

La transformación digital nos reta a adaptarnos constantemente, y el machine learning es parte de esas nuevas herramientas que hay que conocer.
Aunque estemos acostumbrados a verlo en películas y series, la nueva era de la inteligencia artificial ya ha llegado y trae consigo nuevas oportunidades de aprendizaje para todas las áreas profesionales. Lo que en el pasado era ciencia ficción, en el presente es el siguiente paso.
Conoce las ventajas y desventajas de la inteligencia artificial
Qué es machine learning y para qué sirve
El machine learning (ML) es una rama de la inteligencia artificial en la cual los ordenadores aprenden de forma autónoma a entender los datos y comportamientos de forma parecida a como lo hacen los seres humanos, tratando de imitarlos. Así, mejoran a partir de los datos y experiencias que recogen.
A través de algoritmos de aprendizaje automáticos, las computadoras pueden identificar patrones en grandes cantidades de datos para realizar análisis, solucionar ciertos problemas o predecir escenarios.
Definitivamente, no es ciencia ficción, pues el machine learning, que en español significa aprendizaje automático, está más relacionado a la ciencia de datos que a las películas.
Atrévete a aprender más sobre este tema en el Curso de Introducción a Machine Learning, ¿emprendemos esta aventura?
Aprendamos cómo funciona el machine learning
El aprendizaje automático funciona mediante algoritmos matemáticos, que procesan grandes cantidades de datos para generar reconocimiento de patrones y así, aprender de manera autónoma, tareas específicas.
El proceso de aprendizaje de una computadora mediante un modelo machine learning empieza por recolectar datos, pasa por una hipótesis y modelado de datos para seguir al entrenamiento. Finalmente viene la etapa de evaluación, producción y ajuste del modelo.
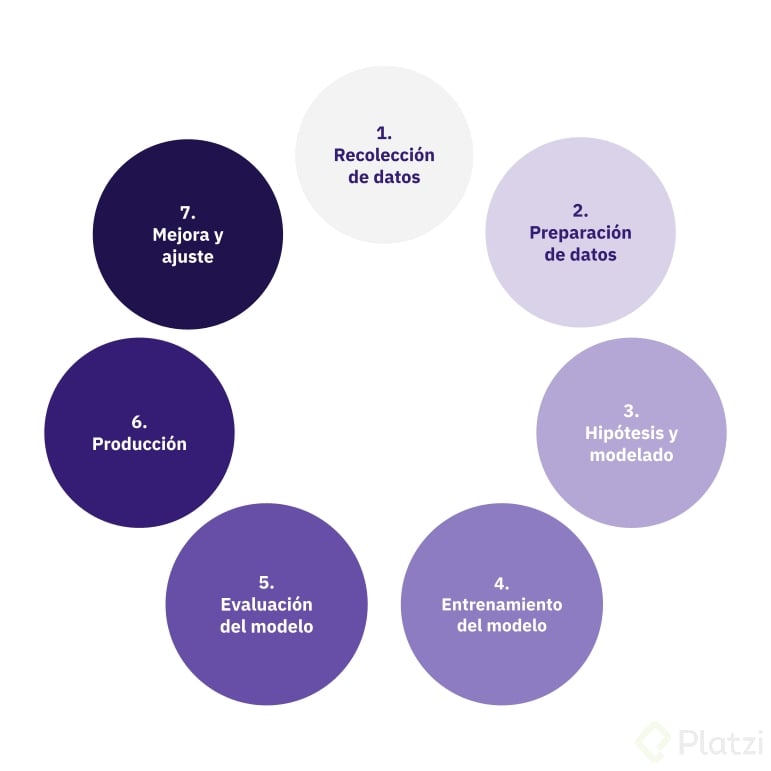
1. Recolección de los datos
El primer paso es recopilar los datos que se utilizarán para el entrenamiento. Estos podrían ser cualquier cosa, desde imágenes de gatos y perros para un modelo de reconocimiento de imágenes hasta datos de ventas anteriores para un modelo de predicción de ventas.
Necesitas una gran cantidad de datos de diversas fuentes; desde bases de datos hasta sensores y usuarios.
2. Preparación de los datos
Los datos recopilados deben ser preparados para el entrenamiento. Esto puede implicar la limpieza (eliminar los irrelevantes), la transformación (convertirlos en un formato que la máquina pueda entender) y la separación de los datos en conjuntos de entrenamiento y pruebas.
Los datos de entrada defectuosos solo producirán resultados defectuosos (llamado ‘Basura entra, basura sale’).
3. Hipótesis y modelado
Existen diferentes modelos de Machine Learning. Cada modelo es una versión simplificada de la realidad.
4. Entrenamiento del modelo
En este paso, se alimenta a la computadora con los datos de entrenamiento. Estos a menudo vienen con respuestas (o “etiquetas”) que le muestran a la computadora qué es lo que está buscando.
Por ejemplo, si estás entrenando un modelo para diferenciar entre imágenes de gatos y perros, podrías darle a la computadora un montón de imágenes de gatos y perros que ya están etiquetadas como “gato” o “perro”.
5. Evaluación del modelo
Una vez que la computadora ha sido entrenada, se la pone a prueba utilizando el conjunto de datos de prueba que se habían separado inicialmente. Esta etapa sirve para ver cuán bien ha aprendido el modelo y si puede hacer predicciones precisas por sí sola.
6. Producción
Si todo salió bien con la evaluación, es hora de llevar el modelo a producción.
7.Mejora y ajuste del modelo
A medida que la computadora pasa por los datos de entrenamiento, trata de ajustar sus propios cálculos y algoritmos para hacer que sus propias predicciones se acerquen a las respuestas correctas.
Este es un proceso iterativo, la computadora seguirá ajustándose hasta que sienta que puede hacer predicciones precisas por sí misma. Es esencial recoger continuamente nuevos datos y reentrenar el modelo para adaptarlo a las nuevas realidades.
Conoce los tipos más importantes de inteligencia artificial.
Entiende cómo se clasifican los modelos de aprendizaje automático
¿Cómo pueden procesar toda la información las computadoras? Existen diferentes estilos de aprendizaje, siendo los más comunes los siguientes:
1. Aprendizaje supervisado
En este tipo de aprendizaje, se realiza un proceso conocido como entrenamiento, en el cual la máquina recibe por primera vez una cierta cantidad de datos etiquetados para que la computadora detecte patrones que le permitan determinar qué aprender y realizar análisis predictivos o tomar decisiones.
Luego de este entrenamiento, el software podrá recibir nuevos datos sin etiquetar, los categorizará automáticamente, pues ya ha aprendido del proceso previo y sabe hacer esta tarea específica.
2. Aprendizaje no supervisado
Este modo de aprendizaje es similar al que tiene el cerebro humano al momento de procesar información. En este entrenamiento, la computadora es capaz de identificar las características que tienen en común un conjunto de datos no etiquetados para encontrar patrones y agreuparlos de acuerdo a características que tengan en común.
3. Aprendizaje semisupervisado
El análisis semisupervisado es aplicado, generalmente, cuando hay una gran cantidad de datos que no están estructurados.
La diferencia entre los dos análisis anteriores y este, es que se utiliza una cantidad de datos más pequeña (etiquetados y no etiquetados) para enseñar a la máquina a clasificar y extraer la información y patrones.
4. Aprendizaje por refuerzo
En esta técnica de machine learning, el algoritmo utiliza la experiencia para aprender a través de las premisas de prueba y error. Es decir, la computadora es expuesta a distintas situaciones o entornos en los cuales intentará dar con la respuesta correcta.
Esta técnica es utilizada por empresas como Microsoft, pues recompensan al software cuando hace un buen trabajo, orientándolo así a dar con la respuesta.
¿Cuál es la diferencia entre inteligencia artificial y machine learning?
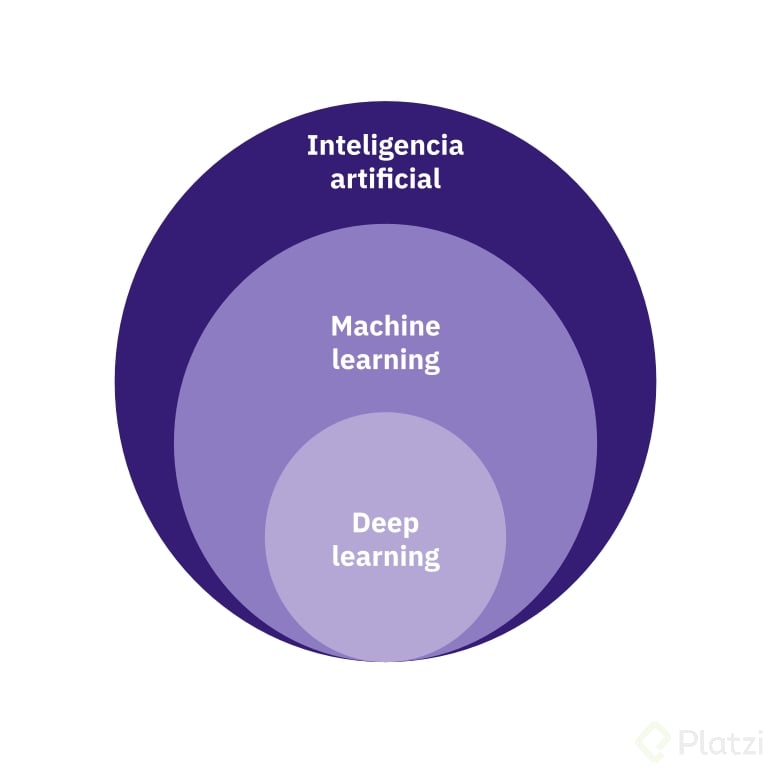
Machine learning (aprendizaje automático) e Inteligencia Artificial (IA) no son lo mismo, pero están estrechamente relacionados.
IA es un término general que se refiere a cualquier cosa que haga una máquina que requiera inteligencia humana. Machine learning, es un sub-campo o una manera específica y eficaz de acercarnos a la inteligencia artificial, a través del entrenamiento de modelos y el uso de datos.
En otras palabras, machine learning es un método para lograr la IA.
Otro término común que suele confundirse es deep learning. Podemos encontrarlo clasificado como una variante del machine learning o como una subcategoría. Lo cierto es que un aprendizaje profundo implica redes neuronales artificiales que emulan el cerebro humano para aprender, sin intervención humana, de grandes cantidades de datos.
Interesante, ¿verdad? Te dejamos este blog sobre Deep Learning vs. Machine Learning y 6 algoritmos de machine learning más importantes para que continúes aprendiendo.
Ejemplos de machine learning: conoce sus aplicaciones prácticas
La inteligencia artificial y el machine learning han proporcionado la innovación necesaria para propulsar una nueva generación de tecnologías, trayendo consigo la modernización y la transformación digital en distintos sectores.
Desde la detección temprana de enfermedades en la medicina, hasta vehículos autónomos como el coche inteligente de IBM, el machine learning está presente en todos lados. Exploremos varios de sus usos.
1. Posicionamiento en motores de búsqueda
Este tipo de machine learning procesa los datos históricos generados a raíz de la búsqueda de los usuarios en la plataforma. Es decir, aprende de los patrones y el comportamiento de los usuarios para ofrecerles mejores resultados personalizados en sus búsquedas.
Puedes ver este tipo de algoritmo al buscar algo en Google, en las sugerencias de Netflix, Spotify, o en redes sociales como X (antes Twitter) o Instagram. En algunos casos, el machine learning es aplicado por profesionales del marketing para mostrarle al público estudiado publicidad en tiempo real.
2. Procesamiento de lenguaje natural (PLN o NLP)
Este procesamiento es la comprensión, a través de texto y datos, del lenguaje humano. Su aplicación es amplia, puede ser usado para la traducción instantánea de textos, para clasificar documentos o textos, o en chatbots.
Así, asistentes virtuales como Siri (Apple) o Alexa (Amazon) pueden escuchar y reconocer tu voz, así como detectar intenciones y responder a tus preguntas. Es más, los LLM y tecnologías como ChatGPT son resultado de años de desarrollo de este campo de la IA.
Crea y entrena a tu propio chatbot con nuestro Curso de Desarrollo de Chatbots con OpenAI y utilízalo para agilizar las actividades de tus clientes en estas plataformas donde tu bot puede triunfar.
3- Ciberseguridad
El objetivo del área de la ciberseguridad es proteger los equipos, aplicaciones y datos confidenciales de malwares y amenazas. Gracias al machine learning, es posible detectar tempranamente amenazas cibernéticas, basándose en probabilidades aprendidas en el proceso de análisis de datos con información de experiencias pasadas.
¿Es el machine learning el futuro?
Aunque aún falta un largo camino por recorrer, y la aplicación del aprendizaje automático no está generalizada a nivel global, es cierto que el machine learning ya está presente en diversas áreas de nuestra vida.
Su uso en la detección de rostros e imágenes, el uso de chatGPT, predicciones y segmentaciones dentro del campo de la ciencia de datos, ha traído consigo novedades y mejoras en estos campos.
Aunque haya opiniones encontradas sobre este punto, la aplicación del machine learning traerá consigo nuevos desafíos a los cuales debemos adaptarnos para aprovechar los softwares que permitan automatizar las tareas para trabajar de una manera más eficiente.
Por eso es que aprender a utilizarla de la mejor manera puede cambiar por completo tu futuro. Descubre todo de lo que eres capaz e inicia con estas rutas de aprendizaje:
El mundo avanza constantemente y tú también puedes hacerlo. ¡Sigamos aprendiendo juntos!
Curso de Fundamentos de AI para Data y Machine Learning
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE

