NOTA: Este contenido fue lanzado para el reto Datacademy.
¡Hola, te doy la bienvenida a este tutorial! Aquí conocerás las instrucciones para crear el proyecto del reto Datacademy. 🤓
Ante de comenzar revisemos información importante del proyecto:
Ahora sí, comencemos. Sigue el paso a paso para crear tu proyecto.
Imagina que acabas de iniciar tu primer trabajo como Data Analyst para una nueva empresa de retail en Estados Unidos. Managers de ventas quieren conocer ciertos aspectos de otras empresas y te piden analizar datos de otras 25 compañías muy exitosas en el país.

Photo por Angela Roma de Pexels
Como dato, retail es el sector económico de empresas que se especializan en comercialización masiva de productos o servicios uniformes a grandes cantidades de clientes. Por ejemplo Walmart, Amazon, Target, Home Depot, Best Buy, etc.
Trabajaremos con un pequeño dataset que justamente tiene los datos de esas 25 compañías. Este dataset es una versión simplificada del dataset Largest US Retailers de Gary Hoover.
⬇ Para descargar esta versión del dataset en CSV haz clic aquí. ⬇
Importante: utiliza esa versión simplificada del dataset.
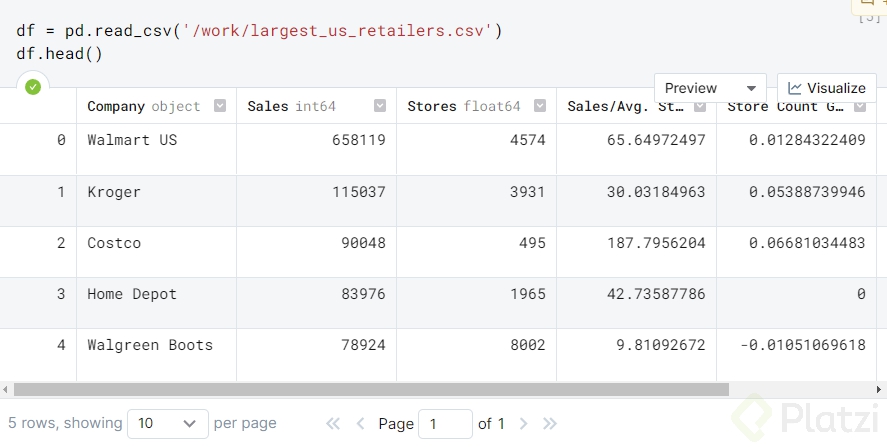
Dentro de este dataset encontrarás las siguientes variables/columnas:
Para crear tu proyecto es necesario utilizar Deepnote, ya que nos facilitará compartirlo con el mundo y entregarlo.
⬇ Descarga el template de notebook aquí ⬇
3.Dentro de la notebook que subiste a tu proyecto carga el CSV de los retailers que descargaste en el paso 1.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Imagina que los managers te hacen ciertas preguntas clave. Tu labor será responderlas buscando esos insights analizando los datos.
Para ello usa las cuatro librerías que acabas de importar que has conocido a lo largo de las clases del reto.
No existe una única sola forma de llegar al resultado, siéntete libre de explorar los datos como mejor te parezca con estas herramientas. Lo que importa al final es llegar a un resultado que sea de valor para el negocio.
La estructura que seguirás dentro del notebook será la siguiente. Para verla plantemos una pregunta sencilla que es ¿cuál empresa vendió más?
Ejecuta el código que necesites para llegar al resultado que necesitas.
Por ejemplo, para esta información podemos utilizar el método df.sort_values('x', ascending=0). Servirá para poner hasta arriba del DataFrame la compañía que más ventas tuvo.
df_sorted = df.sort_values('Sales', ascending=0)
df_sorted
Esto nos entregará el DataFrame de esta manera:
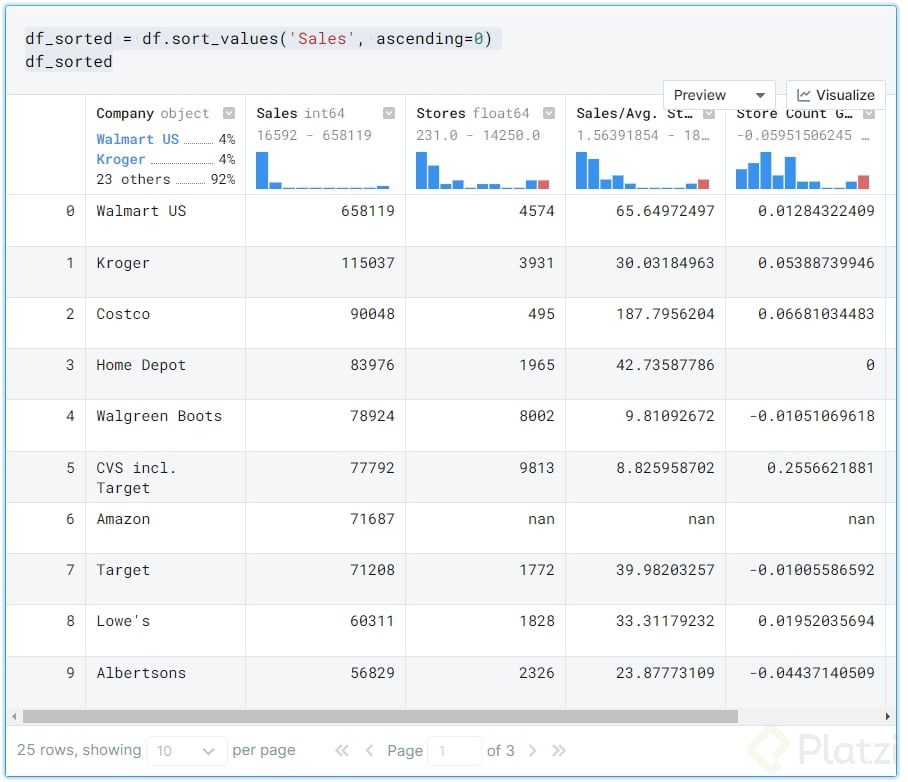
Claramente podemos ver que Walmart US es el que más ventas ha tenido con $658,119 millones de dólares.
Parece que con esto será suficiente, pero una visualización será de mayor valor y será más fácil de interpretar. Vamos a ello.
Con ayuda de Matplotlib o Seaborn crea una o las gráficas que necesites para dar a conocer tu resultado e incluso enriquecerlo.
Para este caso vamos a enriquecerlo mostrando los datos de ventas de las cinco compañías que más vendieron. Lo haremos de la siguiente manera:
x = df_sorted['Company'][0:5] #Aplicamos slicing como en una lista de Python.
y = df_sorted['Sales'][0:5]
plt.bar(x, y)
plt.title('Top 5 retailers')
plt.xlabel('Company')
plt.ylabel('Sales')
plt.xticks(rotation='vertical') #Método que se usa para rotar el texto de los puntos en X para que no se amontonen.
plt.show()
Obtendremos la siguiente gráfica:
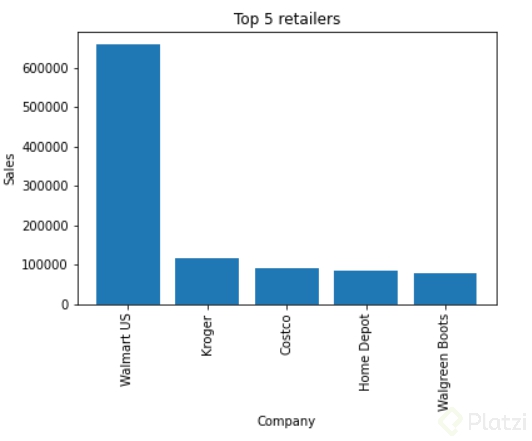
Esta gráfica además de mostrarnos que Walmart US es el que más ventas ha generado, también nos muestra que está dominando el mercado de retail superando al segundo lugar 5 veces más. Esto es un insight interesante y justo escribiremos nuestras conclusiones en el siguiente paso.
Debajo de tus resultados escribe conclusiones de lo que necesites resaltar de acuerdo a lo que observes. Utiliza esa intuición de los datos y dominio del negocio que tengas. Hazlo en una celda de texto en tu notebook.

Esto lo tendrás que hacer para cada una de las siguientes preguntas:
1. ¿Cuál es el promedio de ventas sin contar a la compañía dominante?
Pista: slicing
2. ¿Cuánto dinero en ventas generó la mayoría de las compañías?
Pista: hist.
3. ¿Cuántas tiendas tiene la mayoría de las compañías?
Pista: hist.
4. ¿La cantidad de tiendas está relacionada con la cantidad de ventas? Es decir, ¿si una empresa tiene más tiendas tendrá más dinero de ventas?
Pista: scatter.
5. ¿Cuál es el rango que existe entre las ventas?
Pista: max y min
6. ¿Cuáles son las 5 empresas que más tiendas físicas tienen? ¿Cuáles de ellas están dentro de las 5 empresas que más ventas tuvieron?
Pista: pregunta de ejemplo
Nota: puede que en algunos casos una visualización no sea necesaria, pero siempre puedes buscar como enriquecer tu resultado con ella.
Responde estas preguntas dentro de la primera sección de tu notebook.
Para elevar la dificultad del proyecto tenemos preguntas opcionales. Para resolverlas es probable que tengas que investigar más métodos de Pandas, NumPy y Matplotlib.
Si decides aceptarlas recuerda que tenemos dos tutoriales que podrán ayudarte:
Preguntas:
7. ¿Qué categoría de compañía generó más ventas?
8. ¿Cuál es la compañía que en relación con su cantidad de tiendas físicas genera más ventas?
9. ¿Cuáles compañías venden de forma exclusivamente online? ¿Sus ventas destacan sobre las que también tienen tiendas físicas?
De estas tres preguntas responde las que decidas aceptar dentro de la segunda sección de tu notebook con el mismo formato que las primeras. ¡Espero puedas resolverlas todas! 💪
De la misma manera en que has resuelto las preguntas anteriores, es momento de hacerle tus propias preguntas a los datos.
Comparte en la última sección de tu notebook de una a 3 preguntas de aspectos que te parezcan interesantes y relevantes de los datos.
¡Listo, has iniciado el camino para completar este primer proyecto de análisis de datos!





