

¿Sabías que sólo con JavaScript y Expresiones Regulares puedes extraer información pública desde internet, de forma automatizada y con relativa facilidad?
El web scraping (pronunciado más o menos como “güeb-screipin”) es una de las técnicas más usadas en la ciencia de datos para procesar la inmensa cantidad de información que existe en la web y generar con ella bases de datos estructuradas que son de gran utilidad para el Marketing Digital y la Indexación de Contenidos. Empresas como Google, Trivago y Kayak usan esta estrategia en sus modelos de negocios.
Para hacer web scraping se necesitan básicamente cuatro pasos:
- Analizar el contenido
- Extraer fragmentos de texto
- Procesarlos y darles formato
- Almacenar y/o renderizar los resultados
En este artículo pretendo mostrarte la forma de completar estos pasos con la ayuda de “la navaja suiza de todo buen programador”: las Expresiones Regulares.
Paso 1: Analizar el contenido
Antes de empezar a escribir código es necesario tener un plan. Cuando se trata del contenido de la web, lo principal es entender claramente cómo está formado el HTML con el que vamos a trabajar e identificar con mucha precisión cuáles son los datos que nos interesa extraer. Así que lo primero que haremos será encontrar un sitio con información pública disponible y analizar su código HTML.
Intentemos algo con MercadoLibre. Diremos que nos interesa extraer del sitio web de MercadoLibre Colombia los datos más recientes sobre juegos de PS4 que tengan al menos un 40% de descuento en relación a su precio regular, tomando en cuenta primero los de mayor precio.
Descubrimos que MercadoLibre utiliza el método GET para establecer los filtros de búsqueda en su sitio web, por lo que al aplicar normalmente criterios de selección, todo queda guardado en la url. Ya he usado los criterios de palabras de búsqueda, descuento, ordenamiento y además he incluido que tengan envío gratis. Esta es la URL que ha resultado:
Como resultado del análisis identificamos que cada uno de los elementos de la lista de resultados está asociado a un <li> que tiene la siguiente forma:
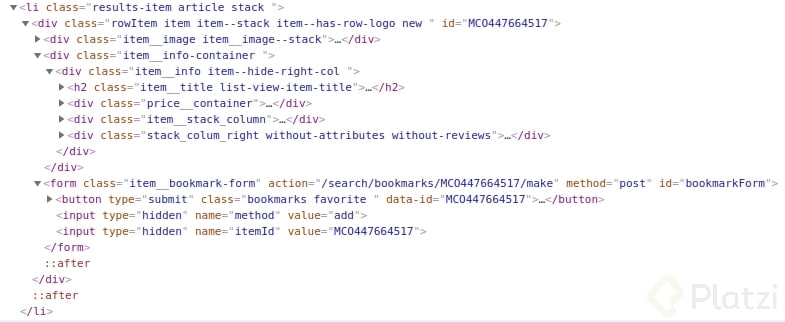
Y queremos extraer:
- Nombre del producto
- Foto
- Precio original
- % de descuento
- Precio de oferta
- y el link para ir directo al producto
El Plan
Diseñar y construir una Expresión Regular que nos permita hacer coincidir todo el elemento LI y extraer, para cada uno de los productos de la lista, estos 6 datos al mismo tiempo mediante agrupaciones.
Luego prepararlos y almacenarlos en un arreglo de objetos JSON para iterar finalmente sobre ellos y mostrarlos en nuestro sitio de una manera más personalizada y amigable.
Paso 2: Extraer los datos que nos interesan
Primero necesitamos traer al entorno local todo el código HTML de los productos filtrados. Los traeremos en formato de texto para poder luego extraer y procesar los datos. Para ello usaremos el siguiente bloque de código:

El script anterior nos traerá el código HTML de ML con los resultados de la búsqueda y los pasará como parámetro a la función procesarResultados(…) que veremos más adelante.
NOTA: No vamos a profundizar en el funcionamiento del código anterior para no desviarnos de nuestro objetivo, aunque te recomiendo luego analizarlo para entender un poco más sobre fetch y las promesas de JS.
Para extraer los datos definiremos un patrón bastante específico y completo apoyándonos principalmente en la capacidad de agrupación de las expresiones regulares.
El resultado de un par de horas de análisis y diseño es la siguiente expresión regular nivel “ninja”:
/<img(?:.*?)alt=\'(.*?)\'(?:.*?)src=\'(.*?)\'(?:.*?)<a(?:.*?)href=\"(.*?)\"(?:.*?)<del>(.*?)</del>(?:.*?)fraction\">(.*?)</span>?(?:.*?)discount(?:.*?)>(.*?\%)/gm
Que incluiremos en el siguiente código:
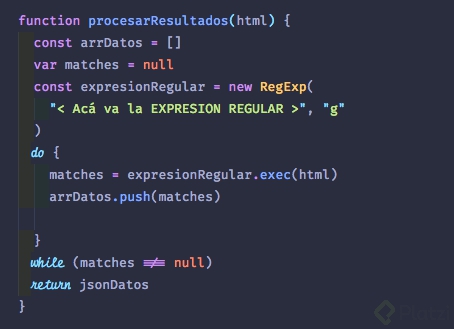
Paso 3: Procesar los datos y darles formato
Como se puede ver en el código anterior, JavaScript tiene su propia clase para implementar expresiones regulares llamada RegExp() que incluye principalmente los métodos compile(), test() y exec(). Para efectos de simplicidad, sólo usaremos exec() ya que es suficiente para lograr nuestro objetivo.
El método exec() de RegExp devolverá un arreglo con todas las coincidencias de la expresión regular que hayan sido agrupadas entre paréntesis y que no contengan los caracteres de exclusión (?: )
Luego, por cada arreglo de elementos coincidentes con la expresión, agregaremos un elemento al arreglo de datos de salida arrDatos, que se verá más o menos así:
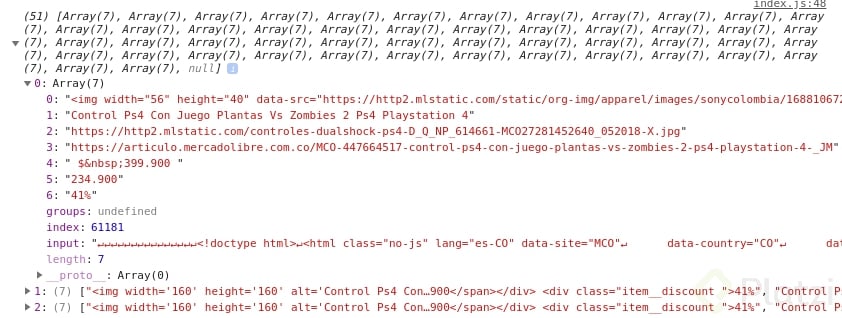
En la posición 0 estará la cadena original que coincidió con la expresión, mientras que a partir del elemento 1 en adelante estarán los valores extraídos por las agrupaciones definidas en la expresión regular.
Observa bien… ¡Es magia!
Paso 4: Almacenar y/o renderizar los datos
Ya luego sólo nos queda devolver este arreglo y pasarlo a una función que tome cada elemento y lo envíe a un archivo en el disco, a una que le dé el formato personalizado que queremos en el html de nuestro sitio, algo como:
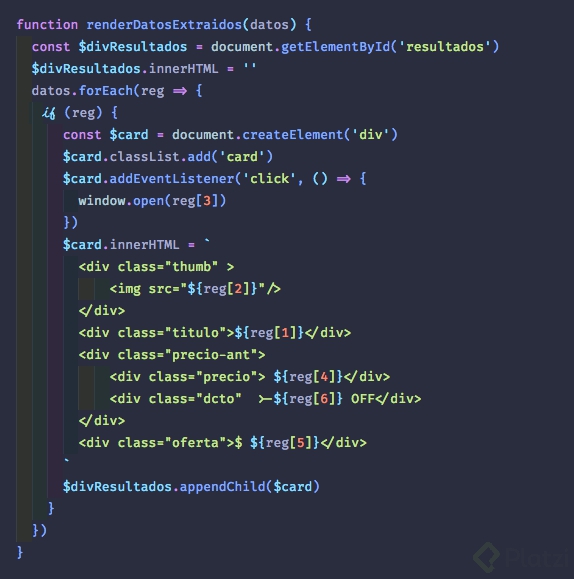
Y ¡voilá! Tenemos un sitio web enlazado automáticamente a la fuente original, extrayendo datos de nuestro interés mediante el uso de Web Scraping. Lo hemos logrado con el apoyo de las expresiones regulares de manera rápida, relativamente sencilla y con menos de 80 líneas de código.
Impresionante, ¿cierto?
Tú también puedes lograr resultados mágicos como estos y a un nivel ninja gracias a todo lo que enseña Beco en el Curso de Expresiones Regulares de Platzi.
¡Hasta la próxima!
Curso de Expresiones Regulares
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







