
Node.js es un entorno en tiempo de ejecución multiplataforma y es una de las tecnologías líderes cuando hablamos de áreas como backend y desarrollo de aplicaciones de lado de servidor.
En el Curso de fundamentos de Node.js, se explican detalles y fundamentos básicos que nos permitirán iniciar de cero en esta increíble y potente tecnología.
Ahora, vayamos al grano. En este blog les explicaré paso a paso como extraer datos del Diario Oficial de la Federación.
El Diario Oficial de la Federación (DOF) es el periódico oficial del gobierno mexicano. Su función es la publicación de leyes, acuerdos, circulares, órdenes y todos los actos expedidos por los poderes de la Federación, con el fin de que sean observados y aplicados debidamente en sus respectivos ámbitos de competencia.
En este Diario, la Secretaría de Hacienda y en específico el Servicio de Administración Tributaria (SAT), publica de manera periódica la lista de **PRESUNTAS “**empresas fantasma” o “empresas de papel” a las que se les da un plazo de 15 días hábiles para presentar ante las oficinas de las autoridades un escrito libre en original y dos copias firmado por el contribuyente o su representante legal en el que manifiesten y anexen documentación e información que desvirtúen los hechos que llevaron a la autoridad a notificarlos.
Algunos de los motivos por los cuales se notifica, son emitir comprobantes fiscales sin contar con:
- Los activos.
- El personal.
- La infraestructura o capacidad material para prestar los servicios o entregar los bienes que amparen tales comprobantes.
Para fines prácticos, utilizaremos la lista publicada el 27 de Enero del 2020:
https://www.dof.gob.mx/nota_detalle.php?codigo=5584830&fecha=27/01/2020
Entonces… comencemos.
Lo primero que hay que hacer:
- Abrir la línea de comandos, crear la carpeta que contendrá el proyecto e inicializar el proyecto con npm
> mkdir DOF-Scraper
> cd DOF-Scraper
> npm init -y
- Instalar el paquete table-scraper con npm
> npm install table-scraper
- Abrir el proyecto en tu editor de código favoritos y crear un archivo index.js. Importar los paquetes que utilizaremos:
// Table-scraper nos permitirá extraer la información.
const scraper = require("table-scraper");
// Fs nos servirá para crear nuestros archivos de resultados.
const fs = require("fs");
- Usamos la constante scraper y en específico el método get que recibe un parámetro en formato string (URL)
scrapper.get(
"https://www.dof.gob.mx/nota_detalle.php?codigo=5584830&fecha=27/01/2020"
);
Como podrán ver, aún no podemos ver ningún resultado porque no estamos haciendo nada con la respuesta de la promesa que contiene el método get.
- Cambiaremos nuestro código para agregar un .then que nos permite manipular la respuesta.
scrapper
.get(
"https://www.dof.gob.mx/nota_detalle.php?codigo=5584830&fecha=27/01/2020"
)
.then((data) => {
console.log(data);
return data;
});
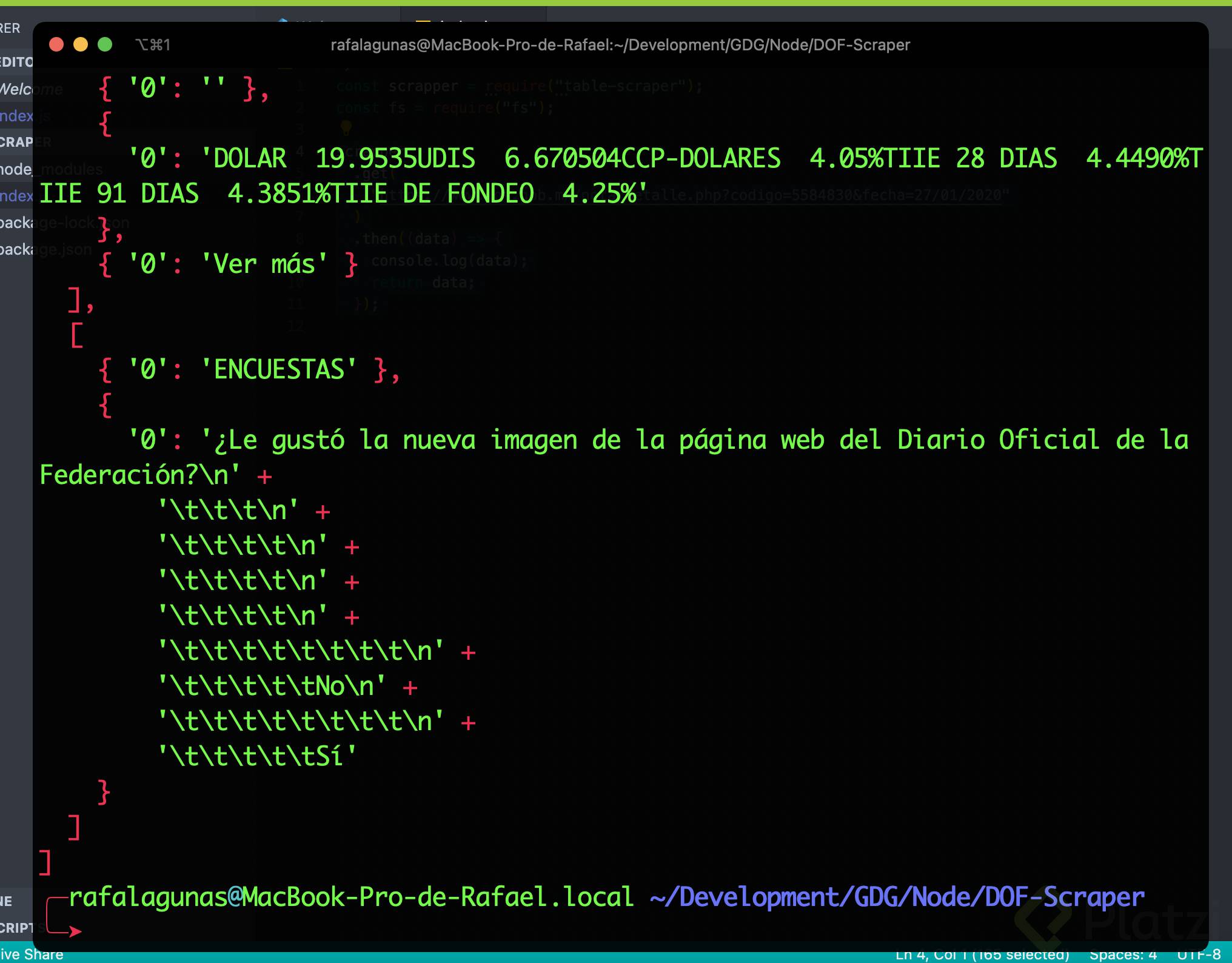
- Como podrán ver, ahora ya estamos imprimiendo en consola los datos que nos devuelve la función pero al ser mucha la información, es muy difícil analizar la estructura. Es por eso que guardaremos todo este primer resultado en un archivo llamado RAW.json
scrapper
.get(
"https://www.dof.gob.mx/nota_detalle.php?codigo=5584830&fecha=27/01/2020"
)
.then((data) => {
fs.writeFile("RAW.json", JSON.stringify(data), function (err, res) {
if (err) {
console.log(err);
}
});
return data;
});
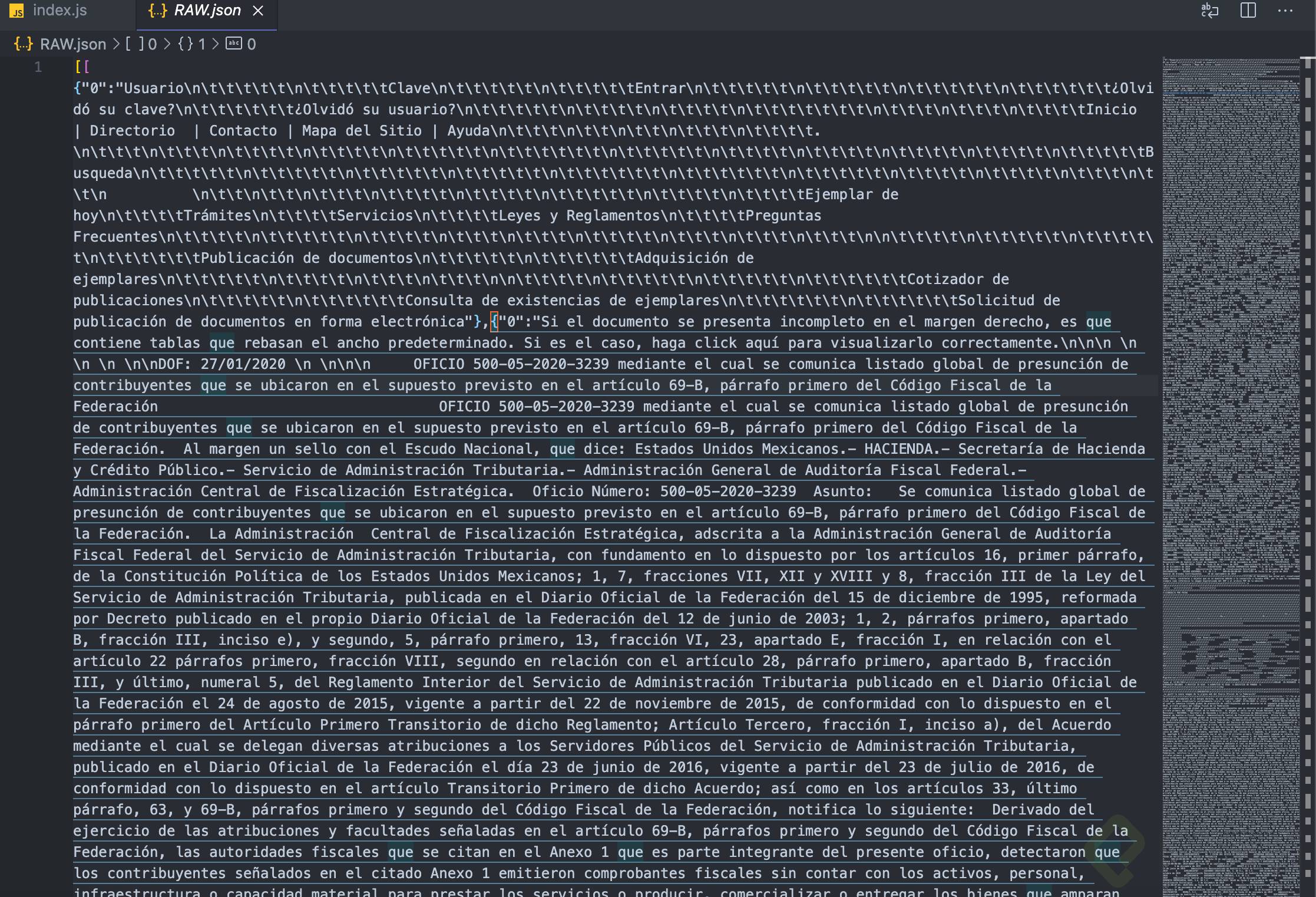
Ahora, podemos ver toda la estructura del sitio que estamos extrayendo y ver que estamos obteniendo un Json. Analizando el archivo, podremos buscar por patrones y áreas específicas para extraer la información que necesitamos.
- Después de un no tan breve análisis, encontramos que en el arreglo 5, línea 7455 del archivo, encontramos los objetos relacionados a la tabla.
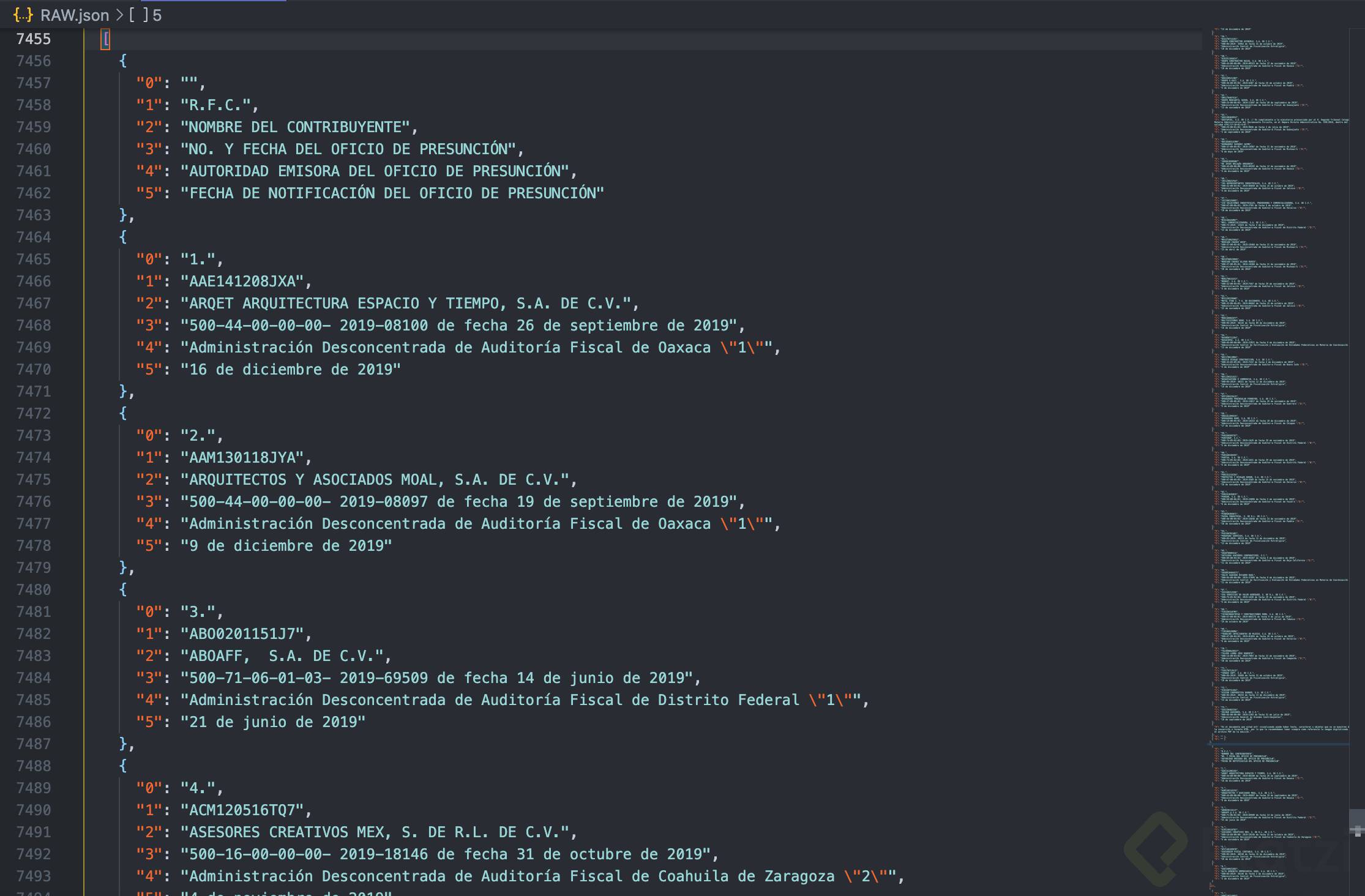
- Ahora que conocemos qué parte del archivo contiene la información que necesitamos, procederemos a codificar lo siguiente:
.then((data) => {
//console.log(data);
fs.writeFile("RAW.json", JSON.stringify(data), function (err, res) {
if (err) {
console.log(err);
}
});
return data;
})
.then((data) => {
let arrayOne = data[5];
console.log(arrayOne);
});
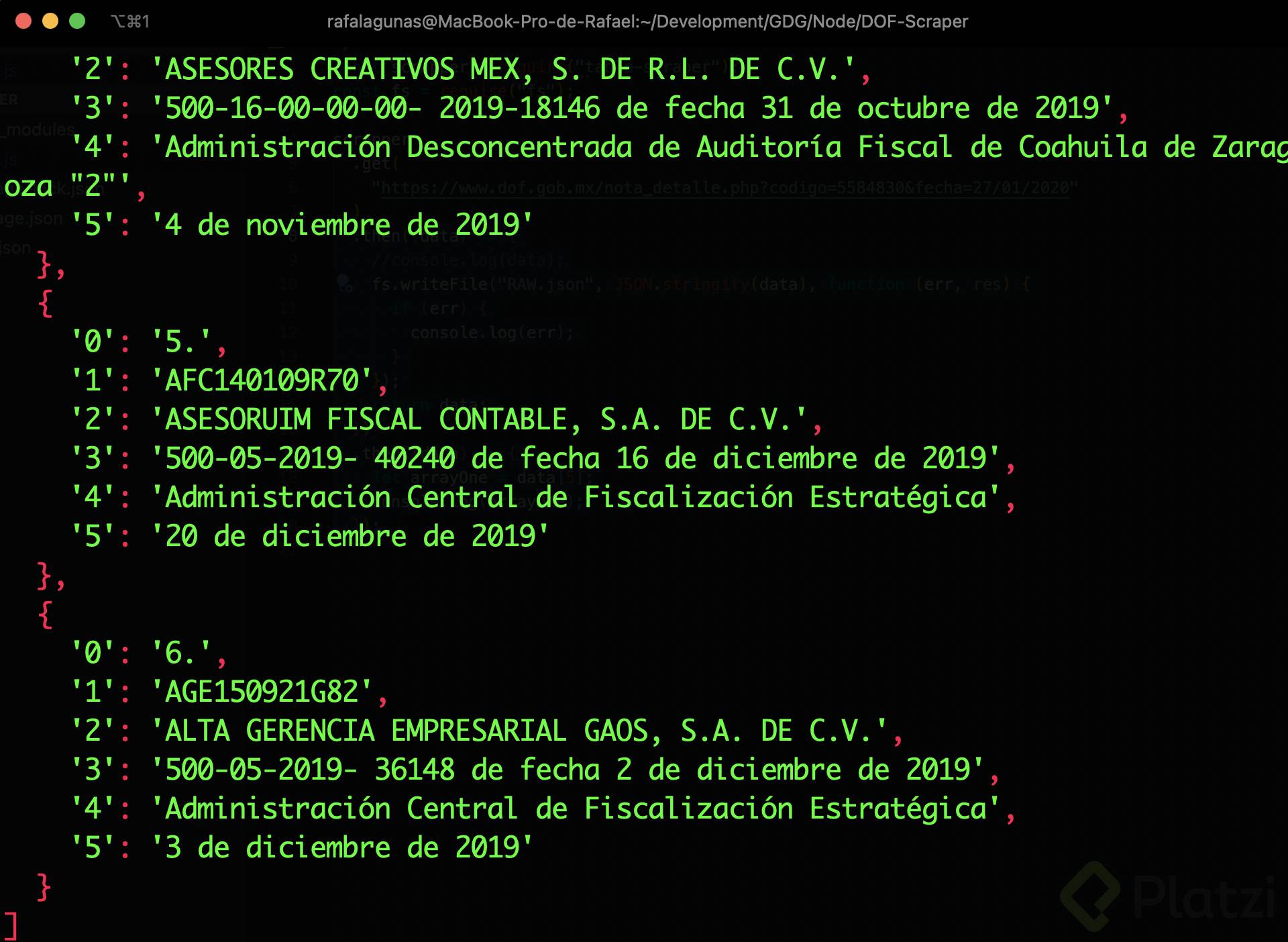
Nos daremos cuenta de que la tabla está partida en arreglos de objetos, por lo que procederemos a hacer la continuidad llamando el siguiente para validar:
.then((data) => {
let arrayOne = data[6];
console.log(arrayOne);
});

Nos daremos cuenta de que el arreglo 6 no tiene ningún valor definido y por lo tanto, nos devuelve undefined al momento de imprimirlo.
Una vez que seguimos con el siguiente arreglo, nos damos cuenta de que podremos continuar del arreglo 7 al 20 para así obtener la lista completa incluida en la tabla. Utilizaremos el método .concat() para ir concatenando los arreglos:
let concat = arrayOne
.concat(data[7])
.concat(data[8])
.concat(data[9])
.concat(data[10])
.concat(data[11])
.concat(data[12])
.concat(data[13])
.concat(data[14])
.concat(data[15])
.concat(data[16])
.concat(data[17])
.concat(data[18])
.concat(data[19])
.concat(data[20]);
console.log(concat)
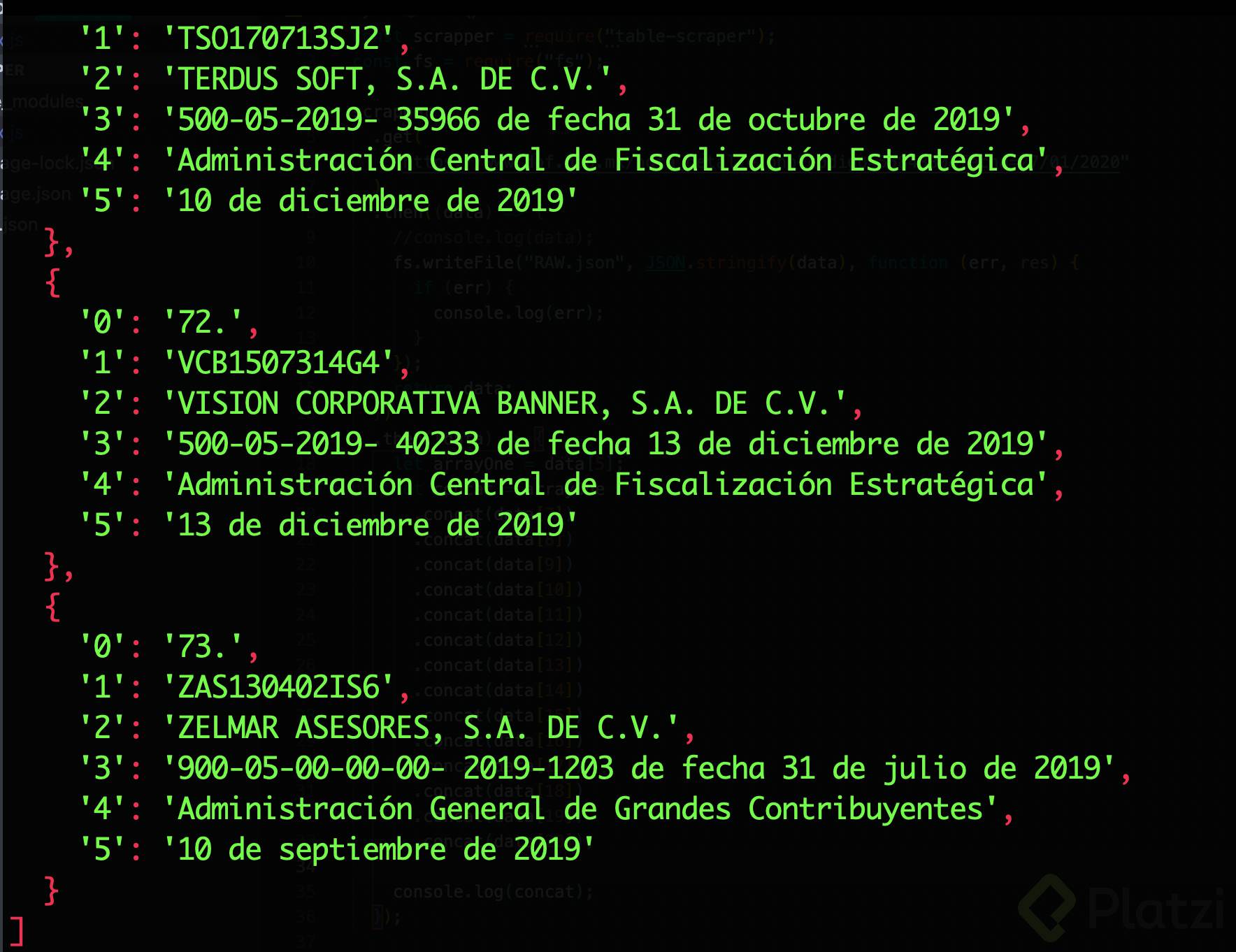
Una vez verificamos que efectivamente ya tenemos un json limpio, procederemos a guardarlo en un archivo llamado CLEAN.json:
.then((data) => {
let arrayOne = data[5];
let concat = arrayOne
.concat(data[7])
.concat(data[8])
.concat(data[9])
.concat(data[10])
.concat(data[11])
.concat(data[12])
.concat(data[13])
.concat(data[14])
.concat(data[15])
.concat(data[16])
.concat(data[17])
.concat(data[18])
.concat(data[19])
.concat(data[20])
.concat(data[21]);
console.log(concat);
fs.writeFile(
"CLEAN.json",
JSON.stringify(concat),
function (err, res) {
if (err) {
console.log(err);
}
}
);
return concat;
});
Y nuestro archivo se verá así:
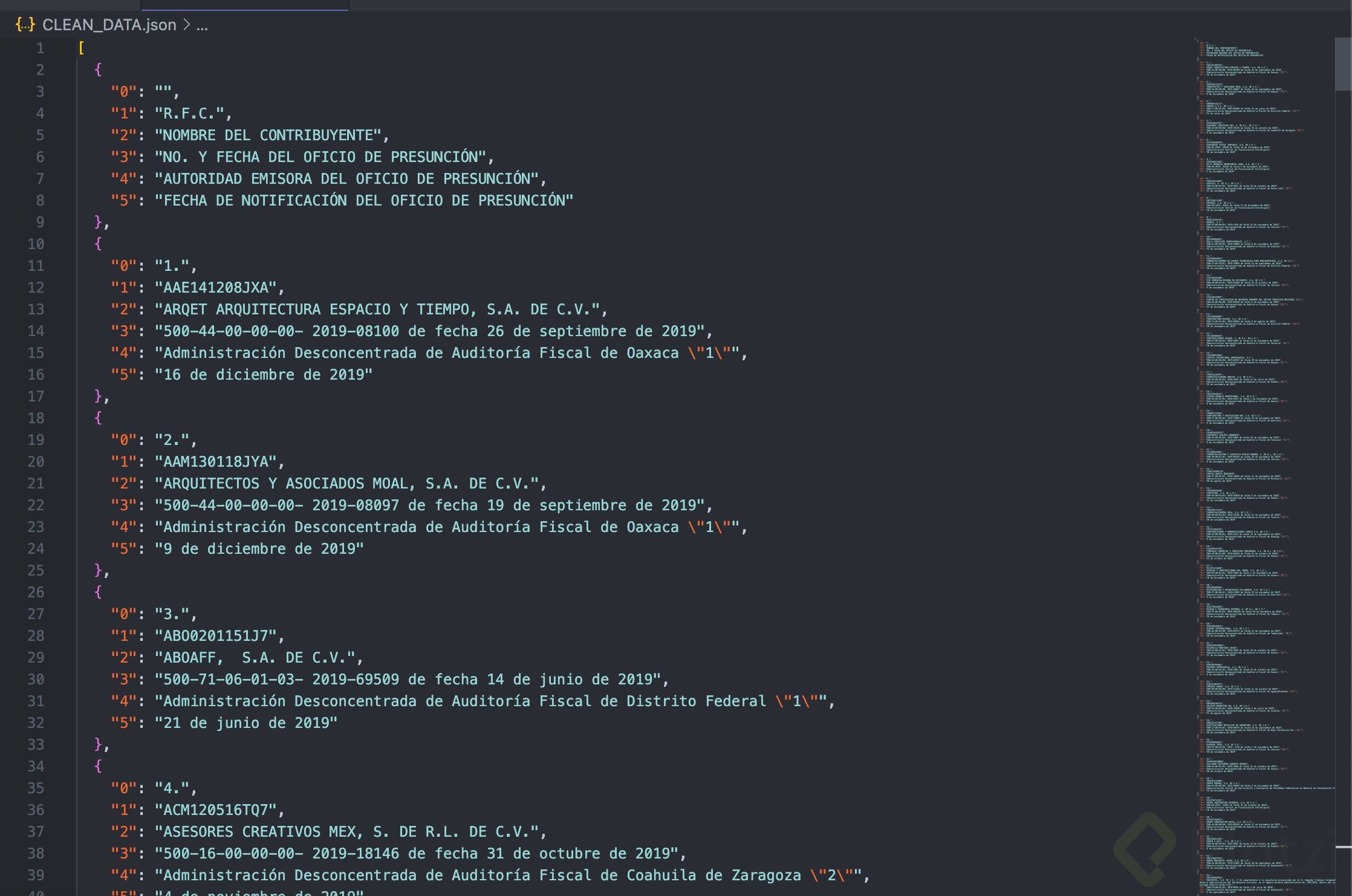
Y ahora tendremos un archivo json almacenado para consumir o almacenar en alguna base de datos como MongoDB y poder generar un script que periódicamente haga la recolección.
Conclusión:
Scrapear es más fácil de lo que parece. En solo 50 líneas de código, obtuvimos información específica de un archivo de más de 5000 líneas. Aprende a hacerlo en la página que quieras con Platzi 💚.
Si quieres seguirme en Github: Rafael Lagunas
Curso de Backend con Node.js: API REST con Express.js
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







