En este tutorial aprenderás a hacer cualquier tipo de gráfica para representar tus datos utilizando la librería de graficación de Python: Matplotlib. Además, aprenderás a personalizar al máximo cada uno de los plots para que puedas estampar exactamente la información que quieres. Y si ya tenías conocimientos básicos de Matplotlib, estoy seguro de que te encontrarás con un par de sorpresas nuevas. 📊
¿Qué es Matplotlib?
Matplotib es una poderosa librería de visualización de Python. Esta librería nos provee funciones en Python para crear gráficas enriquecidas que se adaptan a todo tipo de datasets y permite una personalización muy profunda, dándote el completo control de las propiedades de tus gráficas.
Antes de iniciar te recomiento tener conocimientos básicos de Pandas. Aquí te dejo la guía definitiva para dominar Pandas, en la que usamos exactamente el mismo dataset que se usará en este tutorial.
Ahora sí, ¡empecemos!
Hay muchas maneras de usar Matplotlib. En este tutorial vamos a usar la interfaz principal orientada a objetos, que proporciona la mayor flexibilidad para crear y personalizar las visualizaciones de datos, la cual podemos tener a través del submódulo pyplot.
Cómo instalar Matplotlib
Para instalar Matplotlib, digita en tu consola:
pip install matplotlib
Y para importarlo en tu código, por convención se usa:
import matplotlib.pyplot as plt
Si estás trabajando con un notebook en la nube como Deepnote o Colab, Matplotlib ya estará instalado y solo tendrás que importarlo.
Tus primeros pasos con Matplotlib
Este tutorial es muy práctico, por lo que la mejor manera de sacarle provecho es ir practicando cada concepto. Así que preparé un notebook para ti con todo lo que te enseñaré a continuación. Duplícalo (o descárgalo) y ve haciendo los ejercicios y retos ahí (luego puedes compartir tus resultados en los comentarios).
Conociendo Pyplot
El comando plt.subplots() crea 2 objetos: una Figure fig (figura) que es un contenedor de todo lo que verás en el gráfico y los Axes ax (ejes) que contienen la información a graficar. En el siguiente código se muestra la manera de crear un gráfico vacío.
fig, ax = plt.subplots()
plt.show() # Usa siempre este comando para que el gráfico aparezca
Este gráfico te ayudará a entender la anatomía de una figura, nota como los ejes están dentro de la figura.
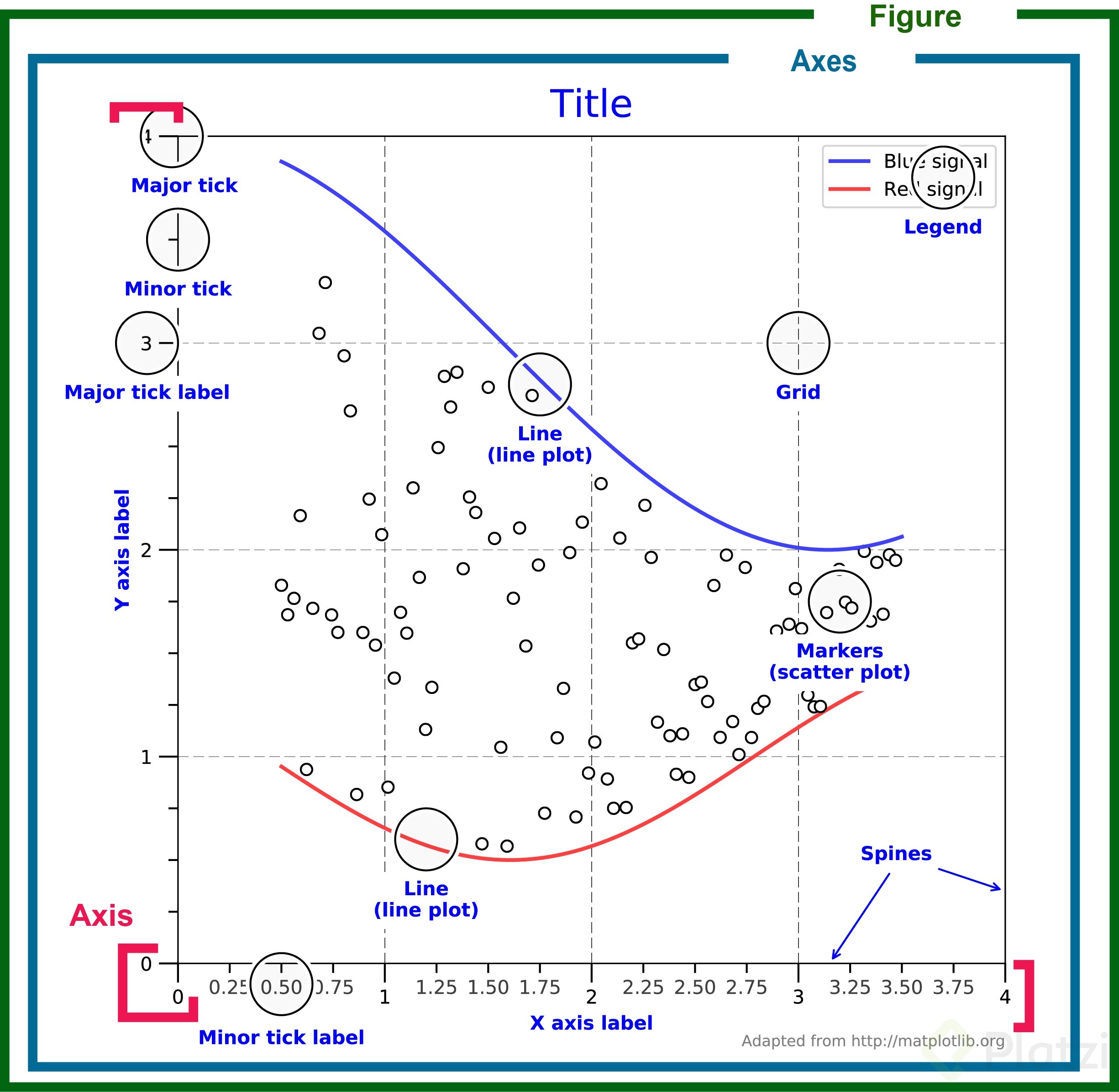
Para poder visualizar los datos que tengamos, estos se deben añadir a los ejes. La manera de hacerlo es mediante métodos de ploteo que trae el objeto Axes. El más básico de todos es plot, el cual crea un gráfico lineal y requiere los datos del eje X y Y como argumentos.
Por último, puede haber más de una sola gráfica para una misma figura, así que puedes usar plot más de una vez y tendrás distintas gráficas para un mismo eje.
Veamos un ejemplo simple de su funcionamiento:
# Filtrando datos del dataset entre 2014 y 2019
messi_goals = df.loc['Lionel Messi'].query('year != 2020')
ronaldo_goals = df.loc['Cristiano Ronaldo'].query('year != 2020')
# Plot -> ax.plot(X, Y)
fig, ax = plt.subplots()
ax.plot(messi_goals.year, messi_goals.goals)
ax.plot(ronaldo_goals.year, ronaldo_goals.goals)
plt.show()
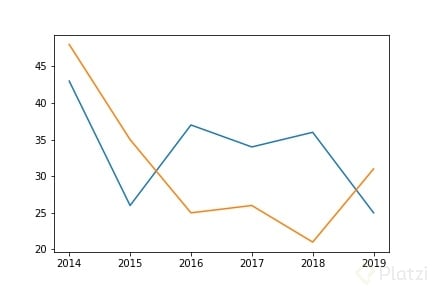
Personalizar un plot
El gráfico anterior está bien, pero no es muy claro, es difícil comprender a qué color pertenece cada jugador o qué representa cada eje. Hay una serie de argumentos que te permitirán personalizar cómo se ven los datos de tu plot tanto como te puedas imaginar:
label='name'→ pone una etiqueta al plot para saber a qué corresponde cada color (muy útil cuando vas a poner varias gráficas en un solo plot).marker='o'→ añade marcadores al plot y también puedes indicar el tipo de marcador que quieres. Aquí te dejo todas las opciones de marcadores que existen.linestyle='--'→ cambia el tipo de línea. Así mismo, aquí podrás encontrar los distintos tipos de línea. Incluso si colocas'None', simplemente ya no habrá líneas y quedarán solo los marcadores.color='b'→ cambia el color de tus datos. Aquí encontrarás cómo poner cualquier color e incluso dejarlos transparentes conalpha.
Adicionalmente, el objeto Axes trae una serie de métodos que podrías usar para que sea sencillo identificar de qué trata tu gráfica. Colócalos siempre antes de mostrar tu gráfica (antes de plt.show()).
.set_xlabel('Name')→ coloca nombre al eje de las X..set_ylabel('Name')→ coloca nombre al eje de las Y..set_title('Name')→ coloca el título de tu plot..set(xlabel='Name', ylabel='Name')→ también puedes usar únicamentesety pasar como parámetros lo anterior..legend()→ si anteriormente pusiste etiquetas conlabel,legendlas mostrará.
fig, ax = plt.subplots()
ax.plot(messi_goals.year, messi_goals.goals,
marker='o', color='b', linestyle='--', label='Lionel Messi')
ax.plot(ronaldo_goals.year, ronaldo_goals.goals,
marker='s', color='r', linestyle='dotted', label='Cristiano Ronaldo')
ax.set(xlabel='Years', ylabel='Goals', title='Messi vs. Cristiano goals (2014 - 2019)')
ax.legend()
plt.show()
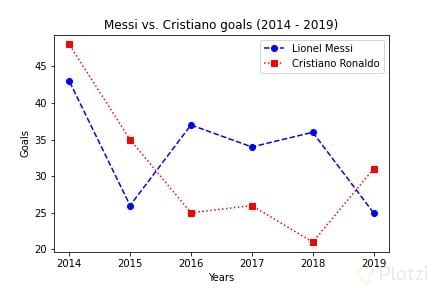
¡Esto se ve muchísimo mejor! (aunque no tiene buenas prácticas de visualización, pero sirve para el ejemplo). Veamos qué más se puede hacer. 🏃♀️
Subplots
Como viste, a los ejes les puedes pasar toda la información que quieras y podrías tener varios gráficos uno encima de otro. Esto a veces puede ser útil, pero a veces puede resultar en un completo desastre como esto:
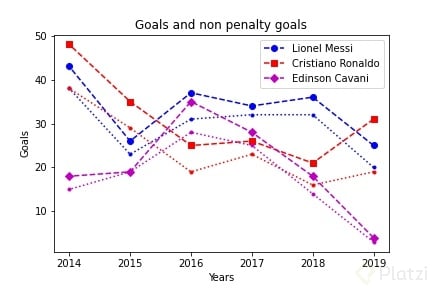
¿Recuerdas que la figura contiene a los ejes? Bueno, podrías crear subplots dentro de una misma figura para poder dividir la información. Para eso usaremos plt.subplots(), pero esta vez le pasaremos argumentos. El primer argumento deberá ser un entero que hace referencia al número de filas y el segundo será otro entero que dictará el número de columnas. De esta manera tendrás toda una matriz de plots.
fig, ax = plt.subplots(3, 2) # matriz 3 × 2
plt.show()
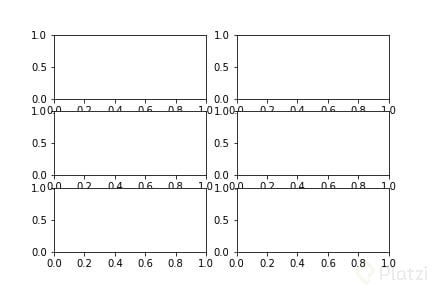
¿Qué pasó con el objeto Axes en este caso? Como todo está contenido dentro de Figure y Axes contiene la información del plot, y hay toda una matriz de plots, significa que se creó una matriz de Axes. Si digitas ax.shape te encontrarás que es un array de 3 × 2.
Ahora podrás acceder a cada uno de los plots con la notación ax[row, column]. Por ejemplo, para acceder al plot ubicado en la segunda fila y primera columna, sería ax[1, 0]. Y en caso de solo tener una única fila o columna de plots, solo deberás pasar el índice correspondiente al array. Por ejemplo, para acceder al tercer plot, sería ax[2].
Tips adicionales: si quieres que todos tus plots tengan la misma escala en el eje Y, pásale a plt.subplots el argumento sharey=True. Además, figsize te permite colocar el ancho y alto respectivamente (en pulgadas, por defecto está en [6.4, 4.8]).
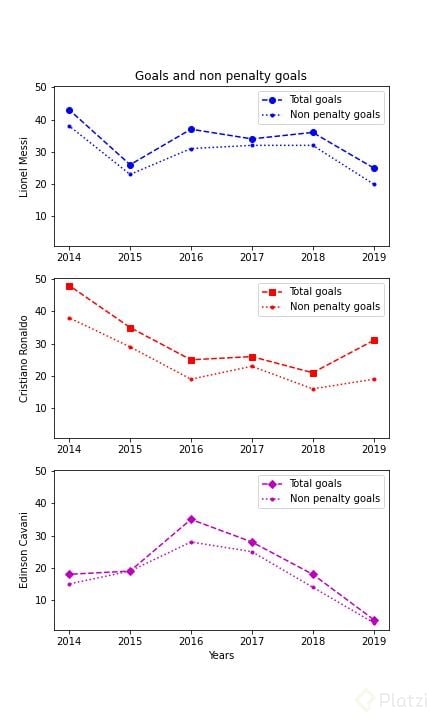
Ahora sí, pongamos todo esto en acción y mejoremos el gráfico anterior. Tómate el tiempo de leer detenidamente el código y entenderlo.
fig, ax = plt.subplots(3, 1, sharey=True, figsize=[6, 10])
ax[0].plot(messi_goals.year, messi_goals.goals,
marker='o', color='b', linestyle='--', label='Total goals')
ax[0].plot(messi_goals.year, messi_goals.npg, marker='.',
color='b', linestyle='dotted', label='Non penalty goals')
ax[1].plot(ronaldo_goals.year, ronaldo_goals.goals,
marker='s', color='r', linestyle='--', label='Total goals')
ax[1].plot(ronaldo_goals.year, ronaldo_goals.npg, marker='.',
color='r', linestyle='dotted', label='Non penalty goals')
ax[2].plot(cavani_goals.year, cavani_goals.goals,
marker='D', color='m', linestyle='--', label='Total goals')
ax[2].plot(cavani_goals.year, cavani_goals.npg, marker='.',
color='m', linestyle='dotted', label='Non penalty goals')
ax[2].set_xlabel('Years')
ax[0].set_ylabel('Lionel Messi')
ax[1].set_ylabel('Cristiano Ronaldo')
ax[2].set_ylabel('Edinson Cavani')
ax[0].set_title('Goals and non penalty goals')
ax[0].legend()
ax[1].legend()
ax[2].legend()
plt.show()
Gráficos de barras
Hasta ahora hemos visto un único tipo de gráfico, el lineal. Es hora de conocer otros tipos que te ayudarán a hacer comparaciones cuantitativas entre partes de tus datos. Uno de ellos es el gráfico de barras, que lo puedes crear con ax.bar(x, y).
Pero primero una observación, si no vas a trabajar con suplots, podrías omitir el fig, ax = plt.subplots() y trabajar todo directamtente con plt en vez de con ax. Así es como usualmente lo encontrarás. En general, plt funciona muy parecido a ax, solo hay algunos métodos que cambian, por ejemplo, se usa plt.xlabel en lugar de ax.set_xlabel para etiquetar el eje X.
Antes de pasar a ver ejemplos, quiero enseñarte un par de métodos extra de personalización que te ayudarán. En los gráficos de barras es común hacer comparaciones entre categorías, por lo que en vez de tener una escala de números, las etiquetas de tus ejes podrían ser strings que probablemente queden sobrepuestas unas sobre otras.
Para solucionar ese problema, se usa:
plt.xticks(rotation=90)→ podrás seleccionar las etiquetas de tus ejes y rotarlas 90 grados.
Por otro lado, si no te gustan los estilos por defecto de matplotlib, es posible usar plantillas prediseñadas con plt.style.use('ggplot'). Tienes que declararlo antes de crear tus figuras y se aplicará a todas. Si quieres luego regresar a los estilos por defecto, podrás pasar 'default' como argumento. Aquí te comparto la documentación de todos los estilos de Matplotlib.
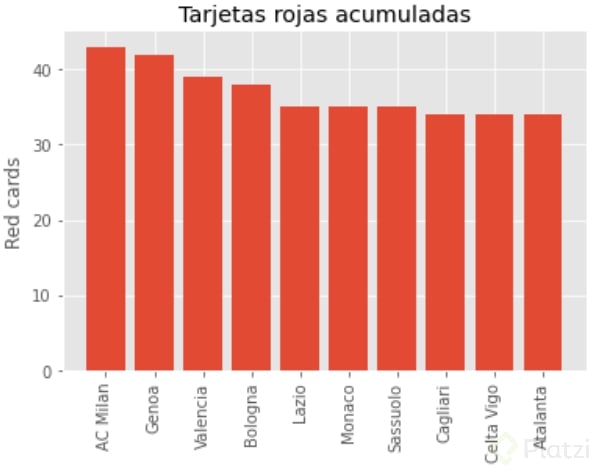
Descubramos los 10 equipos con más tarjetas rojas acumuladas:
# Datos de tarjetas rojas por equipo
top_red_cards = df.groupby('team_name')['red_cards'].sum() \
.sort_values(ascending=False).head(10)
# Plot
plt.style.use('ggplot')
plt.bar(top_red_cards.index, top_red_cards)
plt.xticks(rotation=90)
plt.title('Tarjetas rojas acumuladas')
plt.ylabel('Red cards')
plt.show()
Seguramente te estés preguntando si es posible hacer que las barras estén horizontales en vez de verticales y la respuesta es sí. ✅ Solo usa plt.barh() en lugar de plt.bar().
También es posible crear un gráfico de barras apilado para añadir más información. Lo único que tienes que hacer es volver a llamar al método .bar() con tu nueva variable y añadirle el parámetro bottom=previous_data. Y si quieres añadir más información aún, tendrás que sumar toda la información previa: botom = previous_data_1 + previous_data_2.
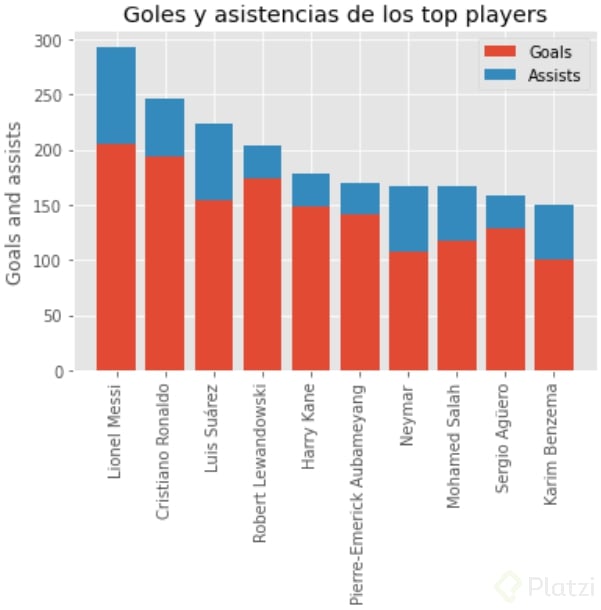
Por último, también puedes pasar label y color como argumentos de bar para etiquetar qué representa cada color. Vamos al código para dejarlo claro descubriendo los goles y asistencias de los top players:
# Filter
df['goals_assists'] = df.goals + df.assists
top_players = df.groupby('player_name')[['goals', 'assists', 'goals_assists']].sum() \
.sort_values('goals_assists', ascending=False).head(10)
# Plot
plt.bar(top_players.index, top_players.goals, label='Goals')
plt.bar(top_players.index, top_players.assists, label='Assists', bottom=top_players.goals)
plt.xticks(rotation=90)
plt.title('Goles y asistencias de los top players')
plt.ylabel('Goals and assists')
plt.legend()
plt.show()
Histogramas
Los histogramas representan la cantidad de ocurrencias de los valores en una columna, son muy utilizados en el análisis unidimensional para tener la distribución completa de valores de una variable. En el eje X se encuentra el rango de valores de la columna seleccionada y en el eje Y la cantidad de veces que se repite en la columna el mismo valor. Por ello la función solo requiere un argumento.
Para graficar un histograma se usa plt.hist(X) y como argumento se pasa la columna que quieras analizar. Además, puedes personalizar el gráfico con otros argumentos:
bins=n→ dice cuántas barras serán mostradas en el histograma. Por defecto vienen 10.- A este argumento también le puedes pasar una lista para establecer un límite en el rango de las X en las que quieras que se muestren.
- Si quieres colocar 2 histogramas que se podrían sobreponer entre sí, se puede usar el argumento
alphaque si le pasas un valor entre 0 y 1 cambia la transparencia del color. - También puedes usar el argumento
histtype='step'que hace que cambie la forma que se representa el histograma, por ejemplo líneas en vez de rectángulos sólidos. Aquí te dejo la documentación para ver qué otros tipos dehisttypeexisten y también otros argumentos de hist. - Por último, si usas
density=True, el gráfico se trasformará a porcentajes para que el área total sumada de los rectángulos sea de 1 (100%). Te recomiendo recordar este argumento porque podría ser muy útil más adelante para entender el peso de los valores más que su cantidad en sí misma.
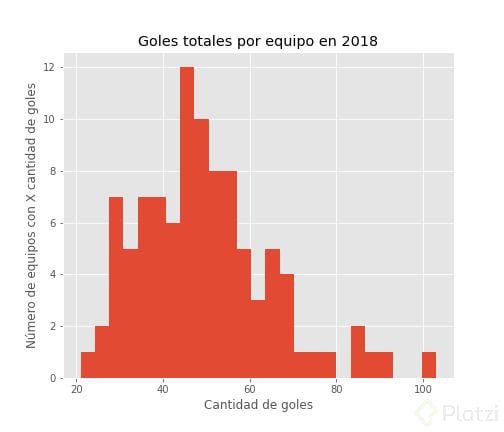
Hora de ver un ejemplo. Estos son los goles totales de los equipos en 2018, analiza la distribución.
# Goles totales por equipo en 2018
df_2018 = df.query('year == 2018')
team_goals_2018 = df_2018.groupby('team_name')['goals'].sum()
# Plot
plt.figure(figsize=[7, 6]) # 7 in de ancho y 6 in de alto
plt.hist(team_goals_2018, bins=25)
plt.title('Goles totales por equipo en 2018')
plt.xlabel('Cantidad de goles')
plt.ylabel('Número de equipos con X cantidad de goles')
plt.show()
Te desafío a probar añadir histtype='step', cambiar la catidad de bins e incluso colocar 2 histogramas en los mismos axes y cambiarles su transparencia con alpha. Por último, mira qué sucede al aplicar density, deja en los comentarios tu interpretación.
Gráficos de dispersión o scatter plots
Los scatter plots es el último tipo de gráfico que veremos. Estos son muy útiles para analizar 2 variables y descubrir si tienen o no una correlación. Aquí se grafica cada registro de los datos como un punto, el cual es determinado por el valor de las variables X y Y escogidas.
Se lo plotea con plt.scatter(x, y). Se le puede colocar varios argumentos que ya vimos para los gráficos anteriores, pero adicionalmente, hay un par muy útiles para pasar una tercera variable, por ejemplo, de tiempo. Con c=col podrás colorear cada punto con un degradado. Y con s=col podrás darles distintos tamaños a los puntos. Si quieres ver otros argumentos de este tipo de gráfico, acá te dejo la documentación oficial.
Vamos a ver un ejemplo de un scatter plot que correlacione disparos al arco y goles hechos (cada punto es un jugador). Además, con c=df_2018.games vamos a ver con un degradado de colores la cantidad de partidos jugados (con los estilos que estamos usando, los colores más claros significan un mayor número de partidos).
plt.scatter(df_2018.shots, df_2018.goals, c=df_2018.games)
plt.title('Disparos vs. goles')
plt.xlabel('Disparos')
plt.ylabel('Goles')
plt.show()
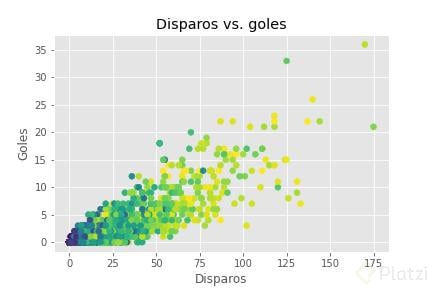
Podemos ver como sí que están correlacionadas las variables, a más disparos más goles, y también vemos con los colores como los jugadores con más disparos y goles también son los que más partidos han jugado. Los scatter plots te serán de gran ayuda cuando hagas análisis multidimensional.
Compartir visualizaciones de Matplotlib
¡Qué increíbles visualizaciones has hecho hasta ahora! Ha llegado el momento de guardarlas para compartirlas con el mundo. Hace un rato estuvimos trabajando mucho con el objeto Axes, pero a Figure no le prestamos mucha atención. 🤔 Bien, ¡este es el momento de hacerlo!
- Utiliza
fig.savefig('path/name.png')para guardar la imagen en el lugar que elijas, no olvides poner la extensión. PNG tiene menos compresión, pero tiene transparencia. También puedes guardar en otros formatos como JPG. Otra opción es guardarla como SVG y luego podrás editarla. 😉 - También puedes usar el argumento
qualitycon valores entre1y100para bajar la calidad y peso de tus imágenes en caso de necesitarlo. dpi=300esto hará que tu figura se vea en mejor calidad, pero también será más pesada.- Por último, es posible cambiar el tamaño de la figura con
fig.set_size_inches([width, height]).
# Código para guardar una figura de 5 × 3 pulgadas
fig.set_size_inches([5, 3])
fig.savefig('figure_5_3.png')
⚠️ Te reto a buscar cómo hacerlo con plt, ¿es igual? ¿Cambió algo?
Ejercicios de Matplotlib
Ahora mismo tienes todo lo fundamental que necesitabas saber, ¡qué emoción! 🥳
Pero te tengo la mala noticia de siempre… Todo lo que acabas de aprender en este post se te va a olvidar. 🙁
No te preocupes, te tengo la solución justo aquí. Pon en práctica todo por tu cuenta y ahora sí dominarás lo elemental de Matplotlib. 😁
Te comparto una serie de ejercicios. Comparte el código y sus resultados en los comentarios. Usarás este dataset, consiste en resultados de exámenes de estudiantes. Incluye calificaciones de matemáticas (math score), de lectura (reading score) y de escritura (writing score).
Crea un nuevo notebook y ejecuta lo siguiente:
- Importa estas tres librerías:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
- Carga el dataset que descargaste desde Kaggle:
df_students_performance = pd.read_csv('/content/StudentsPerformance.csv')
df_students_performance
- Para tus gráficas usarás tres columnas de este dataset. Para utilizarlas como variables definelas así:
math_score = df_students_performance['math score']
reading_score = df_students_performance['reading score']
writing_score = df_students_performance['writing score']
De esta manera podrás utilizar las columnas de tu dataset de manera más sencilla al crear tus gráficas.
- Completa estos ejercicios:
a) Crea un histograma para cada una de estas variables con 10 bins: math_score, reading_score, writing_score.
b) Crea un box plot para cada una de estas variables: math_score, reading_score, writing_score. Recuerda aplicar las modificaciones de verticalidad y notch al crearlos.
c) Utiliza el método orientado a objetos para crear una visualización con 6 axes (3, 2). Del lado izquierdo pon los histogramas y del lado derecho las box plots de las variables utilizadas previamente.
d) Crea 3 scatter plots para ver la relación entre las 3 variables. Aplica una transparencia de 0.5 a tus puntos de datos:
- math_score - reading_score
- math_score - writing_score
- reading_score - writing_score
Para modificar los colores de tus puntos en tu scatter plot aplica lo siguiente:
N = 1000
colors = np.random.rand(N)
Esto te dará 1000 posibilidades de colores para aplicar en tu scatter plot dentro del párametro c. ¿Por qué 1000? Porque son 1000 los registros/filas de nuestro dataset.
e) Aplica modificaciones de colores y estilos a todas las gráficas que creaste. Recuerda incluir títulos a tus gráficas y etiquetas a los ejes X y Y. Es indispensable para tener contexto de tus visualizaciones. 😉
Próximos pasos
¿Cómo te fue en el reto? ¿Qué cosas geniales descubriste? No te preocupes si no pudiste con alguno, de seguro encontrarás apoyo en los comentarios. 😉
Ahora te mostraré qué es lo que sigue, hay muchos gráficos más que puedes hacer y muchos más tipos de personalizaciones, acá te dejo absolutamente todo lo que Matplotlib tiene para dar, su galería de figuras. No le tengas miedo a utilizarlas, al final todo lo que importa es ver qué datos y argumentos en general aceptan cada una de las funciones de gráficos. Elige uno que te guste e intenta implementarlo.
Con eso ya tienes todo lo fundamental que necesitas para poder aplicar Matplotlib en tu día a día. Podríamos resumir el tuturial en que todo consiste en crear gráficas, pasarles los datos de los ejes, personalizar la gráfica y ponerle etiquetas a lo que estamos viendo. Con un poco de práctica se vuelve bastante sencillo. 😉
Sorprendente, ¿no? Parece que es demasiado, pero con las bases que tienes ahora te será muy sencillo ir a la gráfica que desees, ver la documentación e implementarla para lo que necesites. Espero verlas en los comentarios. 👇
Curso de Visualización de Datos con Matplotlib y Seaborn
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE