RAG con file search de OpenAI
Contenido del curso
El Núcleo del Agente: Estado y LLMs
Lógica y Estructura de Nodos
Agentes ReAct
Grafos Avanzados y Colaboración
- 17

Enrutamiento de agentes con conditional edge en LangGraph
09:49 min - 18
Routing inteligente con LLM para derivar conversaciones automáticamente
22:14 min - 19

Paralelización de nodos en agentes con LangGraph
06:58 min - 20
Desarrollo de un agente de code review con análisis paralelo
15:47 min - 21
Patrón orchestrator para selección dinámica de nodos en paralelo
16:31 min - 22
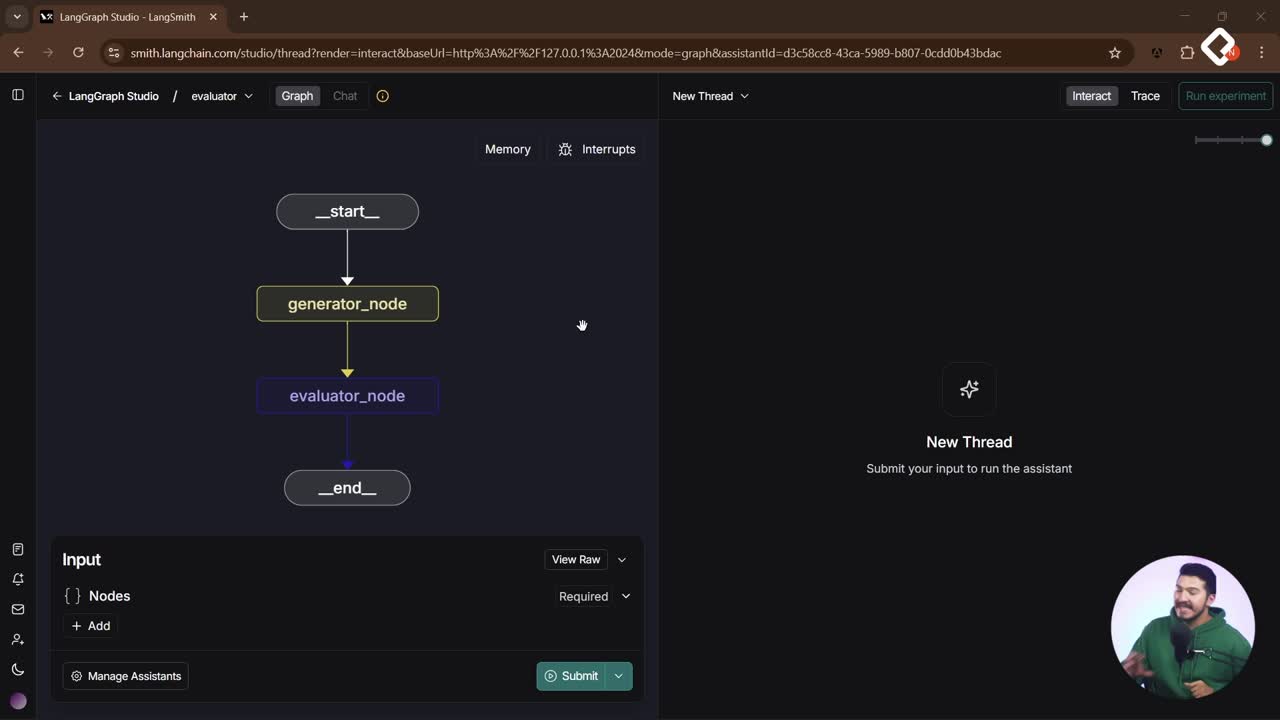
Evaluator Optimizer: ciclos de autocrítica para agentes de IA
12:48 min
Puesta en Producción
RAG con file search de OpenAI
Resumen
Construir un RAG (Retrieval Augmented Generation) con OpenAI te permite que un large language model responda preguntas usando tus propios PDFs, manuales o documentos privados. Esta técnica resuelve dos limitaciones grandes: la falta de información actualizada y el desconocimiento de tus datos personales o empresariales.
El flujo es directo: subes un PDF a una base de datos vectorial, OpenAI lo convierte en embeddings y luego tu agente puede consultar esa información cuando la necesite. Ideal para prototipar antes de saltar a arquitecturas más complejas.
¿Por qué un large language model necesita un RAG?
Un large language model fue entrenado hasta una fecha de corte, así que no conoce el clima de hoy ni los manuales internos de tu empresa. Todo lo que se pueda pasar a texto (PDFs, bases de datos, catálogos de productos) queda fuera de su entrenamiento original [00:09].
Ahí entran las tools. OpenAI ofrece varias herramientas integradas a su modelo, como web search, function calling, computer use y file search. Cada modelo tiene las suyas, y solo funcionan si usas ese proveedor en particular [01:25].
¿Qué es un RAG? Es una técnica que combina un modelo de lenguaje con una base de datos externa. El modelo busca información relevante en tus documentos y la usa para construir una respuesta precisa.
¿Cuándo conviene usar file search de OpenAI?
Esta tool es perfecta para tu primer RAG. Subes archivos, OpenAI los vectoriza, los guarda y permite consultarlos sin que tengas que montar una base vectorial propia tipo Chroma, Pinecone o Vectorize.
Es cómodo, pero tiene límites. No es tan personalizable ni desacoplada del modelo. Si necesitas algo más robusto, ya hablamos de procesos de extracción, limpieza de datos, embeddings personalizados e integración con tu agente.
¿Cómo subo un PDF a una base de datos vectorial en OpenAI?
El proceso vive en la plataforma de OpenAI, dentro de la sección storage > vector stores. Te recomiendo crear un proyecto específico para tu agente (por ejemplo, un customer support) en lugar de usar el default project [03:30].
Los pasos son:
- Entra a vector stores y dale create.
- Asigna un nombre, por ejemplo My Docs.
- Sube los archivos PDF que quieras consultar.
- OpenAI convierte el texto en embeddings automáticamente.
- Copia el ID de la base vectorial para usarlo en tu código.
Para el ejemplo se usó el Mobile Site Speed Playbook de Google, un PDF con buenas prácticas de performance web [03:00]. Puedes adjuntar varios archivos a la misma base, y todos quedan disponibles para consulta.
¿Cómo conecto la tool de file search en mi código?
En el notebook declaras la tool pasándole el ID de tu vector store. Defines un array (porque podrías tener varias bases vectoriales) y le indicas al modelo de OpenAI que extienda sus capacidades con esa herramienta [05:30].
Luego renombras tu large language model para que sea un modelo con tools. La diferencia es clave: ya no es solo el LLM, es el LLM más sus herramientas externas.
¿Por qué file search solo funciona con OpenAI? Porque es una tool nativa de su modelo. Si cambias a Anthropic, no sabrá qué hacer con esa declaración. Para hacerlo agnóstico necesitas un RAG desacoplado del proveedor.
¿Cómo decide el modelo cuándo usar la base vectorial?
El modelo es inteligente y hace un switch automático. Si le preguntas Hola, ¿cómo estás?, responde directo sin consultar tu base vectorial. Si le preguntas ¿cómo mejoro el rendimiento de mi website?, va al PDF, recupera la información y construye la respuesta [09:00].
Esto no lo controlas tú. El razonamiento del modelo decide cuándo invocar la tool según la pregunta. Por eso para preguntas triviales la respuesta llega más rápido, y para consultas técnicas tarda un poco más mientras hace el query vectorial.
La diferencia con un LLM sin tools es notable: sin RAG responde con su conocimiento general; con RAG responde con información afín a tus documentos. Eso lo vuelve útil para manuales de producto, guías internas o documentación específica.
¿Por qué solo enviar el último mensaje al RAG?
La tool de file search en OpenAI tiene una limitación importante: si le mandas todo el historial de mensajes, suele fallar por exceso de contexto [13:00]. La solución práctica es enviar únicamente el último mensaje del historial.
Esto tiene un costo: pierdes memoria conversacional. El agente ya no recordará tu nombre ni mensajes anteriores, salvo que inyectes contexto con técnicas de prompt. Para conversaciones largas con memoria completa, conviene saltar a un RAG más avanzado.
En el código, en lugar de pasar todo el history, tomas last_message (el último elemento del historial) y se lo envías al modelo. Mantienes el estado del chat, pero la consulta al modelo va limpia.
¿Cómo integro el RAG en un agente de LangGraph?
Duplicas el archivo simple.py y lo renombras como rag.py. Le agregas la declaración del file search tool, sobrescribes el LLM con la versión que tiene tools y ajustas el envío para usar solo el último mensaje [12:30].
Después registras el nuevo agente en el archivo langapp.json, agregando una entrada llamada rag. Reinicias el servidor con langapp dev (matar el anterior es obligatorio) y aparece en la interfaz.
Al probarlo verás dos comportamientos: con Hola, ¿cómo estás? responde corto y directo. Con ¿sabes cómo puedo mejorar un website? hace la consulta vectorial y devuelve recomendaciones extraídas literalmente del PDF cargado.
Un caso típico: imagina que cargas el manual de unos audífonos. Si preguntas ¿cómo conecto mi auricular?, el modelo no lo sabría por entrenamiento, pero al alimentarlo con el PDF te responde paso a paso porque esa información ya forma parte de su conocimiento contextual.
¿Ya probaste a subir tus propios manuales o documentos? Cuéntame qué tipo de RAG estás construyendo y qué retos te has encontrado.