

¡El aprendizaje profundo es casi magia! Para mí es mágico ver una red neuronal haciendo algo creativo, como cuando aprende a crear pinturas tal como lo haría un artista. La tecnología detrás de esto son las Redes generativas antagónicas y aquí analizaremos cómo entrenar dichas redes en Azure Machine Learning Service.
Si ha visto mis publicaciones anteriores sobre Azure ML (acerca de cómo usarlo desde VS Code y cómo enviar experimentos y la optimización de los hiperparámetros), ya debería saber que usar Azure ML es muy conveniente para prácticamente todas las tareas de entrenamiento. Pero todos los ejemplos hechos hasta ahora han sido con el conjunto de datos de MNIST. Hoy nos vamos a centrar en el problema real, que es crear pinturas artificiales como estas:

Flores, 2019, Arte de lo artificial
keragan entrenado en flores de WikiArt

Reina del caos, 2019,
keragan entrenado en retratos de WikiArt
Estas obras se crean después de entrenar la red con pinturas de WikiArt. Si quiere reproducir los mismo resultados, puede que tenga que recopilar usted mismo el conjunto de datos, por ejemplo, con WikiArt Retriever o con colecciones existentes del conjunto de datos de WikiArt o del proyecto GANGogh.
Coloque las imágenes que quiere usar en el entrenamiento en algún lugar del directorio dataset. En el caso del entrenamiento sobre flores, algunas de esas imágenes pueden verse así:
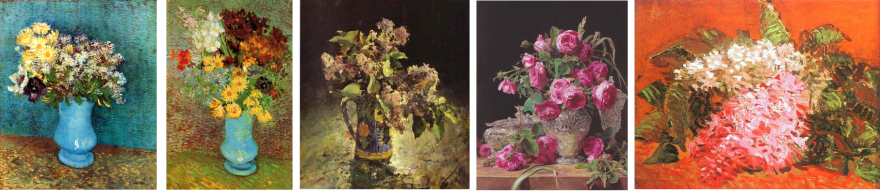
Es necesario que el modelo de red neuronal aprenda tanto la composición de alto nivel de un ramo de flores y un florero como el estilo de bajo nivel del cuadro, con las manchas de pintura y la textura del lienzo.
Redes generativas antagónicas
Las pinturas se generaron con la Red generativa antagónica, GAN. En este ejemplo, usaremos mi implementación sencilla de GAN en Keras denominada keragan y mostraré algunas partes simplificadas de ese código.
 shwars / keragan
shwars / keragan
Implementación de Keras de las GAN
Una GAN consta de dos redes:
- El Generador, que genera imágenes dado algún vector de ruido de entrada.
- El Discriminador, que diferencia entre la pintura real y la pintura “falsa” (generada).

El entrenamiento de la GAN implica estos pasos:
- Obtener muchas imágenes generadas y reales:
noise = np.random.normal(0, 1, (batch_size, latent_dim)) gen_imgs = generator.predict(noise)
imgs = get_batch(batch_size)
- Entrenar el discriminador para que diferencie mejor entre ambas. Tenga en cuenta que al vector se le proporciona
onesyzeroscomo respuesta esperada:
d_loss_r = discriminator.train_on_batch(imgs, ones) d_loss_f = discriminator.train_on_batch(gen_imgs, zeros) d_loss = np.add(d_loss_r , d_loss_f)*0.5
- Entrenar el modelo combinado a fin de mejorar el generador:
g_loss = combined.train_on_batch(noise, ones)
Durante este paso, el discriminador no se entrena porque sus pesos se congelan de manera explícita durante la creación del modelo combinado:
discriminator = create_discriminator()
generator = create_generator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer,
metrics=['accuracy'])
discriminator.trainable = False
z = keras.models.Input(shape=(latent_dim,))
img = generator(z)
valid = discriminator(img)
combined = keras.models.Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
Modelo de discriminador
Para diferenciar entre la imagen real y la imagen falsa, usamos la arquitectura de Red neuronal convolucional (CNN) tradicional. De este modo, para la imagen con un tamaño de 64 x 64, tendremos algo como esto:
discriminator = Sequential()
for x in [16,32,64]: # number of filters on next layer
discriminator.add(Conv2D(x, (3,3), strides=1, padding="same"))
discriminator.add(AveragePooling2D())
discriminator.addBatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
Tenemos 3 capas de convolución que hacen lo siguiente:
- La imagen original de forma de 64 x 64 x 3 se pasa por 16 filtros, lo que genera una forma de 32 x 32 x 16. Para disminuir el tamaño, se usa
AveragePooling2D. - El próximo paso convierte el tensor de 32 x 32 x 16 en un tensor de 16 x 16 x 32.
- Por último, después de la capa de convolución siguiente, tenemos un tensor de forma de 8 x 8 x 64.
Además de esta base convolucional, colocamos un clasificador de regresión logística sencillo (que también se conoce como capa densa de 1 neurona).
Modelo de generador
El modelo de generador es algo más complicado. En primer lugar, imagina que queremos convertir una imagen en algún tipo de vector de características de longitud latent_dim=100. Usaríamos un modelo de red convolucional similar al modelo de discriminador anterior, pero la capa final sería una capa densa de tamaño 100.
El generador hace lo contrario: convierte el vector de tamaño 100 en una imagen. Esto implica un proceso denominado deconvolución que es, en esencia, una convolución invertida. Junto con UpSampling2D, hacen que el tamaño del tensor aumente en cada capa:
generator = Sequential()
generator.add(Dense(8 * 8 * 2 * size, activation="relu",
input_dim=latent_dim))
generator.add(Reshape((8, 8, 2 * size)))
for x in [64;32;16]:
generator.add(UpSampling2D())
generator.add(Conv2D(x, kernel_size=(3,3),strides=1,padding="same"))
generator.add(BatchNormalization(momentum=0.8))
generator.add(Activation("relu"))
generator.add(Conv2D(3, kernel_size=3, padding="same"))
generator.add(Activation("tanh"))
En el último paso, terminamos con un tamaño de tensor de 64 x 64 x 3, que es exactamente el tamaño de la imagen que necesitamos.
Observe que la función de activación final es tanh, que genera un resultado en el intervalo de [-1;1], lo que significa que es necesario escalar las imágenes de entrenamiento originales a este intervalo. Todos los pasos para preparar las imágenes los controla la clase ImageDataset, pero no entraré en esos detalles.
Script de entrenamiento de Azure ML
Ahora que tenemos todos los elementos para entrenar juntos la GAN, estamos preparados para ejecutar este código en Azure ML como un experimento. El código que voy a mostrar aquí está disponible en GitHub:
CloudAdvocacy / AzureMLStarter
Este es un tutorial para que pueda empezar a usar Azure ML Service
Pero hay que tener en cuenta algo importante: por lo general, cuando ejecutamos un experimento en Azure ML, queremos hacer el seguimiento de ciertas métricas, como la precisión o las pérdidas. Podemos registrar esos valores durante el entrenamiento con run.log, tal como lo describí en la publicación anterior, y ver cómo cambia esta métrica durante el entrenamiento en el portal de Azure ML.
En este caso, en lugar de la métrica numérica, nos interesan las imágenes visuales que la red genera en cada paso. Revisar esas imágenes mientras se ejecuta el experimento nos puede ayudar a decidir si queremos terminar el experimento, modificar los parámetros o seguir adelante.
Azure ML permite registrar imágenes además de números, tal como se describe aquí. Podemos registrar imágenes representadas como matrices np o cualquier trazado generado por matplotlib, así es que lo que haremos será trazar tres imágenes de ejemplo en un trazado. Este trazado se controlará en la función de devolución de llamada callbk que keragan llama después de cada época de entrenamiento:
def callbk(tr):
if tr.gan.epoch % 20 == 0:
res = tr.gan.sample_images(n=3)
fig,ax = plt.subplots(1,len(res))
for i,v in enumerate(res):
ax[i].imshow(v[0])
run.log_image("Sample",plot=plt)
Por lo tanto, el código de entrenamiento real se verá así:
gan = keragan.DCGAN(args)
imsrc = keragan.ImageDataset(args)
imsrc.load()
train = keragan.GANTrainer(image_dataset=imsrc,gan=gan,args=args)
train.train(callbk)
Observe que keragan admite el análisis automático de muchos parámetros de la línea de comandos que se pueden pasar a través de la estructura args. Esto es lo que hace que este código sea tan sencillo.
Inicio del experimento
Para enviar el experimento a Azure ML, usaremos un código similar al que se analizó en la publicación anterior sobre Azure ML. El código se encuentra dentro de [submit_gan.ipynb][https://github.com/CloudAdvocacy/AzureMLStarter/blob/master/submit_gan.ipynb] y empieza con pasos conocidos:
- Conexión con el área de trabajo mediante
ws = Workspace.from_config(). - Conexión con el clúster de proceso:
cluster = ComputeTarget(workspace=ws, name='My Cluster'). Se necesita un clúster de VM que disponen de GPU, como NC6. - Carga del conjunto de datos al almacén de datos predeterminado en el área de trabajo de ML.
Una vez hecho esto, es posible enviar el experimento a través del código siguiente:
exp = Experiment(workspace=ws, name='KeraGAN')
script_params = {
'--path': ws.get_default_datastore(),
'--dataset' : 'faces',
'--model_path' : './outputs/models',
'--samples_path' : './outputs/samples',
'--batch_size' : 32,
'--size' : 512,
'--learning_rate': 0.0001,
'--epochs' : 10000
}
est = TensorFlow(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_gan.py',
use_gpu = True,
conda_packages=['keras','tensorflow','opencv','tqdm','matplotlib'],
pip_packages=['git+https://github.com/shwars/keragan@v0.0.1']
run = exp.submit(est)
En este caso, pasamos model_path=./outputs/models y samples_path=./outputs/samples como parámetros, lo que hará que los modelos y ejemplos generados durante el entrenamiento se escriban en los directorios correspondientes dentro del experimento de Azure ML. Esos archivos estarán disponibles en el portal de Azure ML y también se pueden descargar mediante programación más adelante (o incluso durante el entrenamiento).
Para crear el estimador que se puede ejecutar sin problemas en la GPU, usamos el estimador Tensorflow integrado. Es muy similar al Estimator genérico, pero proporciona también opciones inmediatas para el entrenamiento distribuido. Para más información sobre el uso de los distintos estimadores, lea la documentación oficial.
Otro punto interesante aquí es cómo se instala la biblioteca keragan, directamente desde GitHub. Si bien también se puede instalar desde el repositorio de PyPI, quise demostrar que también se permite la instalación directa desde GitHub e incluso es posible indicar una versión específica del id. de confirmación, la etiqueta o la biblioteca.
Después de que el experimento se ha ejecutado durante un tiempo, deberíamos poder observar las imágenes de ejemplo que se generan en el portal de Azure ML:
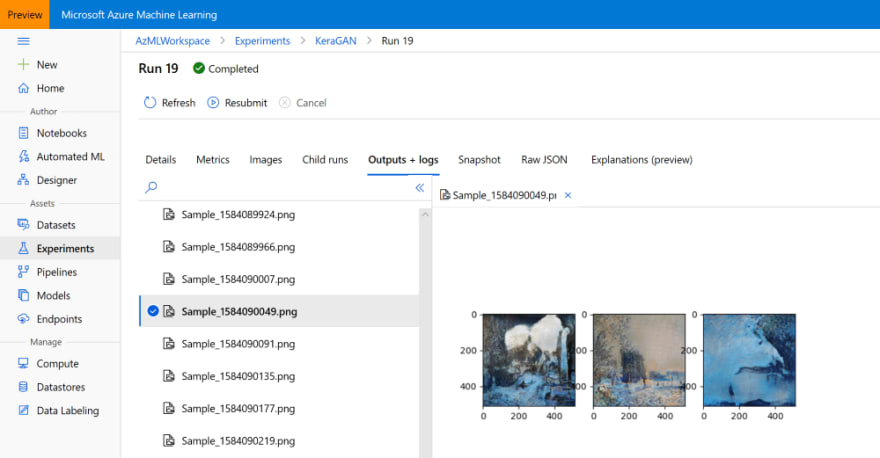
Ejecución de muchos experimentos
La primera vez que ejecutamos el entrenamiento de la GAN, es posible que no obtengamos los mejores resultados por varias razones. En primer lugar, la velocidad de aprendizaje parece ser un parámetro importante y una velocidad de aprendizaje demasiado alta podría generar resultados insuficientes. Por lo tanto, necesitamos realizar varios experimentos para obtener los mejores resultados.
Estos son los parámetros que quizás queramos cambiar:
--sizedetermina el tamaño de la imagen, que debe ser una potencia de 2. Los tamaños pequeños como 64 o 128 permiten realizar una experimentación rápida, mientras que los tamaños grandes (hasta 1024) son ideales para crear imágenes de mayor calidad. Ningún tamaño superior a 1024 dará buenos resultados, porque se requieren técnicas especiales para entrenar las redes GAN de resoluciones grandes, como el crecimiento progresivo.--learning_ratees, sorprendentemente, un parámetro muy importante, especialmente con resoluciones más altas. Por lo general, una velocidad de aprendizaje baja genera mejores resultados, pero el entrenamiento se produce muy lentamente.--dateset. Puede que queramos cargar imágenes de distintos estilos a carpetas diferentes del almacén de datos de Azure ML y empezar a entrenar varios experimentos de manera simultánea.
Como ya sabemos cómo enviar el experimento mediante programación, debería ser fácil encapsular ese código en un par de bucles for- para realizar algún barrido paramétrico. Luego puede comprobar manualmente en el portal de Azure ML cuáles de los experimentos están por conseguir buenos resultados y terminar todos los demás experimentos para así ahorrar costos. Tener un clúster de algunas máquinas virtuales permite iniciar unos pocos experimentos al mismo tiempo sin tener que esperar.
Obtención de los resultados del experimento
Una vez que esté satisfecho con los resultados, tiene lógica obtener los resultados del entrenamiento en forma de archivos de modelo e imágenes de ejemplo. Ya indiqué que, durante el entrenamiento, el script de entrenamiento almacenó los modelos en el directorio outputs/models y las imágenes de ejemplo, en outputs/samples. Examine esos directorios en el portal de Azure ML y descargue manualmente los archivos que quiera:
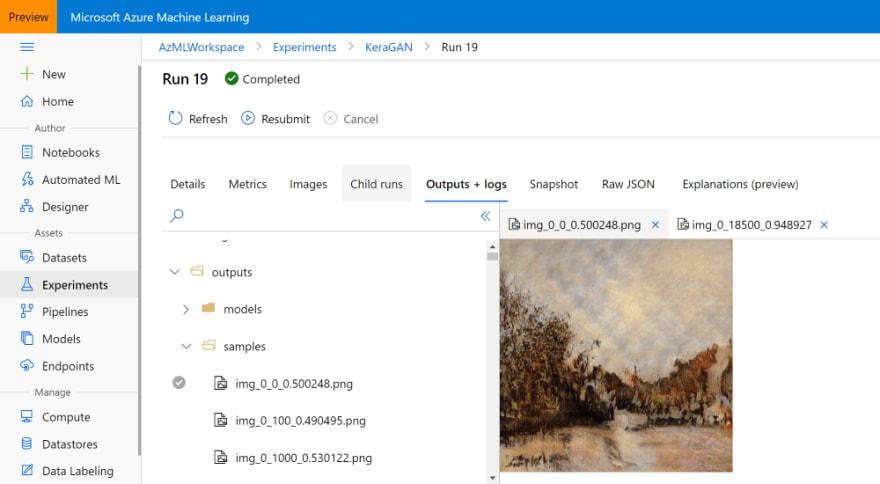
También puede hacerlo mediante programación, sobre todo si quiere descargar todas las imágenes generadas durante distintas épocas de entrenamiento. El objeto run que obtuvo durante el envío del experimento le permite acceder a todos los archivos almacenados como parte de esa ejecución y puede descargarlos de esta manera:
run.download_files(prefix='outputs/samples')
Esto creará el directorio outputs/samples dentro del directorio actual y descargará todos los archivos del directorio remoto con el mismo nombre.
Si perdió la referencia a la ejecución específica dentro de su cuaderno (lo que puede ocurrir, porque la mayoría de los experimentos son de larga duración), siempre puede crearla si conoce el id. de la ejecución, que puede buscar en el portal:
run = Run(experiment=exp,run_id='KeraGAN_1584082108_356cf603')
También podemos obtener los modelos entrenados. Por ejemplo, vamos a descargar el modelo de generador final y a usarlo para generar una gran cantidad de imágenes aleatorias. Podemos obtener todos los nombres de archivo asociados al experimento y filtrar solo los que representan modelos de generador:
fnames = run.get_file_names()
fnames = filter(lambda x : x.startswith('outputs/models/gen_'),fnames)
Todos se verán como outputs/models/gen_0.h5, outputs/models/gen_100.h5, etc. Necesitamos conocer el número máximo de época:
no = max(map(lambda x: int(x[19:x.find('.')]), fnames))
fname = 'outputs/models/gen_{}.h5'.format(no)
fname_wout_path = fname[fname.rfind('/')+1:]
run.download_file(fname)
Esto descargará en el directorio local el archivo con el número de época más alto y también almacenará el nombre de este archivo (sin la ruta de acceso al directorio) en fname_wout_path.
Generación de imágenes nuevas
Una vez que obtenemos el modelo, solo necesitamos cargarlo en Keras, averiguar el tamaño de la entrada y dar el vector aleatorio con el tamaño correcto como la entrada para crear una pintura aleatoria nueva generada por la red:
model = keras.models.load_model(fname_wout_path)
latent_dim=model.layers[0].input.shape[1].value
res = model.predict(np.random.normal(0,1,(10,latent_dim)))
El resultado de la red de generador está en el intervalo [-1,1], por lo que es necesario escalarlo de manera lineal con el intervalo [0,1] para que matplotlib lo muestre correctamente:
res = (res+1.0)/2
fig,ax = plt.subplots(1,10,figsize=(15,10))
for i in range(10):
ax[i].imshow(res[i])
Este es el resultado que se va a obtener:

Eche un vistazo a algunas de las mejores pinturas que surgieron de este experimento:


Primavera colorida, 2020
Paisaje rural, 2020


A través del vidrio congelado, 2020
Paisaje de verano, 2020
Suscríbase a la cuenta de Instagram @art_of_artificial. Trato de publicar pinturas que genera la GAN de manera periódica.
Observación del proceso de aprendizaje
También es interesante observar cómo la red GAN aprende de manera gradual. Exploré esta noción de aprendizaje en mi exposición Art of the Artificial. A continuación, un par de vídeos que muestran este proceso:
Ideas para reflexionar
En esta publicación, describí el funcionamiento de la red GAN y cómo entrenarla con Azure ML. Esto abre definitivamente un enorme espacio para la experimentación, pero también un espacio enorme para reflexionar. Durante este experimento creamos obras de arte originales generadas por la inteligencia artificial. Pero… ¿se pueden considerar ARTE? Lo explicaré en una de mis siguientes publicaciones…
Agradecimientos
Al producir la biblioteca de keragan, me inspiré en gran medida en este artículo y también en el artículo sobre la implementación de la DCGAN de Maxime Ellerbach y, en parte, en el proyecto GANGogh. Aquí se presentan muchas arquitecturas de GAN distintas implementadas en Keras.
Curso de Inteligencia Artificial con IBM Watson






