Desde hace siglos la humanidad ha intentado mejorar los métodos con los que resolvernos operaciones matemáticas o realizamos cálculos, estos vienen desde civilizaciones como la egipcia, griega, árabe y muchas otras culturas. Por supuesto, cabe resaltar que este proceso es bastante complicado.
Imagina que te dieras a la tarea de inventar un nuevo método para sumar, multiplicar o realizar operaciones de producto entre matrices.
¿Bastante complicado, verdad? Pues el 05 de octubre de este año, DeepMind nos presentó a AlphaTensor el modelo de AI que es capaz de lograrlo.

El impacto en la inteligencia artificial
Llevamos más de 50 años resolviendo la operación de producto entre matrices de una misma manera. Específicamente, este problema es muy importante en la actualidad, pues la operación entre matrices o vectores es fundamental en cómo funcionan las redes neuronales y la inteligencia artificial en general.
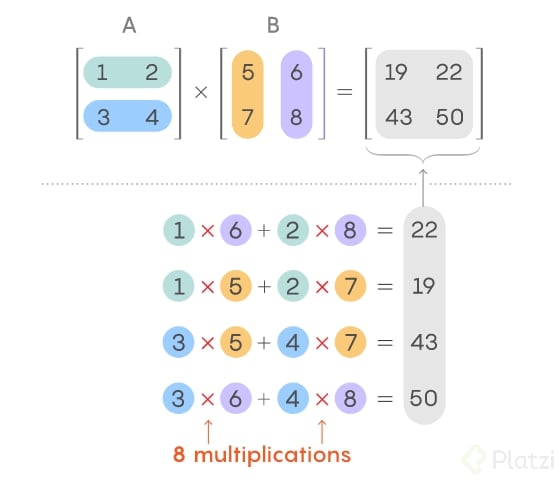
Todo el procesamiento de una red neuronal artificial se basa en encontrar ciertos “pesos” que satisfagan la solución de un problema. En este desarrollo se resuelven un sin número de operaciones de producto entre tensores, que básicamente son arreglos de matrices con alta dimensionalidad. Esto se usa para:
- Secuencias de código como AlphaCode
- Análisis de secuencias de texto como GPT3 o PaLM
- Generación de imágenes o arte digital como Stable Diffusion o Dalle2
- Voz a Texto y traducciones como Whisper
Básicamente, todos los modelos de inteligencia artificial más nombrados en los últimos años lo usan y gastan mucho tiempo y dinero resolviendo este tipo de operaciones y AlphaTensor encontró un método más rápido de resolverla. De este modo, es literalmente inteligencia artificial, creando desde cero métodos para mejorar la inteligencia artificial🚀🤯, algo como la siguiente ilustración.
Si quieres saber más de este tema, te invito a tomar el Curso de Fundamentos de Redes Neuronales con Python y Keras en donde explico desde cero como funciona la red neuronal.
¿Cómo se entrenó AlphaTensor?
En esencia, se toma este problema de producto entre tensores como un juego!!! Así es, un juego de movimientos como lo es ajedrez, go o shogui.
La gran ventaja del equipo de DeepMind es que tienen a AlphaZero, una inteligencia artificial que, apoyada de aprendizaje por refuerzo, puede aprender a “jugar” este tipo de juegos a un nivel incluso superior al profesional 🤯
AlphaTensor se construye sobre AlphaZero y su objetivo es resolver una secuencia de movimientos sobre un tensor de 3 dimensiones. Al resolverlo, se concluye que el jugador resolvió la operación de producto y solo hace falta tomar el número de pasos que necesitó para lograrlo.
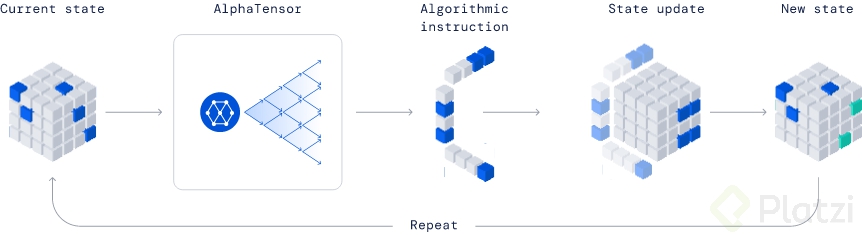
El problema es que es increíblemente complicado, hay tantas posibles soluciones o algoritmos a usar como átomos en el universo y, AlphaTensor parte totalmente desde cero sin saber como resolver este “Juego”. Por eso, con el aprendizaje por refuerzo se entrena una y otra vez el modelo con sus aprendizajes previos, consiguiendo así siempre una mejor versión de sí mismo. Esto es literalmente aprender de los errores 😛
¿El resultado al entrenar AlphaTensor?
AlphaTensor logró resolver una operación entre matrices en 76 pasos, que con el método escolar tomaría 100 pasos y 80 pasos con el mejor modelo actual en el estado del arte (algoritmo de Volker Strassen).
Lo sé, no parece mucha la diferencia, pero esto es un avance en un problema de más de 50 años y abre la puerta a inteligencia artificial más rápida y eficiente, lo que nos va a traer muchos más algoritmos maravillosos y con menos necesidad de cómputo. 💚

Y claro dejo algunos enlaces que te pueden interesar:
¡Sígueme en Instagram/Twitter/TikTok como @alarcon7a, y charlemos de temas relacionados con datos e inteligencia artificial! 🙂
Curso de Fundamentos de Redes Neuronales con Python y Keras
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE