Private Attributes and Data Integrity in Python
Contenido del curso
Encapsulación y Comportamiento de Objetos
Implementar Protocolos con Métodos Especiales
Relaciones entre Clases y Polimorfismo
- 12
Book Search and Lending Flow in Python OOP
08:57 min - 13
Clases abstractas en Python con ABC y @abstractmethod
04:31 min - 14
Decoradores property en Python para atributos con validación
06:22 min - 15
Decoradores @staticmethod y @classmethod en Python
07:18 min - 16
Serialización de objetos Python a JSON para persistencia de datos
07:47 min
Diseño Avanzado y Patrones de Software
Private Attributes and Data Integrity in Python
Resumen
Picture walking into a bank to withdraw cash. You can't just stroll into the vault and grab whatever you want. You ask the teller, who checks your account and hands you the money if everything looks right. Encapsulation in Python works the same way: it shields the internal data of your objects and controls how that information gets used, making your classes safer through private attributes.
This matters if you're building anything where data integrity is non negotiable, like a library system tracking how many times a book has been borrowed.
What is encapsulation in Python and why does it matter?
Encapsulation is the principle that lets you hide the internal details of a class and control access to its data. In a library system, this is what keeps loan counts, availability flags, and other sensitive fields from being silently corrupted by code that shouldn't touch them.
Think of the bank analogy again. The teller is the method that validates your request before touching the vault. Without that intermediary, anyone could rewrite your balance.
What is encapsulation in Python? It's the practice of hiding internal attributes of a class and exposing them only through controlled methods, so external code can't break the object's integrity.
How does a popularity method reveal the integrity problem?
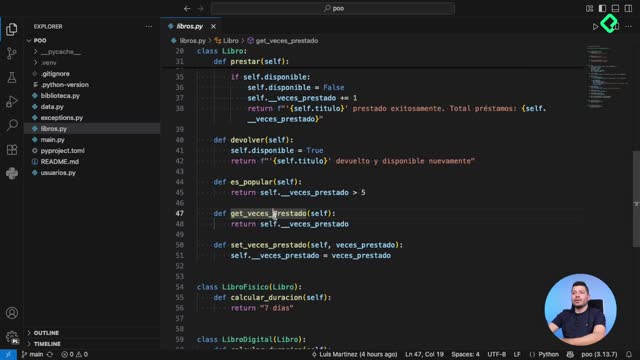
In the previous class, the challenge was to add an es_popular method that returns True if a book has been borrowed more than five times and False otherwise. The __init__ got a new veces_prestado parameter, and the prestar method increments it by one each time the book is loaned out [01:00].
A small fix shows up early: when a book isn't available, the prestar method returned None because the return statement only fired inside the availability check. Adding an explicit message like "this book is not available" replaces that confusing None output [02:10].
But the real issue appears when you do something like this from outside the class:
python mi_libro.veces_prestado = 10
Suddenly the total jumps to 11 after a single loan, even though the book was only borrowed once. The data lost its integrity because nothing stopped the external rewrite.
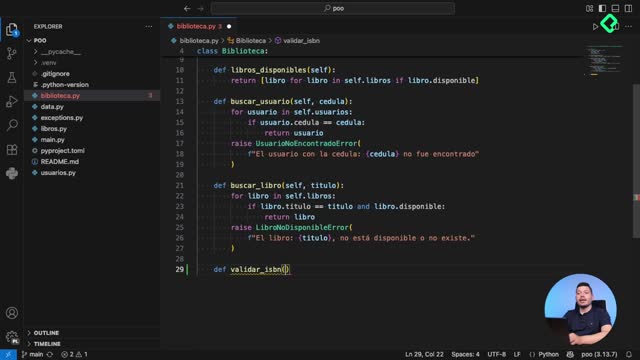
How do you make an attribute private in Python?
Python gives you two conventions to mark attributes as private, and they behave very differently.
- Single underscore (
_veces_prestado): a convention that signals "this is internal, don't touch it from outside." Nothing actually blocks access. If you runprint(mi_libro._veces_prestado), Python happily returns the value [03:30]. - Double underscore (
__veces_prestado): triggers name mangling. If external code tries to read or modify it directly, Python raises anAttributeErrorsaying the attribute doesn't exist on the object [04:00]. - No underscore: fully public, anyone can read and overwrite it.
The double underscore is what you reach for when you genuinely want to protect a field. After renaming the attribute to __veces_prestado everywhere inside the class, any outside attempt to assign or read it fails.
What's the difference between
_and__in Python attributes? A single underscore is a polite warning that the attribute is internal. A double underscore activates name mangling, which actively blocks direct external access.
When should you create a getter method?
If you still want to expose the value, you build a getter. The pattern looks like this:
python def get_veces_prestado(self): return self.__veces_prestado
Now external code calls mi_libro.get_veces_prestado() instead of touching the attribute directly. The win isn't just access, it's that you can add validations inside the method. This is the bank teller checking your balance before handing over the cash.
When do you need a setter method?
A setter lets controlled modifications happen from outside, with rules baked in. Imagine the librarian needs to import a historical loan count from another system:
python def set_veces_prestado(self, veces_prestadas): self.__veces_prestado = veces_prestadas
Calling mi_libro.set_veces_prestado(10) updates the internal value, and the getter confirms the change [05:40]. Inside that setter you can validate that the number isn't negative, isn't absurdly large, or matches business rules before the assignment happens.
How do you choose which attributes to encapsulate?
Not every variable needs protection. Encapsulation is gaining traction in Python codebases, but you'll find plenty of repositories that skip it entirely. The skill is knowing where it pays off.
Ask yourself a single question for each attribute: should an external user be able to modify this directly? If the answer is no, make it private and expose it through a getter and setter that enforce the rules you care about.
Good candidates for private attributes include:
- Counters that should only change through specific actions, like loan counts.
- Status flags that depend on internal logic, like availability.
- Identifiers or balances that need validation before any change.
Leave public the fields that genuinely have no rules attached, like a book's title or author once it's been created.
Which attribute in your current project would you encapsulate first, and what validation would you put inside its setter?