Structured Output para agentes en LangGraph
Contenido del curso
El Núcleo del Agente: Estado y LLMs
Lógica y Estructura de Nodos
Agentes ReAct
Grafos Avanzados y Colaboración
- 17

Enrutamiento de agentes con conditional edge en LangGraph
09:49 min - 18
Routing inteligente con LLM para derivar conversaciones automáticamente
22:14 min - 19

Paralelización de nodos en agentes con LangGraph
06:58 min - 20
Desarrollo de un agente de code review con análisis paralelo
15:47 min - 21
Patrón orchestrator para selección dinámica de nodos en paralelo
16:31 min - 22
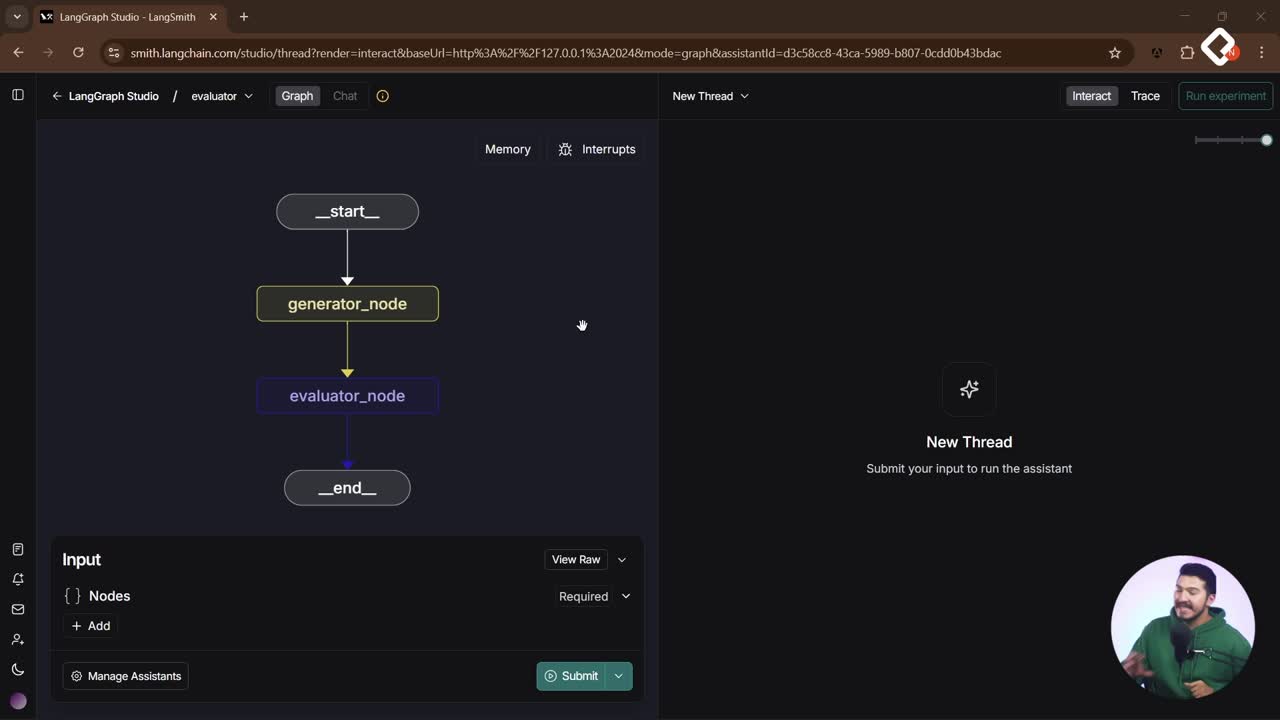
Evaluator Optimizer: ciclos de autocrítica para agentes de IA
12:48 min
Puesta en Producción
Structured Output para agentes en LangGraph
Resumen
Cuando un Large Language Model responde en texto libre, predecir su salida es casi imposible: cambia el tono, la longitud y el formato según el prompt y la temperatura. Para que un agente tome decisiones reales dentro de LangGraph, necesitas forzar al modelo a responder en un esquema estructurado tipo JSON. Esa técnica se llama structured output y es la base para construir nodos extractores que alimenten la memoria compartida de tu agente.
Por qué necesitas respuestas estructuradas en un agente
Un agente no solo conversa, también evalúa. Y para evaluar, requiere datos en variables tipadas, no párrafos.
El structured output permite que el modelo devuelva un objeto con campos definidos: un string para el nombre, un int para la edad, un enum para el sentimiento. Así puedes operar sobre la respuesta dentro de tu programa, tomar decisiones condicionales y guardar información en el estado del grafo [1:30].
¿Qué es structured output? Es una técnica que obliga al Large Language Model a responder siguiendo un esquema definido (por ejemplo, con Pydantic), en lugar de texto libre. La salida se entrega como un objeto con campos tipados listo para usar en código.
Esta es la diferencia entre usar el modelo como chatbot y usarlo como motor de extracción dentro de un pipeline. El nodo extractor, por ejemplo, recibe el historial completo de la conversación y devuelve un esquema con los datos relevantes del usuario.
Cómo elegir el modelo correcto para structured output
En la documentación de LangChain, dentro de Integrations > Chat Models, hay una tabla comparativa que muestra qué features soporta cada proveedor.
Las columnas más importantes que debes revisar son:
- Tool calling: si el modelo puede invocar herramientas externas.
- Structured output: si soporta respuestas con esquema, hoy lo soportan prácticamente todos.
- JSON mode: quedó obsoleto, structured output lo reemplazó [4:50].
- Local: si puedes correrlo en tu máquina con Ollama o Hugging Face.
- Multimodal: si acepta imágenes, PDF o audio como input.
Anthropic con Claude, OpenAI y la mayoría de integraciones soportan structured output, así que la decisión depende más de costo, velocidad y calidad para tu caso particular.
Cómo definir un esquema con Pydantic en LangGraph
Pydantic ya viene instalado con LangGraph y es la forma natural de modelar el esquema en Python. Cuando llamas a with_structured_output(schema), LangChain transforma esa clase en el formato que la API del proveedor necesita.
Un ejemplo de clase para un extractor de contacto:
python from pydantic import BaseModel, Field
class ContactInfo(BaseModel): name: str = Field(description="Nombre del cliente") email: str = Field(description="Email del cliente") phone: str = Field(description="Teléfono del cliente") age: str = Field(description="Edad del cliente") sentiment: str = Field(description="Sentimiento de la conversación")
La descripción de cada campo es crítica porque pasa a formar parte del prompt que recibe el modelo. Si la descripción es vaga, el modelo alucina; si es precisa, los datos extraídos son confiables [9:30].
Cómo invocar el modelo con el esquema
Después de definir la clase, el patrón es directo:
python llm = ChatAnthropic(model="claude-...") extractor = llm.with_structured_output(ContactInfo)
messages = [ ("system", "Eres un extractor experto. Dada una conversación, extrae la información siguiendo el esquema."), ("user", history) ] response = extractor.invoke(messages)
La respuesta ya no es un string, es una instancia de ContactInfo. Puedes acceder a response.name, response.phone y usarlo como cualquier objeto Python.
Cómo construir el nodo extractor en un agente RAG
El nodo extractor evalúa el historial cada vez que se ejecuta y guarda lo encontrado en la memoria compartida del grafo. La lógica básica recorre tres pasos.
- Lee el estado actual y verifica qué campos están vacíos:
customer_name,phone,age. - Si falta información o el historial supera cierto umbral (por ejemplo, 10 mensajes), llama al modelo con structured output.
- Devuelve el nuevo estado con los campos extraídos para que los nodos siguientes los usen.
¿Cómo evito gastar tokens en cada turno? Aplica una condición: ejecuta el extractor solo cuando el dato falte o cuando el historial crezca lo suficiente para reevaluarlo. Si ya tienes el nombre y el historial es corto, devuelves el estado sin llamar al modelo.
Esta condición es clave porque cada llamada al Large Language Model tiene costo. La regla típica combina dos señales: campo nulo o historial mayor a N mensajes [19:00].
Cómo manejar campos opcionales sin romper el esquema
Un detalle frecuente: si declaras age: int y el usuario aún no compartió su edad, el modelo intenta devolver null y Pydantic lanza error de validación.
Dos soluciones prácticas:
- Usar
stren lugar deintmientras la información llega. - Marcar el campo como
Optional[int]para permitir nulos.
También conviene agregar al prompt una instrucción clara: si no encuentras la información en la conversación, no la inventes. Sin esa línea, el modelo alucina datos como una edad inventada [13:40].
Cómo inyectar la memoria compartida en el prompt conversacional
Una vez el extractor llena el estado, el nodo conversacional puede usar esos datos para personalizar las respuestas. En lugar de un nombre hardcodeado tipo John Doe, el system prompt se construye dinámicamente.
python customer_name = state.get("customer_name", "John Doe") system = f"Eres un asistente. El cliente se llama {customer_name}."
messages = [ ("system", system), ("user", last_message) ]
El fallback a John Doe evita que el prompt quede roto cuando aún no hay datos. Más adelante conviene hacer el prompt totalmente dinámico: solo añadir la línea del teléfono si el teléfono existe, solo añadir la edad si la edad existe.
Este patrón separa responsabilidades. El nodo extractor se enfoca en obtener datos. El nodo conversacional se enfoca en responder. La memoria compartida los conecta.
Qué habilidades de prompting necesitas para que funcione
El structured output resuelve el formato, pero no la calidad de la extracción. Esa parte depende de tu prompt.
Técnicas útiles que conviene dominar:
- Zero-shot: dar instrucciones sin ejemplos.
- Few-shot: incluir ejemplos de input y output esperado.
- Chain of thought: pedir al modelo que razone paso a paso antes de responder.
El prompting sigue siendo la habilidad central de cualquier ingeniero de agentes, incluso cuando el output ya está estructurado. ¿Has probado combinar structured output con few-shot en tus propios extractores? Cuéntame en los comentarios cómo te fue.