
Probablemente, al investigar qué necesitas para aprender machine learning te encuentras con programación, algoritmos y matemáticas avanzadas. Con eso puedo imaginar que llegan a tu mente imágenes de código y símbolos matemáticos extraños por todos lados.
Sin embargo, entender machine learning puede ser más sencillo de lo que parece, pero para ello necesitarás empezar por conocer tres conceptos esenciales: feature vectors, métricas de distancia y aprendizaje no supervisado. Te presentaré a cada uno de ellos y al terminar entenderás cómo funciona un algoritmo de machine learning. ¡Comencemos!
1. Feature vectors
Los feature vectors son representaciones numéricas de las características más importantes de objetos que existen en el mundo. Por ejemplo, para representar futbolistas que juegan en posiciones ofensivas dos de sus características más relevantes serían los goles y asistencias que tienen durante una temporada. Con esto puedes definir sus feature vectors de la siguiente forma:
jugador = [goles, asistencias]
2. Métricas de distancia
Una vez que tienes los feature vectors el siguiente paso será ubicarlos como puntos en un plano de coordenadas. Para no complicarte en entender el plano visualízalo como un mapa con dos líneas que indican los valores de las características de los objetos. Para el caso de los futbolistas la de abajo indicará goles y la de la izquierda asistencias. Los jugadores con más goles estarán más a la derecha y los que tengan más asistencias más arriba, lo que convierte a sus feature vectors en puntos con coordenadas X y Y.
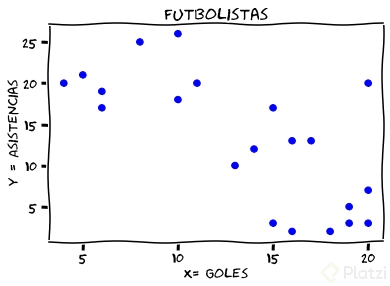
Ahora que los futbolistas están en el plano es cuando entran en juego las métricas de distancia. Estas son formas de medir la distancia entre dos puntos y una muy común es la euclidiana:
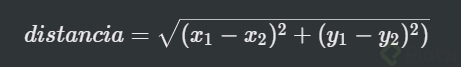
Asimismo, las métricas de distancia sirven para saber cuáles puntos son más cercanos entre ellos. Los de mayor cercanía tendrán características similares.
Finalmente, con las coordenadas de los futbolistas y la fórmula de distancia euclidiana podrías calcular la distancia entre los jugadores y así identificar por su cercanía a los de características similares. Sin embargo, esto puede no ser sencillo teniendo muchos jugadores y ninguna guía sobre cómo clasificarlos. Para ello utilizarás un algoritmo de aprendizaje no supervisado.
3. Aprendizaje no supervisado
El aprendizaje no supervisado se usa cuando tienes las características de tus objetos, pero no tienes alguna clase de etiqueta que diga a qué tipo pertenecen. Su función principal es agrupar los objetos por sus características empleando algoritmos de agrupamiento.
Uno de los más usados es el algoritmo K-means que se basa en centroides que representarán a cada agrupación. Cada centroide es un punto al que se asignarán los objetos más cercanos a él. Para el ejemplo de los futbolistas servirá para agruparlos en sus diferentes posiciones y funcionará así:
- Coloca a los futbolistas en el plano de acuerdo a sus feature vectors.
- Elige una cantidad de centroides y colócalos en el plano de forma aleatoria.
- Calcula la distancia de cada futbolista a cada uno de los centroides.
- Asocia cada futbolista con el centroide más cercano.
- Recalcula una nueva posición de cada centroide con base en el promedio de las coordenadas de los futbolistas asignados a él.
- Repite todos los pasos anteriores hasta que la suma de todas las distancias de cada futbolista con su centroide varíe muy poco con la veces anteriores.
Con una lista de 10 jugadores como la siguiente puedes aplicar el algoritmo de forma manual usando un número de centroides igual a 3 por las posiciones principales de futbolistas ofensivos: delantero, mediocampista y mediocampista ofensivo.
jugadores = [[20, 7], [8, 25], [18, 2], [20, 20], [16, 13], [17, 13], [10, 26], [19, 3], [11, 20], [6, 19]]
Como resultado obtendrás una gráfica como la siguiente donde los futbolistas son los puntos azules y sus centroides los rojos:
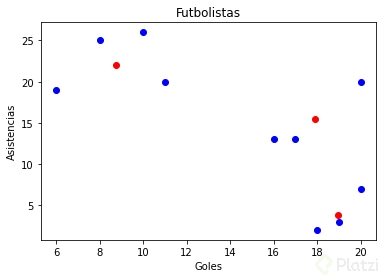
El problema de ejecutar el algoritmo de forma manual es que, incluso con solo 10 jugadores, hacer los cálculos a mano te tomaría mucho tiempo. Por ello la programación es crucial para ejecutar estos algoritmos. Utilizando Python y librerías como Scikit-learn puedes ejecutar código como el siguiente para obtener resultados de manera inmediata:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
jugadores = np.array([[20, 7], [8, 25], [18, 2], [20, 20], [16, 13], [17, 13], [10, 26], [19, 3], [11, 20], [6, 19]])
kmeans = KMeans(n_clusters=3, max_iter=1000).fit(jugadores)
print(f'Clasificación de jugadores: {kmeans.predict(jugadores)}')
centroides = kmeans.cluster_centers_
print(f'Coordenaas de Centroides: {centroides}')
for i in range(len(jugadores)):
plt.plot(jugadores[i][0], jugadores[i][1], 'ro', color='blue')
for i in range(len(centroides)):
plt.plot(centroides[i][0], centroides[i][1], 'ro', color = 'red')
plt.title('Futbolistas')
plt.ylabel('Asistencias')
plt.xlabel('Goles')
plt.show()
Con ese código ya tienes todo listo para ejecutar tu algoritmo. Puedes hacerlo ahora aquí y explorar su funcionamiento.
Profundiza en la teoría de machine learning
Apuesto a que pensabas que un código de machine learning sería mucho más largo, pero gracias a librerías existentes puedes simplificarlo de esa manera. Sin embargo, para hacerlo tan sencillo era necesario que se conozcan los tres conceptos esenciales que te he presentado.
¿Quieres profundizar en todos estos conceptos para desarrollar programas de machine learning? Completa el curso de introducción al pensamiento probabilístico y sigue avanzando en tu carrera de inteligencia artificial o ciencia de datos. #NuncaParesDeAprender. 🤖🤓
Curso de Introducción al Pensamiento Probabilístico
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


