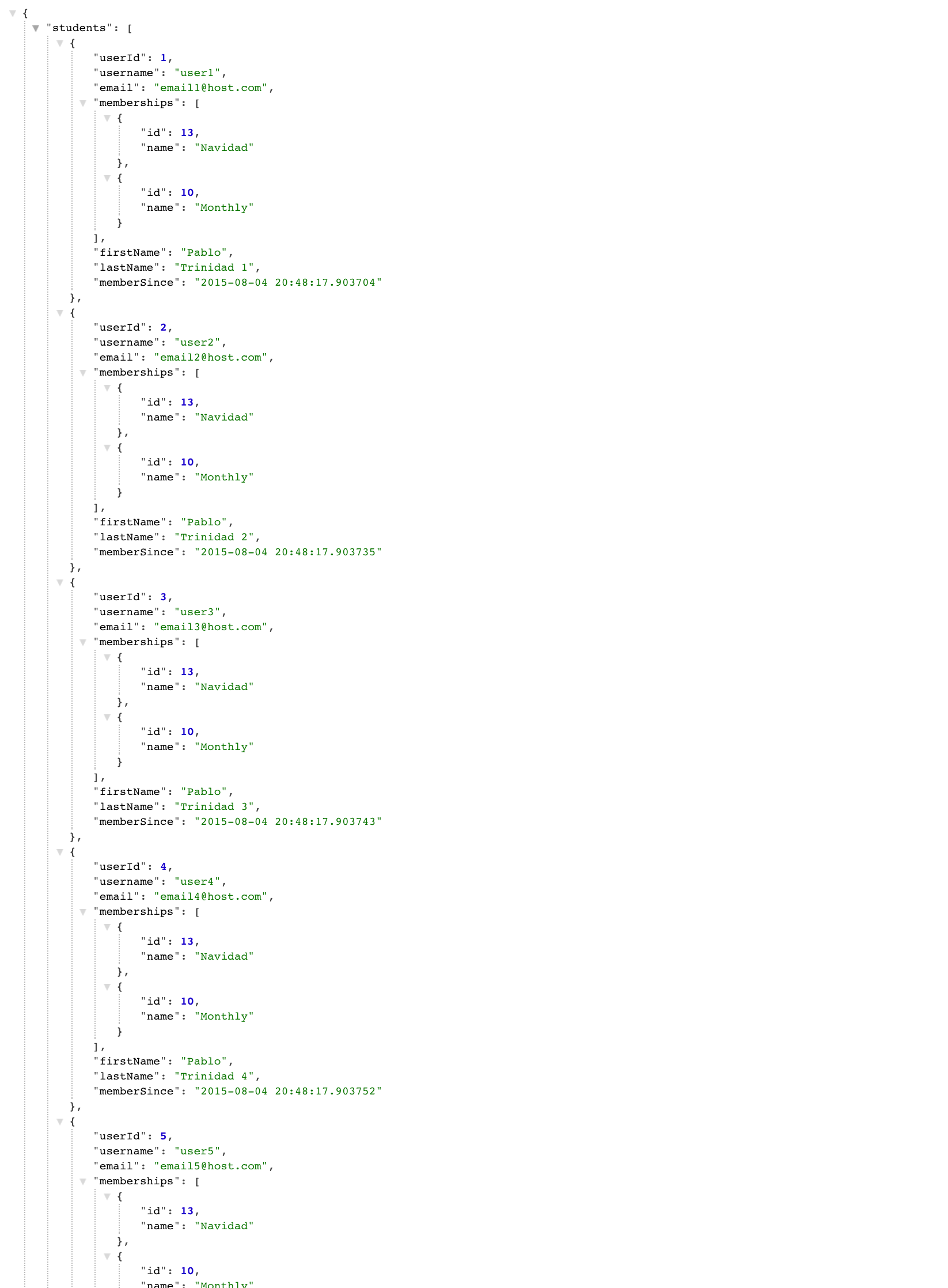 En el ejemplo, /students/ nos regresa 998 estudiantes. Aquí es donde está la primer alarma. Cuando hacemos un LIST sobre alguno de los recursos de nuestra base de datos, es una muy mala idea regresar absolutamente todo lo que nuestra base de datos contiene. Este tipo de consultas son o muy difíciles de manejar del lado del cliente, o muy lentas del lado del servidor. Es recomendable regresar sólo un número determinado de registros por petición y paginar las siguientes peticiones. Algunas muy buenas APIs regresan metadata con atributos como el count, que nos dice cuántos registros totales existen para ese recurso; **limit ** nos dice cuántos registros por llamada incluye y offset indica a partir de qué registro será la siguiente llamada. Otros parámetros como **nextPage **o **previousPage **incluyen una URL ya construida para la siguiente llamada con los siguientes datos. Parámetros como limit y offsetdeberían ser posibles de configurar naturalmente por el desarrollador. Este debería decidir cuántos registros quiere (teniendo un límite interno) o a partir de qué registro quiere obtener datos. Para la URL de estudiantes podríamos ahora tener lo siguiente: GET _https://api.platzi.com/v1/students/?limit=25&offset=40 Otro de los problemas más comunes que ocurren cuando consumimos un API es que la respuesta nos trae mucho más datos de los que queremos. En una buena API deberíamos ser capaces de definir qué campos queremos que nos regresen de un recurso y de esta manera obtener un respuesta personalizable y más rápida. Supongamos que queremos obtener a todos los usuarios de Platzi, pero sólo queremos su userId y su email. Podríamos incluir en la llamada el parámetro fields que indicará qué campos queremos de ese recurso. GET _https://api.platzi.com/v1/students/?fields=userId,email Y la respuesta tendría que ser algo similar a lo siguiente:
En el ejemplo, /students/ nos regresa 998 estudiantes. Aquí es donde está la primer alarma. Cuando hacemos un LIST sobre alguno de los recursos de nuestra base de datos, es una muy mala idea regresar absolutamente todo lo que nuestra base de datos contiene. Este tipo de consultas son o muy difíciles de manejar del lado del cliente, o muy lentas del lado del servidor. Es recomendable regresar sólo un número determinado de registros por petición y paginar las siguientes peticiones. Algunas muy buenas APIs regresan metadata con atributos como el count, que nos dice cuántos registros totales existen para ese recurso; **limit ** nos dice cuántos registros por llamada incluye y offset indica a partir de qué registro será la siguiente llamada. Otros parámetros como **nextPage **o **previousPage **incluyen una URL ya construida para la siguiente llamada con los siguientes datos. Parámetros como limit y offsetdeberían ser posibles de configurar naturalmente por el desarrollador. Este debería decidir cuántos registros quiere (teniendo un límite interno) o a partir de qué registro quiere obtener datos. Para la URL de estudiantes podríamos ahora tener lo siguiente: GET _https://api.platzi.com/v1/students/?limit=25&offset=40 Otro de los problemas más comunes que ocurren cuando consumimos un API es que la respuesta nos trae mucho más datos de los que queremos. En una buena API deberíamos ser capaces de definir qué campos queremos que nos regresen de un recurso y de esta manera obtener un respuesta personalizable y más rápida. Supongamos que queremos obtener a todos los usuarios de Platzi, pero sólo queremos su userId y su email. Podríamos incluir en la llamada el parámetro fields que indicará qué campos queremos de ese recurso. GET _https://api.platzi.com/v1/students/?fields=userId,email Y la respuesta tendría que ser algo similar a lo siguiente: 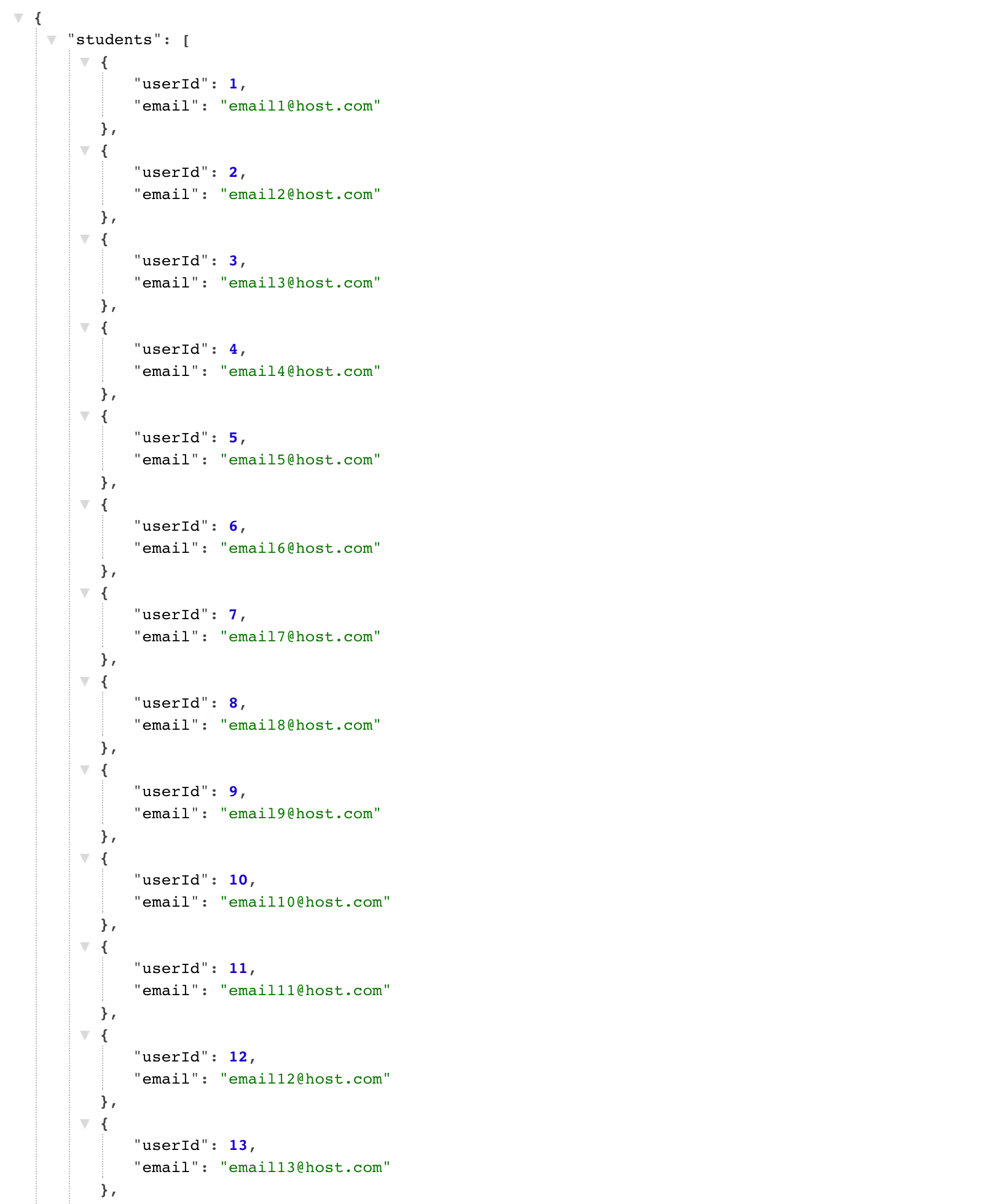
¿Qué pasa si la respuesta no involucra a un recurso?
En este caso, la manera en que nombraríamos a la URL podría ser usando verbos. Tomemos como ejemplo, una función en la API de Platzi que nos convierta monedas. Así podríamos calcular el costo en cada país. Nuestra URL podría llamarse así y podemos usar los parámetros de URL para pasar los valores. GET https://api.platzi.com/v1/convercurrency/**?from=USD&to=MXN&amount=299** Y para este caso sería importante aclarar en la documentación que esta función no es un recurso sino una funcionalidad.
Formatos
Es recomendable que nuestra API soporte más de un formato. El más usado y en el que la mayoría de las API’s responden es mediante un JSON. Este debería ser editable para que si el developer lo requiere, le regrese un XML o un **JSONP **, por ejemplo. Podríamos definir el formato en la URL usando algo parecido a **?format=xml ** o ?type=json. La mayoría de las API’s definen este valor en la URL pero también es correcto pasar este valor por las cabeceras. Y si prefieres usar JSON como formato, procura usar las convenciones de JavaScript para nombrar los atributos de nuestras respuestas. Si quieres aprender a construir tus propias aplicaciones web o APIs, te recomiendo tomar el curso de Backend de Platzi. Ahí aprenderás muchos más trucos para construir APIs como un profesional.
Educación online efectiva
Aprende con expertos de la industria
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







