¿Podrá la inteligencia artificial alcanzar la humana algún día?
Con frecuencia en las películas de ciencia ficción vemos sociedades futuristas donde las máquinas y los seres humanos conviven a tal punto de que a veces es difícil diferenciar entre uno y otro. Un ejemplo de esto lo vemos en la saga de culto Blade Runner, la cual nos presenta un futuro distópico donde existen los replicadores, los cuales son una especie de humanoides diseñados artificialmente para emular la apariencia física de los humanos pero con atributos físicos superiores (como fuerza y velocidad) aunque con una cierta ausencia de respuesta emocional. En este mundo ficticio, la única manera de identificar si un individuo es un humano natural o un replicador es mediante un test muy específico llamado el test de Voight-Kampf, el cual tiene la intención de probar la capacidad de reacción emocional del individuo y determinar si es o no un replicador.
En la serie de culto Blade Runner una de las protagonistas Rachael Tyrell, es un prototipo especial de replicador (Nexus-7) al cual se le implantaron artificialmente recuerdos de una persona humana, haciéndola mucho más parecida a los humanos naturales._
Este ejemplo nos lleva a cuestionarnos si existe alguna manera de determinar si una máquina posee un grado de inteligencia comparable o superior al humano, ¿Tenemos en el mundo real tests similares para evaluar el grado de inteligencia de las máquinas hoy en díaa?
El Test de Turing
En los años 1950s, Alan Turing, sugirió una prueba cuyo objetivo era identificar si una máquina programada de cierta manera podía considerarse inteligente al nivel de un humano. Es básicamente un juego de imitación, donde hay tres individuos: un interrogador, un humano y una máquina con la capacidad de comunicarse con humanos de forma fluida en nuestro lenguaje natural. Los tres individuos están separados en cuartos de manera que no es posible ver quién es quién y el interrogador solo puede comunicarse con los otros dos individuos por medio de una interfaz virtual de conversación (digamos un Messenger o WhatsApp).
> … La idea básica de Turing para esta prueba dice que si el interrogador no puede diferenciar entre el humano y la maquina basado en las conversaciones, entonces esto implica que la máquina tiene un nivel de inteligencia similar al humano …
Esto condujo a una escuela de pensamiento que prevalece hasta el dia de hoy, donde se considera que la capacidad de una maquina para procesar y comunicar nuestro lenguaje natural debe de alguna manera reflejar el nivel de inteligencia de la misma. En ese sentido, tenemos otras películas que exploran el impacto de la inteligencia artificial, entre las cuales, Ex-Machina que es una producción de Netflix, ejemplifica muy bien el test de Turing, Her que nos recuerda el peligro de enamorarse de una interfaz de lenguaje natural y el Hombre bicentenario nos cuenta la vida de un robot que luego de muchas mejoras termina luciendo igual que un ser humano, se enamora y envejece con su pareja humana.

Ahora, dejando un poco de lado la ciencia ficción, la verdad es que hoy en día existe una área de investigación dedicada exclusivamente al estudio de las interacciones entre máquinas y humanos usando lenguaje natural (de aquí en adelante entenderemos por lenguaje natural, el lenguaje que usamos las personas para comunicarnos a diario, ya sea oral o escrito).
A esta área de investigación se le asocia el termino: Natural Language Processing (NLP) o Procesamiento de Lenguaje Natural. Y aun más interesante es saber que dentro de esta área existe un campo de trabajo mucho más específico que denominamos Natural Language Understanding (NLU) o Comprensión de lenguaje natural y hace referencia al estudio de tareas específicas que debería poder ejecutar un algoritmo para demostrar que tiene la capacidad de entender el lenguaje natural y no solo de procesarlo.
¿Cuales son los usos del NLP en la industria de hoy en día?
Aunque no te des cuenta, hoy en día el NLP tiene un impacto directo en muchas situaciones de nuestras vidas, te cuento de algunos ejemplos …
-
El motor de búsqueda de Google recientemente incluyo su modelo de Deep Learning más sofisticado (BERT) para interpretar correctamente tu termino de búsqueda y ofrecerte los resultados que deberían ser más relevantes.
-
Herramientas de traducción entre idiomas, como Google Translate, usan algoritmos de NLP para automatizar el proceso.
-
La mayoría de chatbots que existen en las diferentes plataformas online para servicios de atención al usuario usan algoritmos de NLP para poder sostener cierto nivel de conversaciones.
-
Las herramientas que permiten generar subtítulos en un video están basadas en técnicas de procesamiento de habla y conversión a lenguaje natural por medio del uso de Deep Learning (si es la primera vez que escuchas este termino te recomiendo leer este blog).
Ahora, la realidad es que construir algoritmos de NLP en general resulta muy difícil, especialmente si queremos apuntar a desarrollar NLU. La razón de esto radica en el hecho de que nuestro lenguaje natural es muy complicado y ambiguo y en repetidas ocasiones requiere tener conocimiento de un amplio contexto para poder entender el mensaje que se quiere transmitir.
Porque es tan difícil hacer NLP ?
Las imágenes que verás en la parte inferior nos recuerdan lo ambiguo y confuso que puede llegar a ser nuestro lenguaje incluso para nosotros mismos:
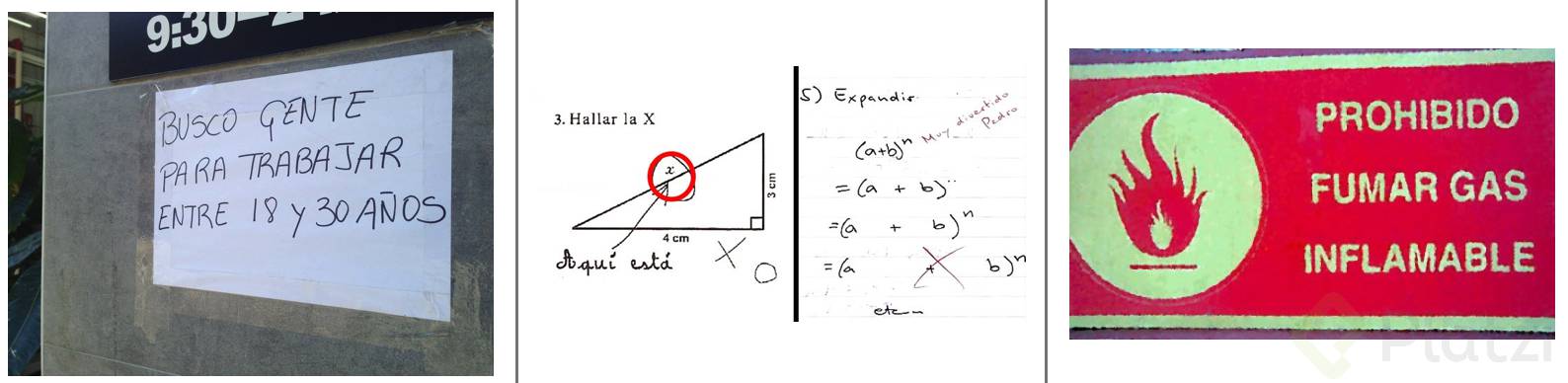
La manera como nos comunicamos, el lenguaje que usamos, es ambiguo, difuso y requiere mucho contexto. Por ejemplo: la imagen de la izquierda nos da a entender que se está buscando una persona con una edad entre 18 y 30 años para trabajar, pero una interpretación literal y sin contexto de la misma frase nos puede dar a entender que están buscando una persona que quiera trabajar durante 18 anos o hasta 30 anos, ven lo diferente de los significados ??. Para nosotros la segunda interpretación es ridícula porque tenemos la experiencia y contexto suficiente para comprender que no es posible, pero … ¿cómo le podemos enseñar algo similar a una maquina ??
> … Los chistes y los memes son una consecuencia de la ambigüedad y necesidad de contexto en nuestro lenguaje y aunque para nosotros son divertidos, para una máquina pueden llegar a ser un dolor de cabeza …
Evolución histórica del NLP
Desde la formulación del test de Turing en los años 50s el NLP a venido evolucionando en cuanto a la complejidad y versatilidad de sus algoritmos. Los primeros sistemas estaban basados en reglas estáticas y por lo tanto dependían mucho del uso de la lingüística. Estos primeros sistemas eran programados de forma que conocían todas las reglas de sintaxis y gramática y con base en ello podían procesar lenguaje de forma muy básica. Durante buena parte del siglo XX ese fue el paradigma, hasta que en los años 90s el uso de la estadística se volvió popular para calcular probabilidades de ocurrencia de palabras en un texto o un cuerpo de varios textos (Corpus), una vez calculadas esas probabilidades era posible generar automáticamente frases que sintácticamente tenían sentido. Comenzando el siglo XXI, el Machine Learning se volvió la nueva tendencia y junto con el uso de Estadística permitió construir algoritmos mas sofisticados para hacer, por ejemplo, clasificación de texto según tópicos de conversación.

> El Machine Learning cambio el paradigma de NLP, pasamos de programar algoritmos con reglas estaticas previamente definidas a algoritmos que son capaces de aprender las reglas gramaticales de nuestro lenguaje a partir de ser expuestos a numerosos ejemplos.
En la mitad de la década que acaba de terminar, florece el Deep Learning con el auge de entrenar redes neuronales usando GPUs y esto ha tenido un impacto enorme en los sistemas de conversación con asistentes virtuales, motores de búsqueda, etc … . Con estas ultimas arquitecturas de computo ha sido posible programar los sistemas mas inteligentes de procesamiento de lenguaje natural a la fecha.
Ultimos avances con Deep Learning
Con el uso del Deep Learning ha sido posible avanzar en dos grandes lineas de NLP. Por un lado en términos de entendimiento de lenguaje a bajo nivel y por otro lado en términos de algo que se llama el Aprendizaje de Representaciones o Representation Learning.
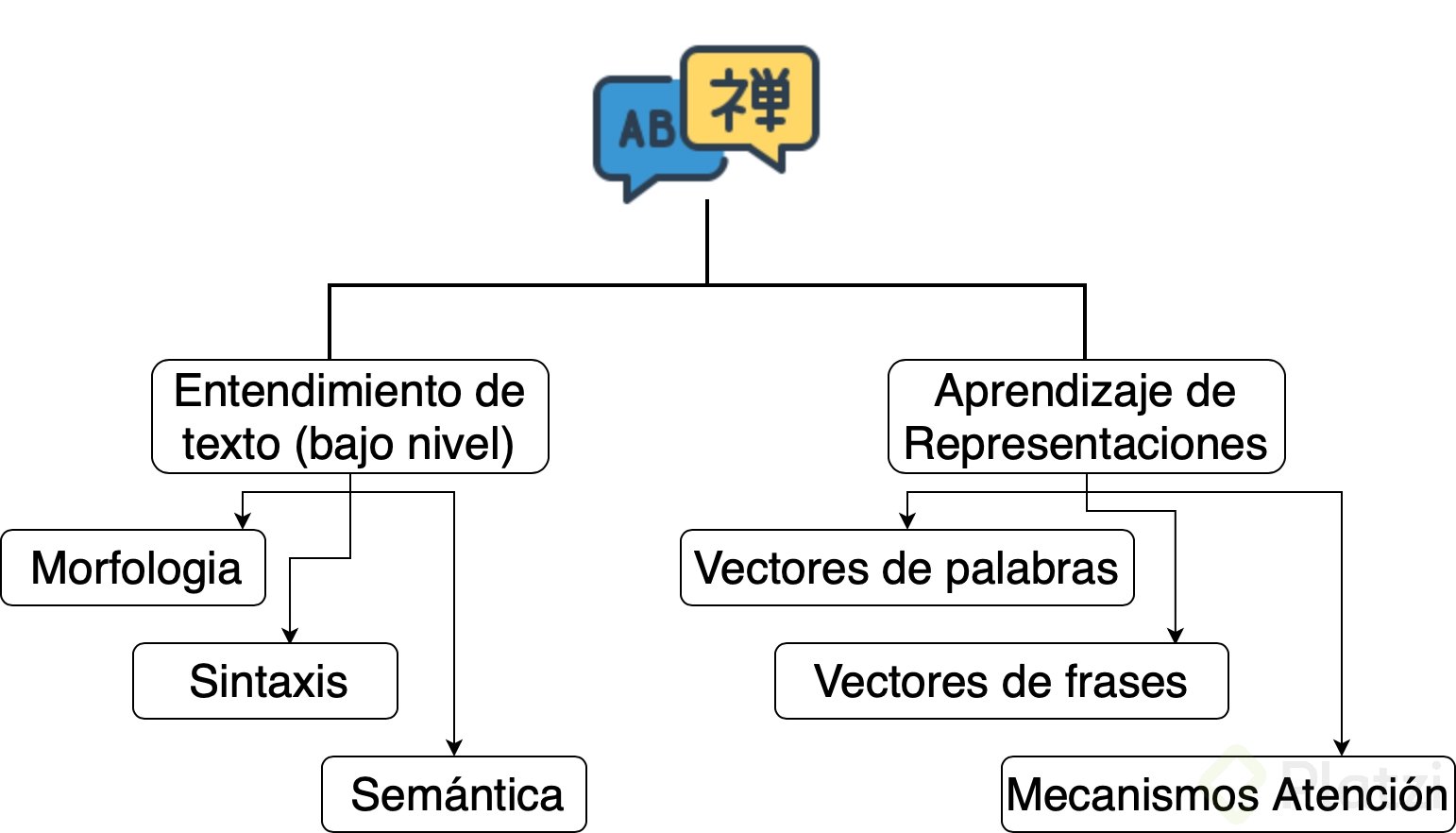
En el Entendimiento de texto a bajo nivel podemos programar algoritmos que son extremadamente buenos ejecutando solo una tarea especifica de procesamiento de lenguaje. Por ejemplo, un algoritmo que puede identificar cuándo una palabra representa un verbo o un adjetivo, y es muy bueno solamente en esa tarea especifica.
Por otro lado, el Representation Learning genero una revolución en los últimos años ya que ha permitido el desarrollo de arquitecturas de redes neuronales que tienen la capacidad de ejecutar múltiples tareas de naturaleza muy diversa en procesamiento de lenguaje natural. Los llaman modelos multi-task y están basados en la idea de convertir cadenas de texto en vectores, al objeto computacional que realiza este proceso se le denomina Embedding.
> ¿cómo sabemos si dos cadenas de texto son similares o tienen un significado similar? la idea es convertir esas cadenas en vectores y diremos que los textos serán similares si sus vectores son cercanos
Pero la pregunta natural que primero surge es: ¿Cómo saber cuales vectores asignar a cada cadena de texto, de manera que la distancia entre vectores refleje realmente la similitud semántica?.
La respuesta a esto han sido las redes neuronales, y a lo largo de los últimos años de investigación y desarrollo en Deep Learning aplicado a NLP, las arquitecturas de redes neuronales han ido mejorando sustancialmente. Hace unos pocos años los modelos que mejor desempe;o tenían eran las redes LSTM en tareas como traducción automática, hasta que hace menos de 2 años aparecieron las arquitecturas Transformer que estan basadas en la idea de mecanismos de atención, las cuales a su vez han tenido un reciente upgrade en lo que se llaman los Reformers, que básicamente son Transformers mas eficientes.
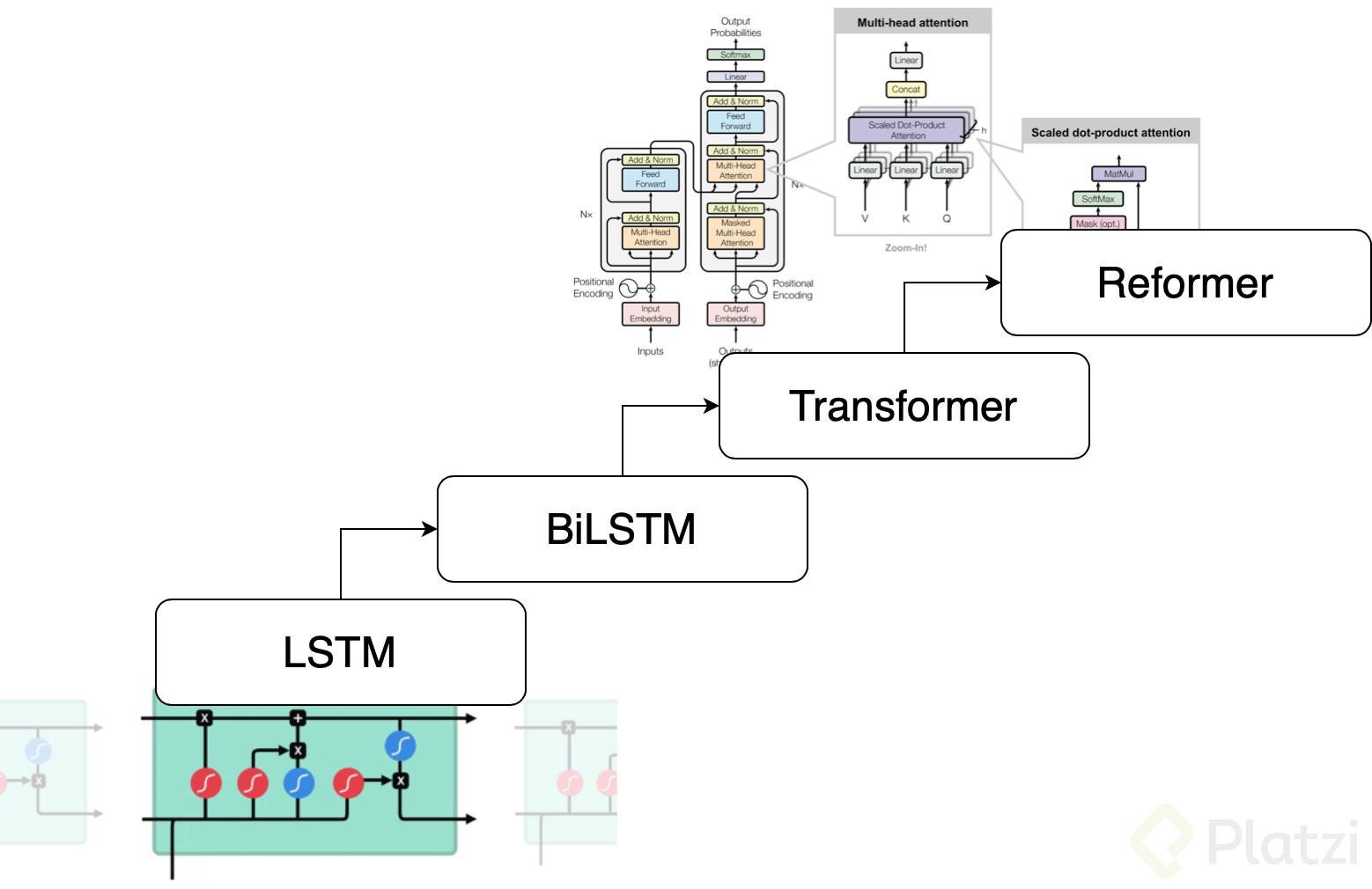
> Todas estas arquitecturas de red neuronal se han usado para mapear cadenas de texto en vectores que obedecen muy bien a la noción de similitud semántica. Es decir, estos modelos proporcionan embeddings apropiados para multiples tareas de NLP
Lee también: Machine Learning vs. Deep Learning
Las arquitecturas Transformer han tenido un auge impresionante, y su desempeño en multiples tareas de NLP esta por encima de la mayoría de algoritmos. Uno de los modelos basados en estas arquitecturas es el famoso GPT-2 desarrollado por OpenAI, el cual causó revuelo cuando fue anunciado, debido a que era capaz de generar texto con una calidad y naturalidad sin precedentes, a punto de poder confundir una persona con una maquina (recordando el experimento del test de Turing). En internet podemos encontrar titulares escandalosos haciendo referencia al algoritmo GPT-2:

Sin embargo, a pesar de los destacables progresos en materia de procesamiento de lenguaje natural que el Deep Learning ha permitido, un reciente estudio ha revelado que al parecer aun estamos lejos del objetivo, ¿porqué?. Bueno … para saber más y empezar a convertirte en un profesional experto en NLP, te recomendamos que inicies con nuestro Curso de Fundamentos de procesamiento de Lenguaje Natural
Curso de Fundamentos de Procesamiento de Lenguaje Natural con Python y NLTK
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE