

R es un lenguaje de programación especialmente usado en áreas de Data Science para computación estadística, visualización de datos y cómputo en paralelo.
En el Curso de Fundamentos de R, se explican detalles y fundamentos básicos que nos permitirán iniciar de cero en este increíble y potente lenguaje.
Ahora, vayamos al grano. En este blog les explicaré paso a paso:
- Librerías para consumir API’S
- Manipulación de respuestas
- Cálculo y visualización de estadística aplicada al conjunto de datos.
Partamos entonces de dónde obtendremos los datos… La respuesta es simple: Datos Abiertos de México. Esta plataforma nos provee de más de 40.000 datos abiertos (sí, leíste bien) de 280 Instituciones Públicas en México, incluyendo sectores como:
- Educación
- Seguridad
- Salud
- Cultura y Turismo
- Economía
- Desarrollo
Podremos encontrar estos conjuntos de datos en diversos formatos (API’s, CSV, XLS, XML, etc.) para poder consumirlos a nuestra disposición, teniendo en cuenta que a veces los datos hay que limpiarlos pues no están optimizados.
Para fines prácticos y demostrativos, elegiremos un API de CONAGUA (Comisión Nacional del Agua) que nos provee un histórico de más de 13 millones de registros de las condiciones atmosféricas de todo el país.
API: Condiciones Atmosféricas - CONAGUA
Entonces… comencemos.
Aprende más sobre ¿Qué es una API REST?
Lo primero que hay que hacer
- Instalar e importar las librerías necesarias:
install.packages(c("httr", "jsonlite","dplyr"))
library(httr)
library(jsonlite)
library("dplyr")
- Llamar el API a través de una petición GET
res <- GET("https://api.datos.gob.mx/v1/condiciones-atmosfericas")
- Convertir la respuesta a un formato JSON mapeable
dat <- fromJSON(rawToChar(res$content))
- Imprimir resultado del contenido a través de una iteración (for-loop, véase Curso de Programación Básica)
for (i in 1:as.integer(dat$pagination$pageSize)) {
id <- paste("ID:", i)
cat("\n")
print(id)
print(dat[["results"]][["date-insert"]][i])
print(dat[["results"]][["state"]][i])
print(dat[["results"]][["name"]][i])
print(dat[["results"]][["latitude"]][i])
print(dat[["results"]][["longitude"]][i])
print(dat[["results"]][["skydescriptionlong"]][i])
print(dat[["results"]][["windspeedkm"]][i])
}
Resultado:
[1] "ID: 1"
[1] "2017-06-27T17:36:43.084Z"
[1] "Aguascalientes"
[1] "Aguascalientes"
[1] "21.87982"
[1] "-102.296"
[1] "Tormentas dispersas"
[1] "6"
[1] "ID: 2"
[1] "2017-06-27T17:36:43.088Z"
[1] "Aguascalientes"
[1] "Asientos"
[1] "22.23832"
[1] "-102.0893"
[1] "Tormentas dispersas"
[1] "5"
[1] "ID: 3"
[1] "2017-06-27T17:36:43.088Z"
[1] "Aguascalientes"
[1] "Calvillo"
[1] "21.84691"
[1] "-102.7188"
[1] "Tormentas dispersas"
[1] "2"
[1] "ID: 4"
[1] "2017-06-27T17:36:43.088Z"
[1] "Aguascalientes"
[1] "Cosío"
[1] "22.36641"
[1] "-102.3"
[1] "Tormentas dispersas"
[1] "3"
[1] "ID: 5"
[1] "2017-06-27T17:36:43.089Z"
[1] "Aguascalientes"
[1] "El Llano"
[1] "21.91887"
[1] "-101.9653"
[1] "Tormentas dispersas"
[1] "3"
[1] "ID: 6"
[1] "2017-06-27T17:36:43.089Z"
[1] "Aguascalientes"
[1] "Jesús María"
[1] "21.96127"
[1] "-102.3434"
[1] "Tormentas dispersas"
[1] "8"
[1] "ID: 7"
[1] "2017-06-27T17:36:43.089Z"
[1] "Aguascalientes"
[1] "Pabellón de Arteaga"
[1] "22.1492"
[1] "-102.2765"
[1] "Tormentas"
[1] "6"
- Identificamos que a través del API, podemos mandar ciertos parámetros dentro de la URL que nos permiten obtener información específica y con base en esto, realizamos una función para pasar los parámetros pageSize y state:
getData <- function (pageSize,state){
URL <- sprintf("https://api.datos.gob.mx/v1/condiciones-atmosfericas?pageSize=%s&stateabbr=%s",pageSize,state)
res <- GET(URL,verbose())
dat <- fromJSON(rawToChar(res$content))
return(dat)
}
Identificamos que cada estado tiene una abreviación específica dentro del glosario. Para fines prácticos y demostrativos, muestro tres ejemplo:
- Quintana Roo = “ROO”
- Yucatán = “YUC”
- Campeche = “CAM”
- Nosotros ahora entonces, podemos pedir específicamente una cantidad específica de los datos y de un estado en específico:
// Siendo 58652 el total para Quintana Roo, hacemos la llamada al a función
data <- getData(58652,"ROO")
- Una vez terminado el proceso, podemos visualizar los datos recolectados como dataframe
df <- as.data.frame(data)
df
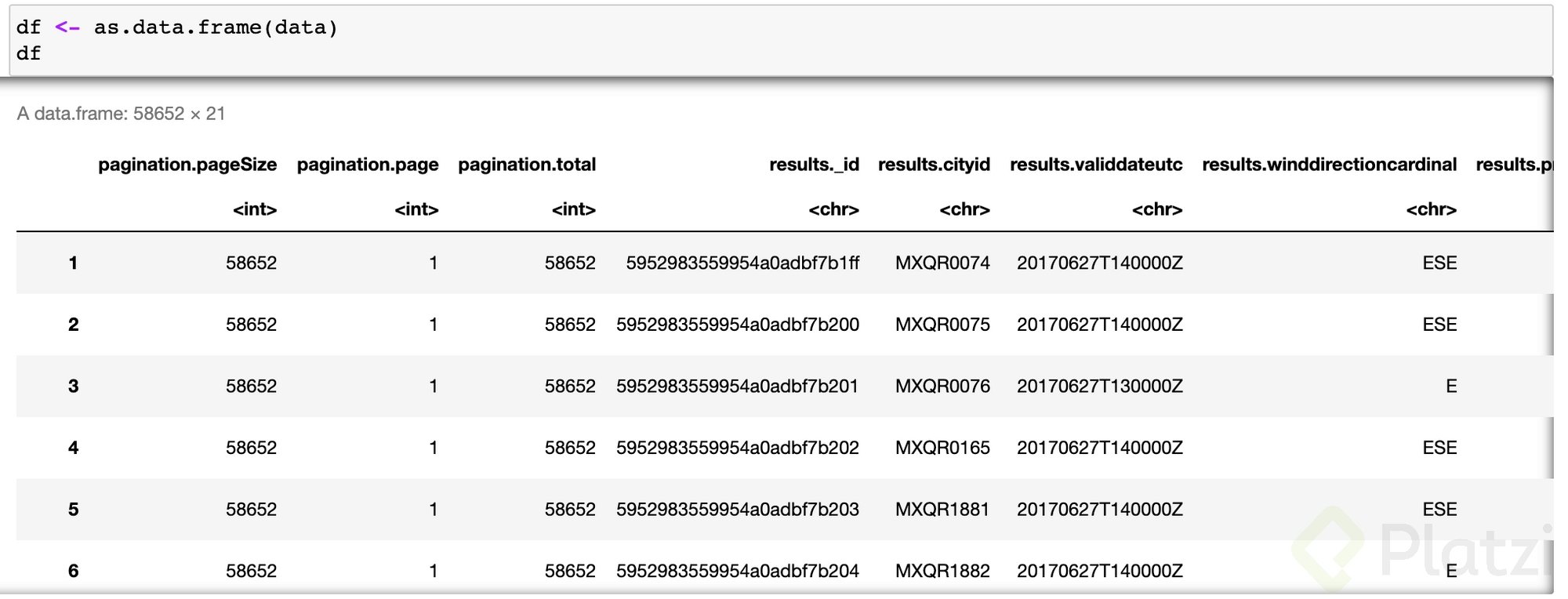
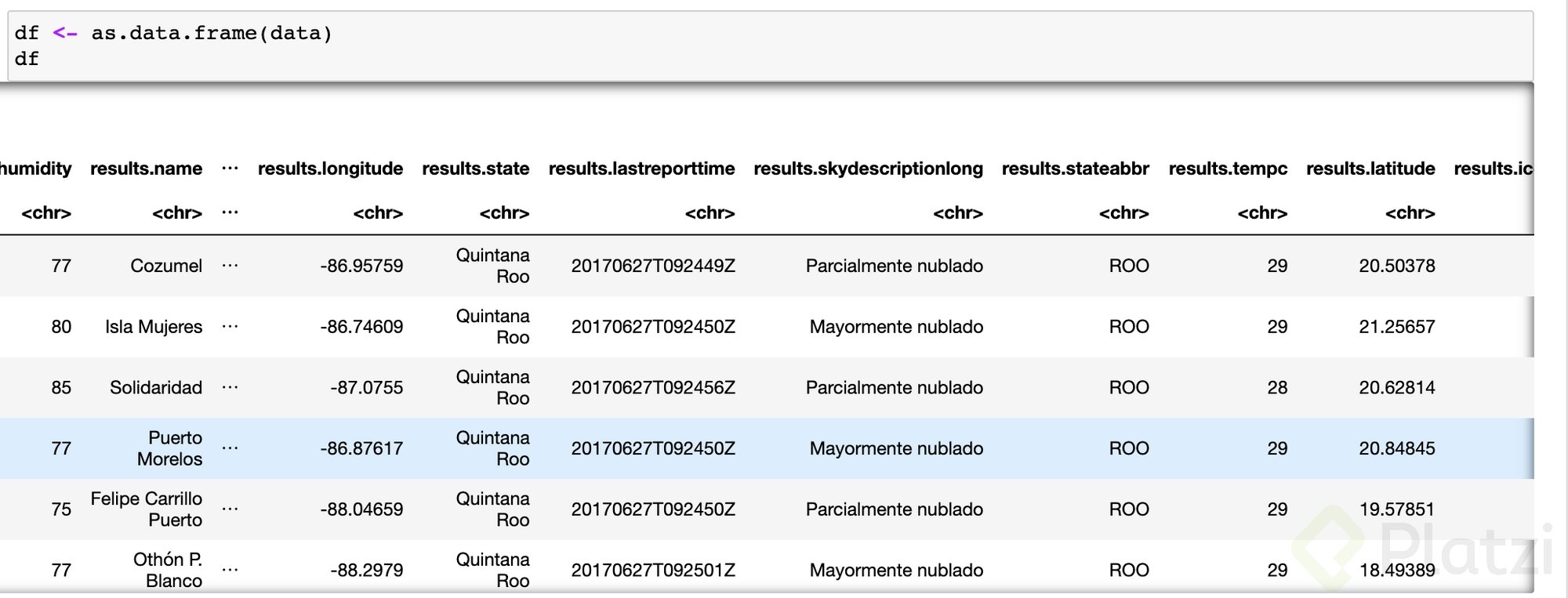
- Al identificar que los nombres de las columnas son algo como results.*, lo ideal es cambiar los nombres y asignar unos como unos solos. Para hacerlo:
names(df)[1] <- "pageSize"
names(df)[2] <- "pageNumber"
names(df)[3] <- "paginationTotal"
names(df)[4] <- "ID"
names(df)[5] <- "city_ID"
names(df)[6] <- "valid_date_utc"
names(df)[7] <- "wind_direction"
names(df)[8] <- "precipitation_prob"
names(df)[9] <- "relative_humidity"
names(df)[10] <- "city_name"
names(df)[11] <- "date_insert"
names(df)[12] <- "long"
names(df)[13] <- "state"
names(df)[14] <- "last_report_time"
names(df)[15] <- "sky_description"
names(df)[16] <- "state_abbr"
names(df)[17] <- "temp_celsius"
names(df)[18] <- "lat"
names(df)[19] <- "iconcode"
names(df)[20] <- "wind_speed"
names(df)[21] <- "city_name_2"
- Comprobamos el nombre de las columnas:
colnames(df)
'pageSize'
'pageNumber'
'paginationTotal'
'ID'
'city_ID'
'valid_date_utc'
'wind_direction'
'precipitation_prob'
'relative_humidity'
'city_name'
'date_insert'
'long'
'state'
'last_report_time'
'sky_description'
'state_abbr'
'temp_celsius'
'lat'
'iconcode'
'wind_speed'
'city_name_2'
- El objeto que tenemos ahora en df, contiene valores que no nos interesan en este momento. Los descartamos y filtramos los datos con ayuda de dplyr y verificamos la estructura**😗*
df <- df %>% select(!(c(ID,pageSize, pageNumber, paginationTotal)))
str(df)
'data.frame': 58652 obs. of 17 variables:
$ city_ID : chr "MXQR0074" "MXQR0075" "MXQR0076" "MXQR0165" ...
$ valid_date_utc : chr "20170627T140000Z" "20170627T140000Z" "20170627T130000Z" "20170627T140000Z" ...
$ wind_direction : chr "ESE" "ESE" "E" "ESE" ...
$ precipitation_prob: chr "20" "0" "20" "10" ...
$ relative_humidity : chr "77" "80" "85" "77" ...
$ city_name : chr "Cozumel" "Isla Mujeres" "Solidaridad" "Puerto Morelos" ...
$ date_insert : chr "2017-06-27T17:36:45.270Z" "2017-06-27T17:36:45.270Z" "2017-06-27T17:36:45.270Z" "2017-06-27T17:36:45.270Z" ...
$ long : chr "-86.95759" "-86.74609" "-87.0755" "-86.87617" ...
$ state : chr "Quintana Roo" "Quintana Roo" "Quintana Roo" "Quintana Roo" ...
$ last_report_time : chr "20170627T092449Z" "20170627T092450Z" "20170627T092456Z" "20170627T092450Z" ...
$ sky_description : chr "Parcialmente nublado" "Mayormente nublado" "Parcialmente nublado" "Mayormente nublado" ...
$ state_abbr : chr "ROO" "ROO" "ROO" "ROO" ...
$ temp_celsius : chr "29" "29" "28" "29" ...
$ lat : chr "20.50378" "21.25657" "20.62814" "20.84845" ...
$ iconcode : chr "66" "69" "66" "69" ...
$ wind_speed : chr "13" "16" "5" "18" ...
$ city_name_2 : chr NA NA NA NA ...
- Teniendo los datos filtrados y con las columnas que son relevantes para nosotros, ahora buscamos un municipio específico para poder analizar los datos:
benito_juarez <- df %>%
filter(city_name == "Benito Juárez" | city_name_2 == "Benito Juárez")
head(benito_juarez)
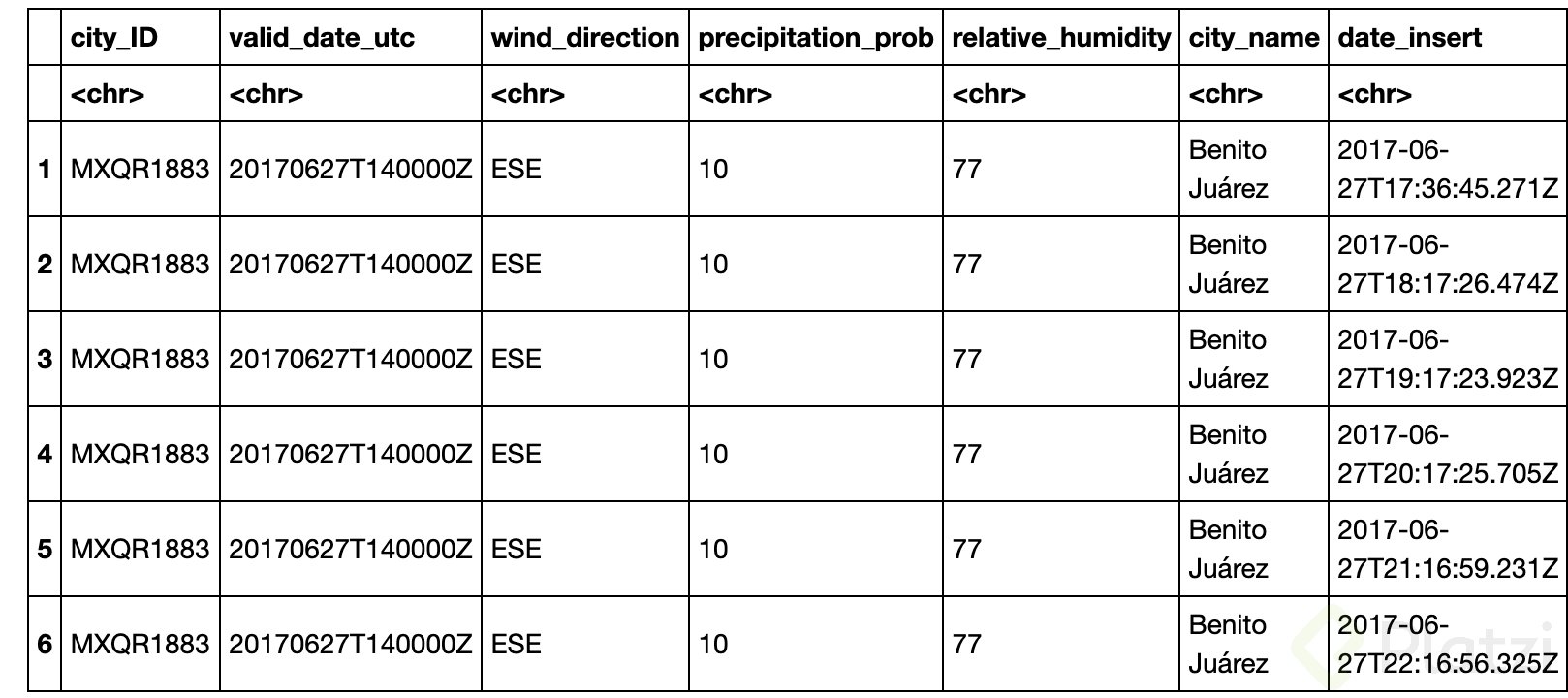
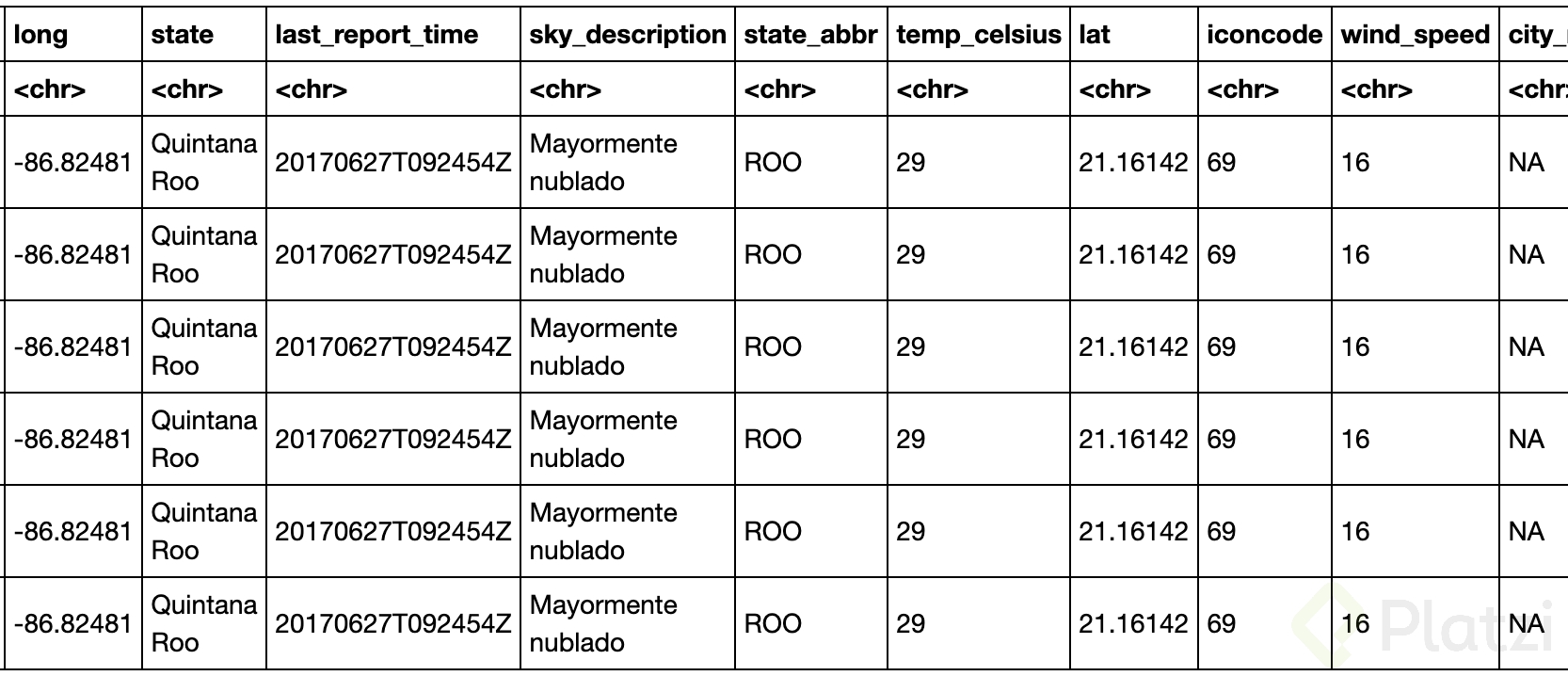
- Ahora que visualizamos el data frame de Benito Juárez (municipio del estado de Quintana Roo), aplicamos algunos cálculos estadísticos simples:
print("Promedio histórico de Humedad en Benito Juárez:")
mean((as.numeric(as.character(df$relative_humidity))))
[1] "Promedio histórico de Humedad en Benito Juárez:"
72.2678169542386
print("Promedio histórico de temperatura celsius en Benito Juárez:")
mean((as.numeric(as.character(df$temp_celsius))))
[1] "Promedio histórico de temperatura celsius en Benito Juárez:"
30.4430198458706
print("Promedio histórico de velocidad del viento en Benito Juárez:")
mean((as.numeric(as.character(df$wind_speed))))
[1] "Promedio histórico de velocidad del viento en Benito Juárez:"
13.1579485780536
Conclusión:
En este artículo vimos lo fácil y rápido que es consumir datos de una API y manipularlos para filtrarlos y conseguir cálculos estadísticos específicos. Sigue el post ¿Qué es GraphQL? Y amplía tus conocimientos sobre el tema.
Para más información o feedback, no duden en mandarme un correo a rafalagunas@platzi.com, espero que les haya gustado y servido.👨🏻💻
Curso de Estadística Inferencial con R
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







