Cuando terminas de limpiar y transformar tus datos, llega la pregunta clave: ¿qué te están diciendo realmente? La visualización de datos con Matplotlib te permite traducir miles de filas en gráficos que revelan patrones, tendencias y oportunidades que no verías solo mirando una tabla. Aquí trabajamos con un dataset de online retail ya procesado para construir gráficos de pastel y barras en Python.
¿Cómo identificar devoluciones en un dataset de ventas?
Antes de graficar, necesitas separar los datos. En un dataset de retail, las cantidades negativas suelen indicar devoluciones, mientras que las positivas representan ventas efectivas.
Para extraer las devoluciones, filtras tu DataFrame preguntando dónde la columna cantidad es menor a cero. Ese filtro produce un nuevo DataFrame con 8.872 transacciones devueltas. Para las ventas efectivas, aplicas el filtro contrario: cantidades mayores o iguales a cero [03:10].
¿Qué significa una cantidad negativa en un dataset de ventas? Representa una devolución. El signo negativo indica que el producto regresó al inventario en lugar de salir, así que filtrando por cantidad < 0 aíslas todas las devoluciones del periodo.
Usar shape[0] sobre cada DataFrame te devuelve el conteo exacto de filas, que es justo lo que necesitas para alimentar el siguiente gráfico.
¿Cómo crear un gráfico de pastel con Matplotlib?
Un pie chart es la forma más directa de mostrar proporciones entre dos o tres categorías, como devoluciones contra no devoluciones.
El flujo básico con matplotlib.pyplot es así:
Importas pyplot y defines la lista de labels con los nombres de cada porción.
Defines la lista de sizes con los totales numéricos de cada categoría.
Asignas una lista de colors, por ejemplo coral y verde claro.
Llamas a plt.figure(figsize=(8,8)) para fijar las dimensiones del lienzo.
Añades plt.title("Porcentaje de transacciones con y sin devolución") y cierras con plt.show().
Un detalle que cuesta caro: si defines la lista colors pero olvidas pasarla como argumento dentro de plt.pie(), Matplotlib usará la paleta por defecto. El parámetro startangle=140 rota el círculo para que el corte inicial quede en una posición visualmente cómoda [05:50].
El resultado revela que la proporción de devoluciones es muy pequeña frente al total de ventas, algo que no era evidente solo viendo los conteos.
¿Cómo graficar la distribución de ventas por mes y año?
Cuando ya tienes columnas de año y mes separadas, agruparlas te permite ver la evolución temporal del negocio.
El patrón con pandas y Matplotlib es:
Crear la figura con plt.figure(figsize=(12,6)).
Aplicar df.groupby(['año','mes'])['total_amount'].sum() para obtener la suma de ventas por periodo.
Encadenar .plot(kind='bar') directamente sobre el resultado.
Etiquetar con plt.title("Distribución de ventas por mes y año"), plt.xlabel("Año-Mes") y plt.ylabel("Ventas totales").
Al mirar el gráfico aparece una tendencia ascendente clara, pero el último mes (diciembre) cae respecto al anterior. Y aquí viene lo interesante: antes de concluir que las ventas bajaron, debes verificar si los datos del mes están completos o si solo capturaste una parte del periodo [08:30].
¿Por qué agrupar por año y mes en lugar de solo por mes? Porque agrupar solo por mes mezcla años distintos y oculta la evolución real. Agrupar por la combinación año-mes preserva la línea de tiempo y te deja ver tendencias de crecimiento o estacionalidad.
¿Cómo construir un top 10 de productos más vendidos en Python?
Para rankear productos necesitas combinar agrupación, ordenamiento y merge con la tabla de descripciones.
El proceso paso a paso:
Aplicas groupby('stock_code')['cantidad'].sum() para obtener el total vendido por código de producto.
Encadenas .sort_values(ascending=False) para ordenar de mayor a menor.
Tomas .head(10) para quedarte con el top 10.
Ejecutas reset_index() para limpiar los índices antes de graficar.
Haces pd.merge() entre tu top y el DataFrame limpio para traer la descripción de cada stock_code, eliminando duplicados con drop_duplicates(subset='stock_code') y usando how='left'.
Para el gráfico final, las barras horizontales funcionan mejor que las verticales cuando los nombres de producto son largos:
plt.figure(figsize=(12,8)) define el lienzo.
plt.barh(top_productos['descripcion'], top_productos['cantidad']) dibuja las barras.
plt.gca().invert_yaxis() invierte el eje Y para que el producto más vendido quede arriba [12:15].
Etiquetas los ejes con plt.xlabel("Cantidad vendida") y plt.ylabel("Producto").
Si quieres un top 3 en lugar de top 10, solo cambias el argumento de head() y el resto del pipeline se adapta solo.
Qué descubres cuando NumPy, Pandas y Matplotlib trabajan juntos
La fuerza de este flujo está en encadenar herramientas: NumPy maneja los cálculos, pandas organiza y filtra el DataFrame, y Matplotlib convierte ese trabajo en gráficos que comunican.
Graficar no es decoración, es diagnóstico. La caída de diciembre en las ventas, la mínima proporción de devoluciones y la concentración de unidades en pocos productos top son hallazgos que solo aparecen al visualizar. También puedes crear una columna categórica nueva clasificando el monto total en alto, medio o bajo, y graficarla en otro pastel para ver cómo se distribuye el ticket de tus clientes.
Ahora te toca a ti: aplica este mismo flujo al dataset que elegiste, comparte tus gráficos en los comentarios y cuéntanos qué patrón inesperado encontraste.
Yo elegí el data set "Student Study Performance" que lo encontré en Kaggle. Trata sobre: ¿Cómo el desempeño del estudiante se ve afectado por otras variables, como género, nivel de educación de los padres, almuerzo y curso de preparación para exámenes?. Me llevó su tiempo, pero aquí está:
🟢 Al infinito y más Matplotlib
Recuerda que el mundo de la graficación es muy variado. Inclusive con librerías como Seaborn que ofrecen mayor abstracción para resolver tus problemas de Análisis de Datos.
Algunos de los ejemplos que puedo recomendarte estudiar son:
Gráficas en 3D: útiles para relaciones de más de dos variables.
Mapas: para conocer la distribución de una variable según su geolocalización.
Matrices de calor: que muestran en qué lugares hay un valor más alto o más bajo para una variable. En el ejemplo a continuación, podrás ver una diagonal, esto sucede porque es una representación de la Matriz de Confusión, muy útil para evaluar modelos de Machine Learning.
Relieves: para conocer cómo está distribuida una zona según su altura.
Y muchos más… Así que, ¡nunca pares de aprender! 🚀🚀
excelente, deberían sacar otro curso aparte que nos permita profundizar.
Buen curso. Solo si pondría más atención en cositas que ya se dan por sentadas como ciertos métodos de las librerías, que no se explica del todo para que son.
Dejo uno de mis layouts sobre el análisis de ventas en una cafetería
Chatcito me ayudó a terminar de entender el código del merge:
¡Claro! Vamos a desglosar el código línea por línea para que entiendas bien qué hace cada paso.
Aquí se están agrupando los datos por StockCode y sumando la cantidad (Quantity) de cada producto. Luego, se ordenan en orden descendente (ascending=False) para obtener los productos más vendidos y se seleccionan los primeros 10 (head(10)).
El resultado de esta operación es una Serie de pandas, donde:
El índice es StockCode
El valor es la cantidad total vendida de cada producto
El problema es que después de la agrupación, StockCode es el índice, pero queremos que sea una columna normal.
El .reset_index() lo convierte en un DataFrame, moviendo StockCode de índice a columna y manteniendo Quantity.
Ahora tenemos los 10 productos más vendidos junto con su descripción.
Resumen
Este código obtiene los 10 productos más vendidos y luego les añade su descripción.
Los pasos son:
Agrupar por StockCode y sumar las cantidades vendidas.
Ordenar y tomar los 10 más vendidos.
Convertir la serie en un DataFrame con reset_index().
Hacer un merge con data_cleaned para obtener la descripción de los productos.
La importancia de la graficación de resultados en un proyecto de análisis de datos:
Facilita la comprensión: Los gráficos permiten visualizar patrones, tendencias y relaciones en los datos de manera clara y directa.
Comunicación efectiva: Transmiten hallazgos clave de forma rápida y accesible.
Identificación de patrones: Los gráficos ayudan a detectar correlaciones, anomalías y agrupamientos que podrían pasar desapercibidos en tablas.
Comparación de datos: Facilita la comparación entre diferentes variables, categorías o periodos de tiempo.
Detección de valores atípicos: Gráficos como Boxplot o Scatterplot son útiles para identificar datos anómalos.
Soporte visual para argumentación: El uso de gráficos refuerza las conclusiones del análisis con representaciones visuales, proporcionando evidencia solida a la hora de respaldar decisiones.
Espero este aporte les sea de utilidad 💜
Yo como set de datos elegí unos descargados de Metatraders5 con los que pude poner en practica lo visto
Para categorizar los valores numéricos de una columna tambien podemos usar .cut
comparto el codigo para el grafico de pastel por amountcategory
import matplotlib.pyplot as plt
import pandas as pd
import caso_practico_35 as cp
import matplotlib.gridspec as gridspec
gs = gridspec.GridSpec(1,2, width_ratios=[1,1])fig = plt.figure(figsize=(12,6))#datos del torta 1label =['Devoluciones','No devoluciones']values =[cp.total_returns, cp.total_non_returns]color=['lightcoral','lightgreen']explosion =(0,0)#Creación del torta 1totar1 = fig.add_subplot(gs[0,0])totar1.pie(values, labels=label, explode=explosion, colors=color, autopct='%1.1f%%', shadow=True, startangle=140, labeldistance=1.1, pctdistance=0.8)#para garantizar que sea un circulototar1.axis('equal')totar1.set_title('Ventas de 1')#Datos del torta 2label2 = cp.amount_categories.index
values2 = cp.amount_categories
torta2 = fig.add_subplot(gs[0,1])torta2.pie(values2, labels=label2,autopct='%1.1f%%')torta2.axis('equal')torta2.set_title('Ventas de 2')plt.tight_layout()plt.suptitle('Ventas de productos', y=1.05)plt.show()```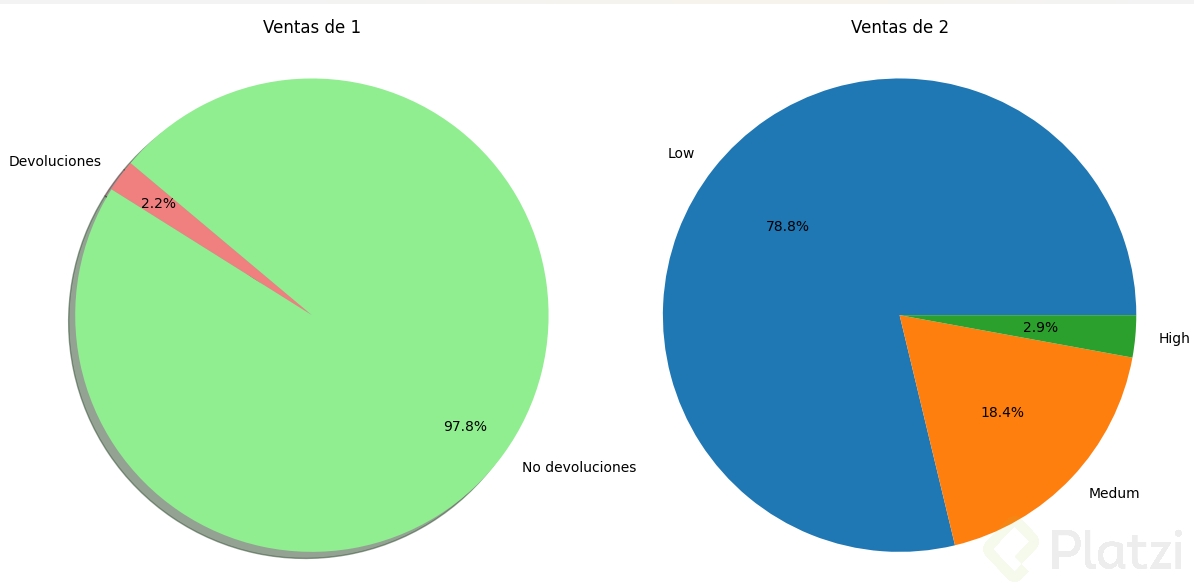
Companeros conocen plataformas donde se pueda aplicar a una vacante para begginers (semilleros) en datascience? les agradezco.
de este capitulo se deduce, que es importante limpiar los datos éticamente,
!Ejemplos en Matplotlib de 5 tipos de gráficos - Boxplot y scatter
MOdelo coworcountry o modelo coworculture con muchas actividades para pausas activas y acompañamiento de tu rol profesional Recuerda que Estamos enfocados en atender y brindar espacios para nomadas digitales, teletrabajo y coworking space en Agrolenials Paradise Ecohostel Country Inns contacto directo whatsapp +573206299333 y Faccebook
El método reset_index() en Pandas se usa para restablecer el índice de un DataFrame. Cuando lo aplicas, convierte el índice actual en una columna regular y crea un nuevo índice que comienza desde cero. Esto es útil cuando has realizado operaciones como el agrupamiento o la filtración que pueden haber alterado el índice original y necesitas un índice limpio para trabajar o para visualizaciones.
import matplotlib.pyplot as plt
labels =['Low','Medium','High']sizes =[data_cleaned['AmountCategory'].value_counts()['Low'], data_cleaned['AmountCategory'].value_counts()['Medium'], data_cleaned['AmountCategory'].value_counts()['High']]colors =['lightcoral','lightgreen','lightskyblue']plt.figure(figsize=(8,8))plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)plt.title('Distribución de Categorías de Monto de Transacción')plt.axis('equal')plt.show()```import matplotlib.pyplot as plt
labels = \['Low','Medium','High']sizes = \[data\_cleaned\['AmountCategory'].value\_counts()\['Low'], data\_cleaned\['AmountCategory'].value\_counts()\['Medium'], data\_cleaned\['AmountCategory'].value\_counts()\['High']]colors = \['lightcoral','lightgreen','lightskyblue']plt.figure(figsize=(8,8))plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)plt.title('Distribución de Categorías de Monto de Transacción')plt.axis('equal')plt.show()
excelente curso. muy detallado.
...
Gráfico de pastel adicional:
low_sales = df_clean[df_clean['AmountCategory']=='Low'].shape[0]medium_sales = df_clean[df_clean['AmountCategory']=='Medium'].shape[0]high_sales = df_clean[df_clean['AmountCategory']=='High'].shape[0]#Gráfico de total categorizado
labels =['Low','Medium','Hihg']sizes =[low_sales, medium_sales, high_sales]colors =['salmon','lightgreen','skyblue']plt.figure(figsize=(6,6))plt.pie(sizes, labels = labels, colors = colors, autopct ='%1.1f%%', startangle=140) #auopct añade los porcentajes al gráfico
plt.title('Distribución de ventas por monto')#plt.legend()plt.show()```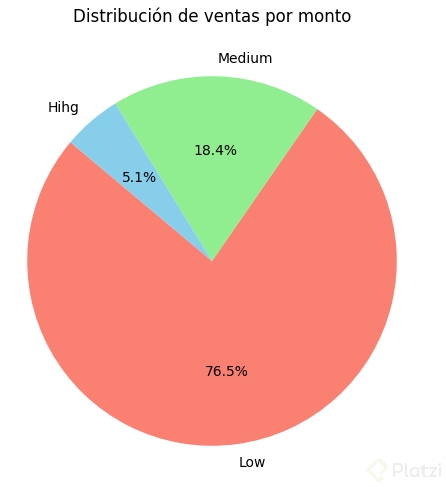
Excelente curso, ¡¡¡muchas gracias!! por compartir su conocimiento, ahora a colocar lo aprendido en practica.
La **graficación** y el **análisis de resultados** son componentes clave en cualquier proceso de análisis de datos. Utilizando bibliotecas como **Matplotlib** o **Seaborn**, puedes visualizar los patrones y tendencias en los datos, lo que facilita la interpretación de los resultados. Aquí te explico algunos tipos de gráficos comunes y cómo analizar los resultados visualmente.
### 1. **Gráficos de líneas (Line Plot)**
El gráfico de líneas es ideal para visualizar la evolución de una variable a lo largo del tiempo o en relación con otra variable.
#### Ejemplo: Graficar una serie temporal de precios
import matplotlib.pyplot as plt
import pandas as pd
\# Crear datos de ejemplo
data ={'Día': \[1,2,3,4,5],  'Precio': \[100, 102, 101, 105, 107]}df = pd.DataFrame(data)
\# Graficar
plt.plot(df\['Día'], df\['Precio'], marker='o')plt.title('Evolución del Precio')plt.xlabel('Día')plt.ylabel('Precio')plt.grid(True)plt.show()
#### Análisis:
- **Tendencia**: Puedes observar si los precios están aumentando, disminuyendo o fluctuando.
- **Patrones**: Si el gráfico muestra fluctuaciones recurrentes, podrías investigar ciclos o estacionalidad.
### 2. **Gráficos de dispersión (Scatter Plot)**
El gráfico de dispersión es útil para analizar la relación entre dos variables continuas.
#### Ejemplo: Relación entre edad y salario
\# Crear datos de ejemplo
data ={'Edad': \[25,30,35,40,45],  'Salario': \[2000, 2500, 3000, 3500, 4000]}df = pd.DataFrame(data)
\# Graficar
plt.scatter(df\['Edad'], df\['Salario'])plt.title('Relación entre Edad y Salario')plt.xlabel('Edad')plt.ylabel('Salario')plt.show()
#### Análisis:
- **Correlación**: Si observas que los puntos siguen una tendencia ascendente o descendente, esto sugiere una correlación positiva o negativa entre las variables.
- **Outliers**: Los puntos alejados del patrón general pueden indicar valores atípicos.
### 3. **Histogramas**
Un histograma muestra la distribución de una variable continua, útil para ver la forma de la distribución (simetría, sesgo, etc.).
#### Ejemplo: Distribución de la edad
\# Crear datos de ejemplo
edades = \[23,24,23,30,29,25,22,30,31,24,28]
\# Graficar
plt.hist(edades, bins=5, edgecolor='black')plt.title('Distribución de la Edad')plt.xlabel('Edad')plt.ylabel('Frecuencia')plt.show()
#### Análisis:
- **Sesgo**: Si los datos están sesgados a la derecha o izquierda, puede afectar cómo se interpretan los estadísticos como la media.
- **Distribución**: Ver si los datos son normales o siguen otra forma de distribución.
### 4. **Boxplots (Diagrama de Caja)**
Los **boxplots** son útiles para visualizar la dispersión de los datos, resúmenes estadísticos, y detectar outliers.
#### Ejemplo: Distribución de salarios
\# Crear datos de ejemplo
salarios = \[2000,2200,2100,2300,2800,3200,2500,3000,2700,2900]
\# Graficar
plt.boxplot(salarios, vert=False)plt.title('Distribución de Salarios')plt.xlabel('Salario')plt.show()
#### Análisis:
- **Rango intercuartílico**: El rango intercuartílico (entre el primer y tercer cuartil) muestra la dispersión central de los datos.
- **Outliers**: Los puntos fuera de los bigotes indican valores atípicos que podrían requerir atención especial.
### 5. **Gráficos de barras**
Los gráficos de barras son útiles para mostrar comparaciones entre diferentes categorías.
#### Ejemplo: Comparación de ventas en varias ciudades
\# Crear datos de ejemplo
ciudades = \['Ciudad A','Ciudad B','Ciudad C']ventas = \[1000,1500,800]
\# Graficar
plt.bar(ciudades, ventas, color=\['blue','green','red'])plt.title('Ventas por Ciudad')plt.xlabel('Ciudad')plt.ylabel('Ventas')plt.show()
#### Análisis:
- **Comparación**: Es fácil ver qué categoría (en este caso, ciudad) tiene el valor más alto o bajo.
- **Patrones**: Si las barras tienen un patrón claro, podría haber alguna relación subyacente que vale la pena investigar.
### 6. **Gráficos de pastel (Pie Chart)**
Los gráficos de pastel se utilizan para mostrar la proporción de categorías dentro de un total.
#### Ejemplo: Distribución de mercado por producto
\# Crear datos de ejemplo
productos = \['Producto A','Producto B','Producto C']participación = \[30,45,25]
\# Graficar
plt.pie(participación, labels=productos, autopct='%1.1f%%')plt.title('Participación de Mercado por Producto')plt.show()
#### Análisis:
- **Proporciones**: Se puede ver fácilmente qué categoría tiene la mayor o menor participación.
- **Balance**: Si el gráfico está equilibrado o dominado por una categoría, esto podría influir en decisiones de negocio.
### 7. **Subplots**
Puedes utilizar subplots para comparar múltiples gráficos en la misma figura.
#### Ejemplo: Gráfico de líneas y gráfico de barras en la misma figura
\# Crear datos de ejemplo
días= \[1,2,3,4,5]ventas = \[100,150,200,250,300]costos = \[90,120,180,220,260]
\# Crear subplots
fig, ax = plt.subplots(1,2, figsize=(10,5))
\# Gráfico de líneas
ax\[0].plot(días, ventas, marker='o', label='Ventas')ax\[0].plot(días, costos, marker='x', label='Costos')ax\[0].set\_title('Ventas y Costos')ax\[0].set\_xlabel('Día')ax\[0].set\_ylabel('Valor')ax\[0].legend()
\# Gráfico de barras
ax\[1].bar(días, ventas, color='green')ax\[1].set\_title('Ventas Diarias')ax\[1].set\_xlabel('Día')ax\[1].set\_ylabel('Ventas')plt.tight\_layout()plt.show()
### 8. **Análisis de resultados**
Una vez que hayas creado los gráficos, el análisis debe enfocarse en:
- **Identificar patrones**: Como tendencias crecientes, decrecientes o cíclicas.
- **Comparar variables**: Ver si existen relaciones entre diferentes variables.
- **Detectar outliers**: Valores extremos que podrían necesitar mayor investigación.
- **Interpretar la distribución**: Ver la forma de los datos para determinar si están sesgados o siguen una distribución normal.
### Conclusión
La visualización de datos con gráficos y el análisis de resultados son herramientas poderosas para entender los datos y comunicar hallazgos de manera clara y concisa. Con librerías como **Matplotlib** y **Seaborn**, puedes personalizar y analizar gráficamente cualquier conjunto de datos.
La graficación y el análisis de resultados son fundamentales para comunicar de manera efectiva los hallazgos derivados del análisis de datos. Una visualización clara y bien diseñada no solo facilita la interpretación, sino que también permite validar el análisis y hacer recomendaciones basadas en datos. Además, los gráficos pueden revelar patrones o insights que no serían evidentes a partir de tablas de datos o estadísticas resumidas, lo que los convierte en una herramienta indispensable para analistas, científicos de datos, y tomadores de decisiones.








