

Somos muchos los científicos de datos —yo el primero— que hacemos la mayor parte de nuestro trabajo en una máquina habilitada para GPU, ya sea localmente o en la nube, a través de instancias de Jupyter Notebook o algo de IDE de Python. Eso fue exactamente lo que hice durante los dos años que trabajé como ingeniero de software de AI/ML; esto es, preparar los datos en un equipo sin GPU y, después, usar la máquina virtual de GPU en la nube para llevar a cabo el entrenamiento.
Por otro lado, es probable que haya oído hablar de Azure Machine Learning: un servicio de plataforma especial para las tareas de ML. Sin embargo, si empieza a ver algunos tutoriales de introducción, tendrá la impresión de que el uso de Azure ML crea una sobrecarga innecesaria y el proceso no resulta idóneo. Por ejemplo, el script de entrenamiento en el ejemplo anterior se crea como un archivo de texto en una celda de Jupyter, sin la finalización del código, o sin una manera cómoda de ejecutarlo localmente o depurarlo. Esta sobrecarga adicional fue la razón por la que no lo usamos en nuestros proyectos.
Sin embargo, hace poco hemos constatado que existe una extensión de Visual Studio Code para Azure ML. Con esta extensión, puede desarrollar el código de entrenamiento directamente en VS Code, ejecutarlo localmente y, a continuación, enviar el mismo código para entrenarlo en un clúster con tan solo unos clics. Este método ofrece varias ventajas importantes:
- Puede pasar la mayor parte del tiempo localmente en la máquina y usar los eficaces recursos de GPU solo para el entrenamiento. Se puede cambiar el tamaño del clúster de entrenamiento automáticamente a petición, y al establecer la cantidad mínima de máquinas en 0 puede poner en marcha la máquina virtual cuando lo requiera.
- Conserva todos los resultados del entrenamiento, incluidas las métricas y los modelos creados, en una ubicación central, sin necesidad de mantener el registro de la precisión de cada experimento de forma manual.
- Si varias personas trabajan en el mismo proyecto, pueden usar el mismo clúster (todos los experimentos se pondrán en cola) y pueden ver el resultado de los experimentos de los demás. Por ejemplo, puede usar Azure ML en un entorno de aula y, en lugar de dar a cada alumno una máquina GPU individual, puede crear un clúster que sirva a todos y fomentar la competición entre estudiantes sobre la precisión del modelo.
- Si necesita realizar muchos entrenamientos (por ejemplo, para la optimización de hiperparámetros), todo se puede hacer con solo unos pocos comandos, sin necesidad de ejecutar la serie de experimentos de forma manual.
Espero haberle convencido para probar Azure ML personalmente. Esta es la mejor manera de empezar:
- Instale las extensiones Visual Studio Code, Azure Sign In y Azure ML.
- Clone el repositorio https://github.com/CloudAdvocacy/AzureMLStarter: contiene código de ejemplo para entrenar el modelo a fin de que reconozca los dígitos MNIST. Después, puede abrir el repositorio clonado en VS Code.
- ¡Siga leyendo!
Área de trabajo de ML y portal
En Azure ML, todo se organiza en torno a un área de trabajo. Este es un punto central en el que se envían los experimentos y se almacenan los datos y los modelos resultantes. También hay un portal de Azure ML especial que proporciona la interfaz web para el área de trabajo y permite realizar diferentes operaciones, supervisar los experimentos y métricas, etc.
Puede crear un área de trabajo a través de la interfaz web de Azure Portal (vea las instrucciones paso a paso) o con la CLI de Azure (instrucciones):
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazml
El área de trabajo contiene algunos recursos de proceso. Una vez que tenga un script de entrenamiento, puede enviar el experimento al área de trabajo y especificar un destino de proceso: podrá estar seguro de que el experimento se ejecuta ahí y almacena todos los resultados del experimento en el área de trabajo para futuras referencias.
Script de aprendizaje de MNIST
En nuestro ejemplo, veremos cómo resolver el problema tradicional de reconocimiento de dígitos manuscritos mediante el conjunto de datos de MNIST. Del mismo modo, podrá ejecutar cualquier otro script de entrenamiento.
Nuestro repositorio de ejemplo contiene un sencillo de script de entrenamiento de MNIST train_local.py. Este script descarga el conjunto de datos de MNIST de OpenML y, a continuación, usa LogisticRegression de SKLearn para entrenar el modelo e imprimir la precisión resultante:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)
Por supuesto, usamos la regresión logística solo con fines de ilustración, esto no implica que sea una buena manera de solucionar el problema…
Ejecución del script en Azure ML
Puede simplemente ejecutar este script localmente y ver el resultado. Sin embargo, el uso de Azure ML nos brinda dos ventajas principales:
- La programación y ejecución del entrenamiento en un recurso de proceso centralizado, que suele ser más eficaz que un equipo local. Azure ML se encargará de empaquetar el script en un contenedor de Docker con la configuración adecuada.
- Registro de los resultados del entrenamiento en una ubicación centralizada dentro del área de trabajo de Azure ML. Para ello, es necesario agregar las siguientes líneas de código a nuestro script para registrar las métricas:
from azureml.core.run import Run ... try:
run = Run.get_submitted_run() run.log('accuracy', acc) except: pass
La versión modificada del script se denomina train_universal.py (es un poco más complicada que el código presentado anteriormente) y se puede ejecutar tanto localmente (sin Azure ML) como en un recurso de proceso remoto.
Para ejecutarla en Azure ML desde VS Code, siga estos pasos:
-
Asegúrese de que la extensión de Azure está conectada a su cuenta en la nube. Seleccione el icono de Azure en el menú de la izquierda. Si no está conectado, verá una notificación en la parte inferior derecha que le ofrece la posibilidad de conectarse (consulte la imagen). Haga clic en ella e inicie sesión a través del explorador. También puede presionar Ctrl-Mayús-P para mostrar la paleta de comandos y escribir Azure Sign In.
-
Después, debería poder ver el área de trabajo en la sección MACHINE LEARNING de la barra de Azure:

Aquí debería ver objetos diferentes dentro del área de trabajo: recursos de proceso, experimentos, etc. -
Vuelva a la lista de archivos y haga clic con el botón derecho en
train_universal.pyy seleccione Azure ML: Run as experiment in Azure (Ejecutar como experimento en Azure).
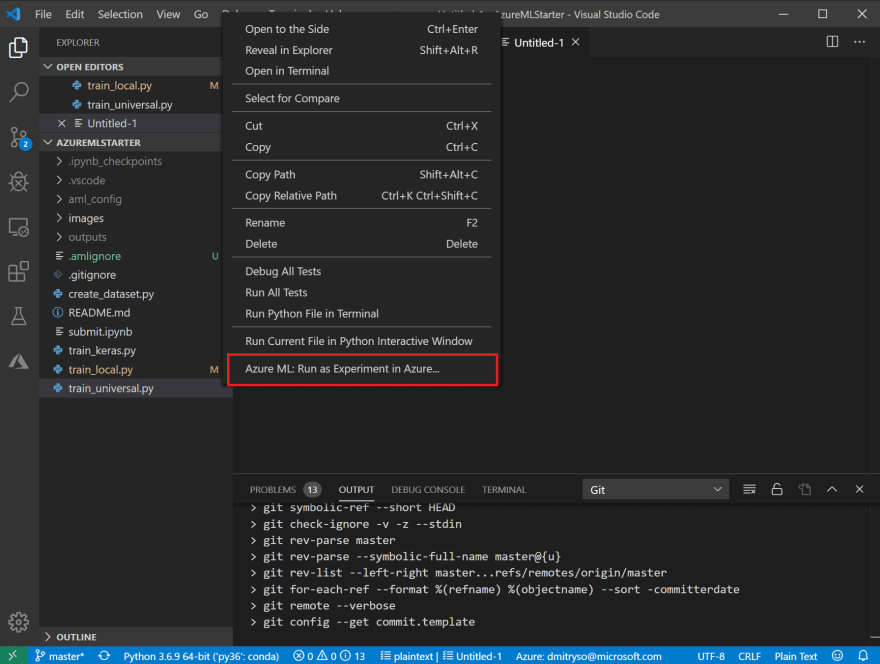
-
Confirme su suscripción de Azure y el área de trabajo y, a continuación, seleccione Create new experiment (Crear un nuevo experimento):



-
Cree un nuevo proceso y una configuración de proceso:
- Un proceso es un recurso informático que se usa para entrenamiento/inferencia. Puede usar el equipo local o cualquier recurso en la nube. En nuestro caso, usaremos el clúster de AmlCompute. Cree un clúster escalable de máquinas STANDARD_DS3_v2, con un mínimo de 0 nodos y un máximo de 4 nodos. Puede hacerlo desde la interfaz de VS Code interfaz o desde el portal de ML.

- La configuración de proceso define las opciones de los contenedores que se crean para realizar el entrenamiento en un recurso remoto. En concreto, especifica todas las bibliotecas que deben instalarse. En nuestro caso, seleccione _SkLearn_y confirme la lista de bibliotecas.


- Un proceso es un recurso informático que se usa para entrenamiento/inferencia. Puede usar el equipo local o cualquier recurso en la nube. En nuestro caso, usaremos el clúster de AmlCompute. Cree un clúster escalable de máquinas STANDARD_DS3_v2, con un mínimo de 0 nodos y un máximo de 4 nodos. Puede hacerlo desde la interfaz de VS Code interfaz o desde el portal de ML.
-
Verá una ventana con la descripción de JSON del siguiente experimento. Ahí puede editar la información; por ejemplo, cambiar el nombre del experimento o del clúster y ajustar algunos parámetros. Cuando esté listo, haga clic en Submit Experiment (Enviar experimento):

-
Una vez que el experimento se haya enviado correctamente en VS Code, aparecerá el vínculo a la página del portal de Azure ML con el progreso y los resultados del experimento.
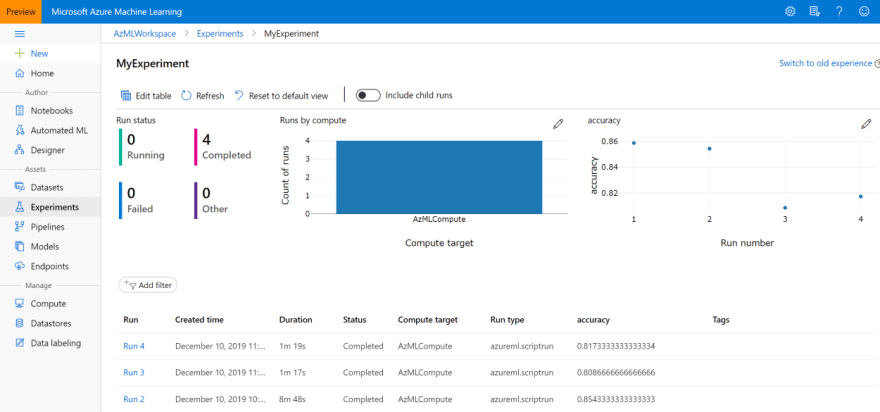
También puede buscar el experimento en la pestaña Experimentos del portal de Azure ML, o bien desde la barra Azure Machine Learning de VS Code:
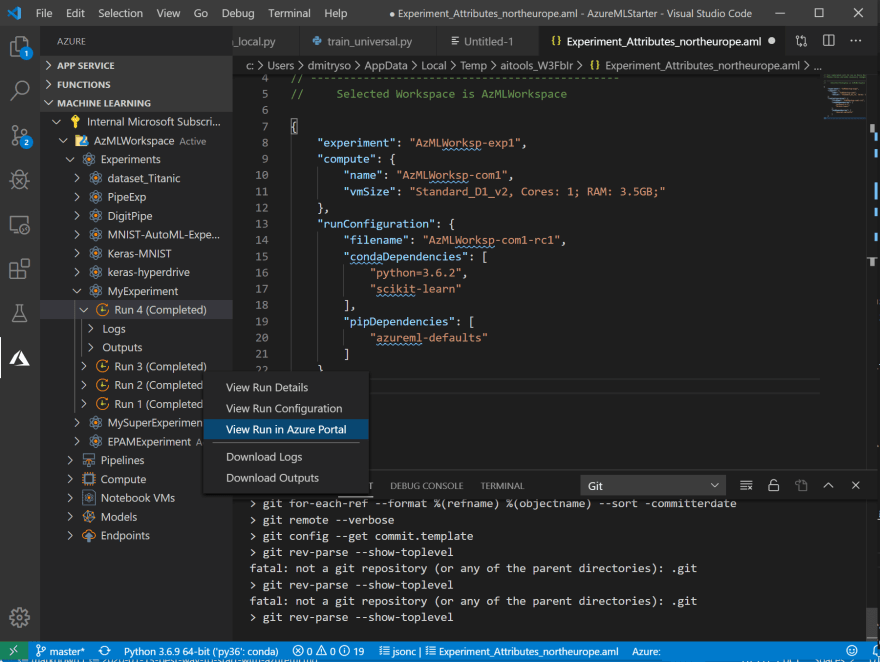
-
Si desea volver a ejecutar el experimento después de ajustar algunos parámetros en el código, este proceso sería mucho más rápido y sencillo. Al hacer clic con el botón derecho en el archivo de entrenamiento, verá una nueva opción de menú Repetir la última ejecución; basta con seleccionarla y el experimento se enviará de inmediato.
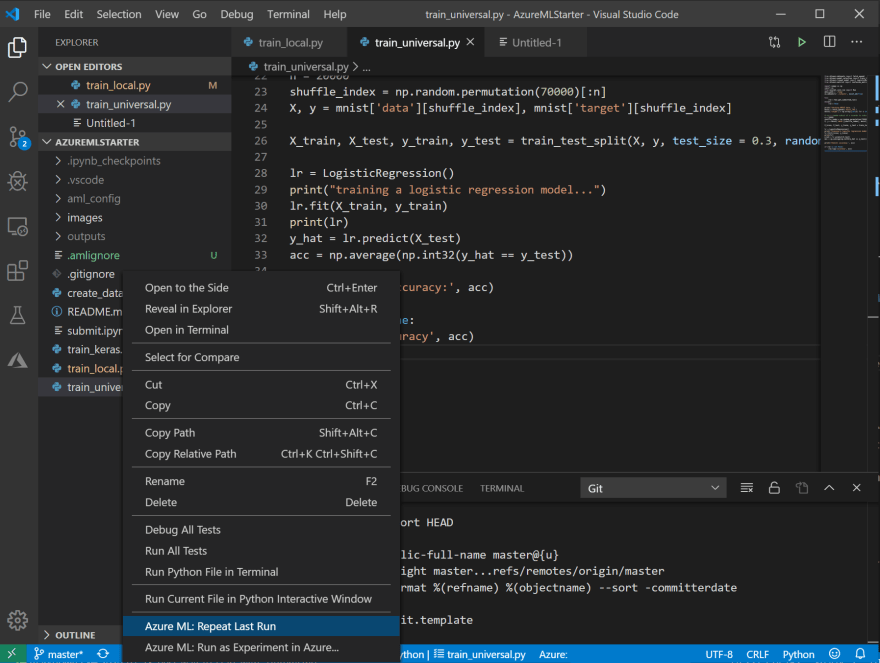
A continuación, verá los resultados de las métricas de todas las ejecuciones en el portal de Azure ML, como se muestra en la captura de pantalla anterior.
Ya ha visto que el envío de ejecuciones a Azure ML no es complicado, y puede disfrutar de algunas ventajas (como el almacenamiento de todas las estadísticas de las ejecuciones, modelos, etc.) de forma gratuita.
Es posible que haya observado que en nuestro caso el tiempo que tarda el script en ejecutarse en el clúster es superior a la ejecución local; puede tardar incluso varios minutos. Por supuesto, se produce cierta sobrecarga en el empaquetado del script y todo el entorno de un contenedor y su envío a la nube. Si el clúster está configurado para reducir verticalmente a 0 nodos, puede haber una sobrecarga adicional debido al inicio de la máquina virtual, y todo eso se nota cuando tiene un pequeño script de ejemplo que en otra situación tardaría unos segundos en ejecutarse. Sin embargo, en escenarios de la vida real, cuando el entrenamiento tarda decenas de minutos y, en ocasiones, mucho más, esta sobrecarga se vuelve apenas importante, especialmente dadas las mejoras de velocidad que puede obtener previsiblemente del clúster.
Pasos adicionales
Ahora que sabe cómo enviar scripts para su ejecución en un clúster remoto, puede empezar a aprovechar las ventajas de Azure ML en su trabajo cotidiano. Por ejemplo, podrá desarrollar scripts en un equipo normal y, a continuación, programarlos para su ejecución en máquinas virtuales o clústeres de GPU automáticamente, manteniendo todos los resultados en un solo lugar.
Sin embargo, los beneficios de usar Azure ML no son solo esos dos. Azure ML también se puede usar para el almacenamiento de datos y la administración de conjuntos de datos, lo que permite que los distintos scripts de entrenamiento tengan acceso a los mismos datos. Además, puede enviar experimentos automáticamente a través de la API, modificando los parámetros (y, por tanto, realizando alguna optimización de hiperparámetros). Además, hay una tecnología específica integrada en Azure ML denominada Hyperdrive, que realiza una búsqueda de hiperparámetros más inteligente. Hablaré más sobre esas características y tecnologías en mis próximas publicaciones.
Fundamentos de IBM Cloud
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


