En este artículo vas a aprender a aplicar estadística inferencial para obtener conclusiones de una población, a partir de una muestra. Usaremos un método de remuestreo llamado Bootstrapping, para el cual emplearemos Python.
Si no estás familiarizada o familiarizado con este poderoso lenguaje de programación, no te preocupes, el Curso Básico de Python tiene lo que necesitas para entender el código que veremos más adelante. Si aún no lo has tomado, ¿qué esperas para hacerlo?
Estadística inferencial vs. estadística descriptiva
Mientras que la estadística descriptiva sirve para entender las propiedades de un dataset de observaciones, la estadística inferencial permite inferir propiedades más allá de ese dataset, es decir, de una población entera. Pero, ¿cómo es que se logra inferir propiedades de algo más allá del alcance de un conjunto de datos? 🤔
Para que puedas interiorizar mejor lo que estás a punto de leer deberás tener bases sólidas de estadística descriptiva. Te recomiendo tomar el Curso de Matemáticas para Data Science: Estadística Descriptiva. Si ya lo hiciste, ¡muy bien!. Sigue leyendo. 👀

¿Qué es una población y una muestra estadística?
Supongamos, por ejemplo, que tenemos datos sobre la edad en la que las y los desarrolladores de software de LATAM consiguieron su primer empleo, tendríamos una muestra. ¿Sería correcto decir que el promedio de esa muestra es el promedio la población total de developers de LATAM? ⚠️ No. Y es aquí donde se hace útil la estadística inferencial. Vamos a inferir, a partir de una muestra, las características de una población total.
Entonces, las diferencias entre población y muestra son:
- Población → Es el grupo total que quieres describir.
- Muestra → Es una fracción representativa de la población.
Veamos un par de ejemplos para que quede más claro. ¡He preparado un notebook para que puedas interactuar con el código!
Un resumen con estadística descriptiva
Esta parte corresponde aún a estadística descriptiva y será útil para tener una idea de nuestra data y compararla con las inferencias. El dataset que utilizaremos es iris. Primero vamos a importar nuestras librerías.
- Pandas → para el manejo y transformación de datos.
- Matplotlib → para graficar en general.
- Seaborn → para hacer gráficas estadísticas especializadas.
- NumPy → para hacer computación científica.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
Ahora importamos iris usando Seaborn. Esto es un DataFrame.
>>> iris = sns.load_dataset('iris')
Siempre es buena idea ver algunas filas de nuestro DataFrame.
>>> print(iris.sample(5))
sepal_length sepal_width petal_length petal_width species
105 7.6 3.0 6.6 2.1 virginica
85 6.0 3.4 4.5 1.6 versicolor
11 4.8 3.4 1.6 0.2 setosa
122 7.7 2.8 6.7 2.0 virginica
81 5.5 2.4 3.7 1.0 versicolor
Bien, ahora vamos a hacer el resumen estadístico de nuestro dataset total. Emplearemos describe() para ello.
>>> print(iris.describe())
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
Este pequeño resumen nos da una idea de los datos que tenemos. Pero únicamente es para esta muestra. ¿Qué podríamos hacer si quisiéramos conocer los parámetros estadísticos de la población total? 👇🏽
Inferencia estadística: intervalos de confianza
Enfoquémonos ahora en una sola especie. Iris Versicolor. Para nuestro ejemplo, tomaremos la variable sepal_length que es el largo del sépalo. Hacemos una query al dataset.
>>> versicolor_sepal_length = iris.query('species == "versicolor"')['sepal_length']
Haz una pausa. Si se te dificulta un poco trabajar con Pandas, te recomiendo leer la Guía definitiva para dominar Pandas. 🐼
Obtenemos los estadísticos descriptivos, tanto en gráficas como en números.
#Distribución
>>> sns.boxplot(data=versicolor_sepal_length, x=versicolor_sepal_length.values)
>>> plt.xlabel('Longitud de sépalo')
>>> plt.title('Longitud de sépalo de Iris Versicolor')
>>> plt.show()
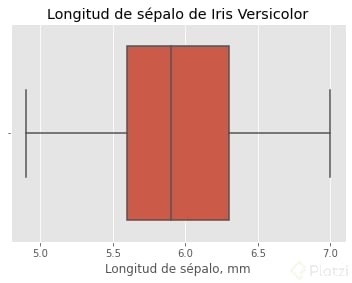
>>> versicolor_sepal_length.describe()
count 50.000000
mean 5.936000
std 0.516171
min 4.900000
25% 5.600000
50% 5.900000
75% 6.300000
max 7.000000
Nada nuevo aún, ¡eh! Pues ahora usaremos la media como estadístico y procedemos a buscar su valor en la población total. Para ello, emplearemos una técnica de remuestreo llamada Bootstrapping. Consiste en escoger valores aleatorios de la muestra y reemplazarlos, creando nuevos arrays. A estos nuevos arrays se les aplica el estadístico que estamos buscando (la media en nuestro caso).
¡Vas a hacer una simulación para repetir el experimento muchas veces! Para ello definiremos un par de funciones en python.
def bootstrap_replicate_1d(data, func):
"""Generar réplicas de datos 1D."""
bs_sample = np.random.choice(data, len(data))
return func(bs_sample)
def draw_bs_reps(data, func, size=1):
"""Obtener réplicas con bootstrap."""
# Inicializar un array de réplicas: bs_replicates
bs_replicates = np.empty(size)
# Generar réplicas
for i in range(size):
bs_replicates[i] = bootstrap_replicate_1d(data, func)
return bs_replicates
Para continuar, te dejo algunas definiciones clave que debes tener en cuenta.
- Bootstrapping → Usar datos remuestreados para generar inferencia estadística.
- Muestra de bootstrap → Un array remuestreado (simulado) de los datos reales.
- Réplica de bootstrap → Un estadístico obtenido de una muestra de bootstrap.
Con esto, procedemos a “repetir el experimento” de recoger datos sobre Iris Versicolor 10000 veces y luego computar la media.
>>> vers_replicates = draw_bs_reps(versicolor_sepal_length.values, np.mean, size=10000)
Esto nos devuelve un array de las medias calculadas de cada muestra simulada. Es decir, simulamos una muestra y a cada una de esta se le calcula la media. De este array definimos un intervalo de confianza del 95%.
>>> ci = np.percentile(vers_replicates, [2.5, 97.5])
>>> print(ci)
[5.794 6.076]
¿Cómo interpretamos los intervalos de confianza?
Si volviéramos a tomar las medidas de la longitud de sépalo de Iris Versicolor hay un 95% de probabilidad de que su media esté entre 5.794 mm y 6.076 mm. Por lo que podríamos decir que la media de la población total está entre estos dos valores con una confianza del 95%. Grafiquemos esto.
>>> plt.hist(vers_replicates, bins=20)
>>> plt.xlabel('Longitud de sépalo, mm')
>>> plt.ylabel('Frecuencias')
>>> plt.title('Réplicas bootstrap de las medias')
>>> plt.axvline(x=ci[0], color='#395d90')
>>> plt.axvline(x=ci[1], color='#395d90')
>>> plt.fill_between([ci[0], ci[1]], 1700, color='#395d90', alpha=0.6)
>>> plt.show()
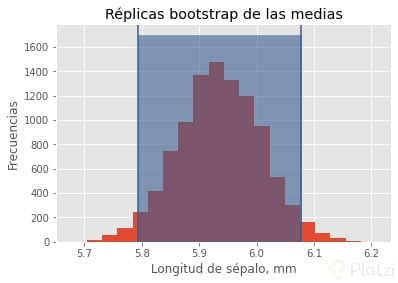
Hemos graficado la distribución de las medias de los datos simulados. El área sombreada es el intervalo de confianza, donde muy probablemente (95%) esté la media, si volviéramos a repetir la colecta de datos. ¡Hicimos una simulación computacional para inferir las características (media) de una población! Recuerda que puedes hacer lo mismo para otro estadístico como el valor máximo, desviación estándar o valor mínimo.
Prueba de hipótesis
Miremos ahora las distribuciones de sepal_length para las 3 especies. Enfoquémonos en la media de sepal_lengthde las especies Versicolor y Virginica. ¡Son diferentes!
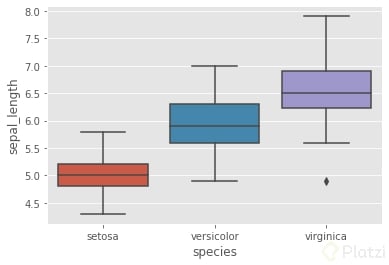
Como ya te lo estarás imaginando, no es del todo correcto concluir que el promedio del largo de sépalo Virginica es mayor que el largo de sépalo de Versicolor, porque esto es solo una muestra y los resultados pudieron ser solo por casualidad.
Por lo tanto, realizaremos un ejercicio de prueba de hipótesis usando Bootstrapping. Vamos a probar estadísticamente que esto no es pura coincidencia. Antes de hacerlo, tenemos que entender algunos conceptos:
- Hipótesis nula → La hipótesis nula es que la diferencia observada se debe únicamente al azar.
- Estadístico de prueba → Un número computado a partir de los datos observados y de los datos simulados. Es para hacer una comparación.
- Significancia estadística → Cuando hacemos una prueba de hipótesis, buscamos significancia estadística para aceptar o rechazar. Un resultado tiene significancia estadística cuando este tiene poca probabilidad de haber ocurrido dada la hipótesis nula. Para esto usamos el valor p.
- Valor p → Es la probabilidad de obtener un valor que sea al menos tan extremo como el observado, considerando que la hipótesis nula sea verdadera. Para que exista significancia, el valor p debe ser menor que 0.05, o en otros casos, menor que 0.01.
Teniendo esto en cuenta, postulemos nuestra hipótesis nula:
No existe diferencia entre el promedio de longitud de sépalo de Virginica y Versicolor.
Entonces, hacemos una query para extraer los datos que necesitamos.
>>> versicolor_sepal_length = iris.query('species == "versicolor"')['sepal_length']
>>> virginica_sepal_length = iris.query('species == "virginica"')['sepal_length']
Ahora, obtenemos la diferencia entre las medias observadas.
>>> observed_diffs_means = np.mean(virginica_sepal_length.values) - np.mean(versicolor_sepal_length.values)
>>> print(observed_diffs_means)
0.651999999999998
El siguiente paso es mover ambos arrays para que tengan la misma media, dado que estamos simulando una hipótesis donde sus medias son iguales. Para esto:
- Concatenamos los arrays y obtenemos su media.
- Extraemos la media propia del array y agregamos la media de los datos concatenados.
>>> versicolor_virginica_concatenated = np.concatenate((versicolor_sepal_length.values, virginica_sepal_length.values))
>>> mean_length = np.mean(versicolor_virginica_concatenated)
>>> versicolor_shifted = versicolor_sepal_length.values - np.mean(versicolor_sepal_length.values) + mean_length
>>> virginica_shifted = virginica_sepal_length.values - np.mean(virginica_sepal_length.values) + mean_length
Simulamos 100000 muestras para ambos arrays a las que les computamos la media.
>>> bs_replicates_versicolor = draw_bs_reps(versicolor_shifted, np.mean, size=100000)
>>> bs_replicates_virginica = draw_bs_reps(virginica_shifted, np.mean, size=100000)
Calculamos el estadístico de prueba que es la diferencia de medias:
bs_replicates = bs_replicates_virginica - bs_replicates_versicolor
Procedemos a graficar la distribución de diferencia de medias, así como el valor p que corresponde a la diferencia de medias de los datos observados.
>>> plt.hist(bs_replicates)
>>> plt.axvline(x=observed_diffs_means, linestyle='--')
>>> plt.fill_between([observed_diffs_means, 0.9], 35000, color='#395d90', alpha=0.6)
>>> plt.text(0.7, 25000, 'P-value')
>>> plt.title('Distribución de diferencia de medias', size=14)
>>> plt.ylabel('Frecuencia')
>>> plt.xlabel('Diferencia de medias')
>>> plt.show()
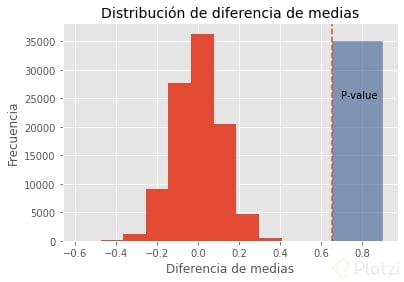
El valor p se ubica en el extremo derecho de nuestra distribución. Lo calculamos y sacamos una conclusión a partir de esto.
>>> p = np.sum(bs_replicates >= observed_diffs_means) / 100000
>>> print(p)
0.0
¡Obtenemos un valor p igual a 0! Esto es valor p < 0.005 lo que nos da significancia para no aceptar la hipótesis de que no existe diferencia entre el promedio de longitud de sépalo de Virginica y Versicolor. Por lo tanto, las diferencias observadas no son debidas al azar.

Ahora tienes una herramienta más en tu toolkit de data scientist. Cuéntame, ¿qué otras aplicaciones de estadística inferencial con Python se te ocurren? Me encantará leer tus ideas. Te invito a explorar esta ruta de cursos para data science con python.
Curso de Estadística Inferencial para Data Science e Inteligencia Artificial
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE