

Previamente hablamos de Stable Diffusion, una inteligencia artificial libre para generar imágenes basadas en texto o prompts al nivel de modelos como Dalle 2 e Imagen.
Al ser un modelo gratuito se ha utilizado en un gran número de aplicaciones y permite a la comunidad experimentar con él. En uno de estos experimentos se integró con DreamBooth, un modelo desarrollado por Google para hacer un entrenamiento personalizado a modelos de difusión obteniendo estos resultados:

Así es, mi rostro (y muy posiblemente el tuyo) en distintos estilos, técnicas de dibujo, formas y básicamente la creatividad de tu prompt es el límite.
En este blog aprenderás cómo replicarlo totalmente gratis, pero antes, algo de contexto sobre cómo se llegó a estos resultados. 🚀
¿Qué es DreamBooth?
DreamBooth es una técnica desarrollada por el equipo de Google para personalizar entrenamientos de modelos generadores de imágenes.
Básicamente, consiste en entregar cierta cantidad de imágenes al modelo y también el concepto que representa. Por ejemplo, si quiero personalizarlo con mi rostro que es el de una persona, entonces el concepto es “person”. Si lo hago con mi mascota que es una perrita, el concepto será “dog”, con un reloj, el concepto será “clock”.
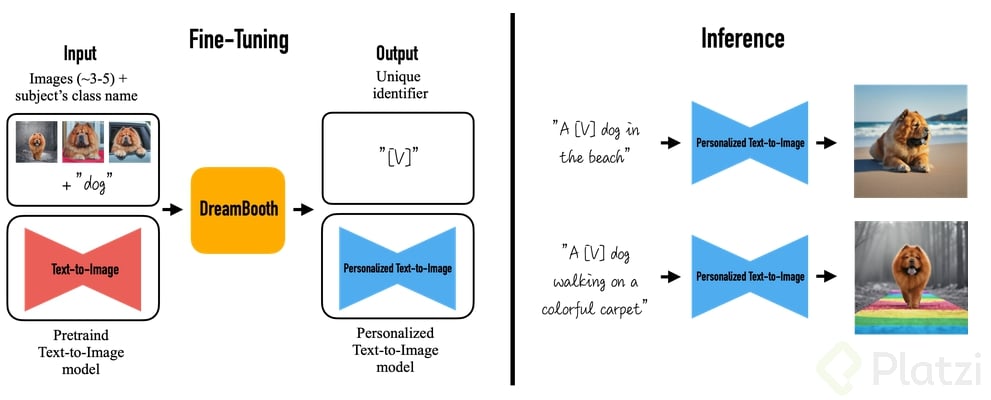
DreamBooth genera una representación personalizada del nuevo concepto con el que se le entrenó, por ejemplo, alarconc person y lo asocia a las imágenes que se proporcionaron.
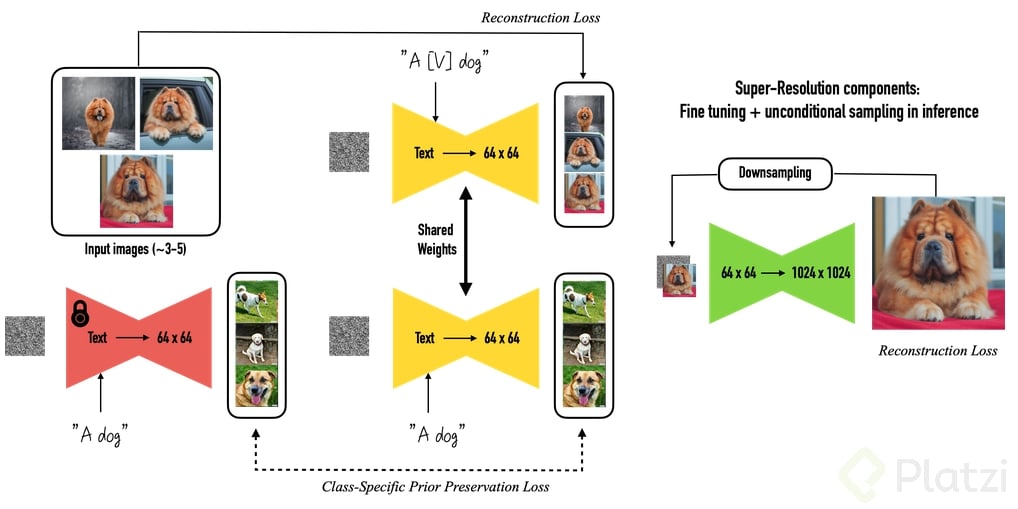
También a su vez entrena la red con el concepto que se le indico, ya sea “person”, “dog” o el caso que sea el cual servirá como regularizador, con el fin de que sea capaz de diferenciar el concepto nuevo que se le enseña como el de la clase global (“person”, “dog”, “clock”…etc), en el proceso final la red neuronal aprende a crear esos conceptos nuevos con una resolución superior.
Entrenar el modelo
La inteligencia artificial avanza a pasos agigantados. El día que entrené este modelo era necesario contar con al menos con 24 GB de GPU (unidad de video), lo que sería más o menos como una tarjeta gráfica nvidia 3090 que no tenía.
Así que simplemente utilice una instancia virtual en AWS (EC2) con las características que requería, monte un entorno de anaconda con Docker y seguí los pasos de este repositorio https://github.com/JoePenna/Dreambooth-Stable-Diffusion, los resultados de este entrenamiento son mejores que los de que se pueden obtener con google colab, pero el proceso es mas complicado y cuesta dinero ya que se debe alquilar procesamiento en la nube, pero si en local cuentas con al menos 24 GB de GPU te invito a seguir los pasos del repositorio mencionado anteriormente, de no ser asi en este blog te enseño paso a paso como hacerlo en google colab totalmente gratis y con muy buenos resultados!!! 🚀
Como ves, conocer de cloud computing y docker también trae muchas ventajas en ciencia de datos así que te invito a tomar los cursos de fundamentos de aws y docker
¿Cómo puedes usar DreamBooth?
Hoy 3 de octubre de 2022, no es necesario 24 GB de GPU, se requiere menos de 12 y es lo suficiente para ejecutarlo con google colab. Estos son los pasos a seguir:
1. Crea una cuenta en HuggingFace 🤗
HuggingFace es la mayor comunidad de inteligencia artificial libre, en ella puedes encontrar, modelos pre entrenados, spaces, datasets y muchos recursos mas.
2. Acepta en este enlace --> términos y condiciones del modelo 1.5 de Stable Diffusion
Stable Diffusion es un modelo muy potente y con grandes cambios en la economía actual por eso hay que aceptar los términos y condiciones de su uso y conocer sus limitantes y sesgos, actualmente no se necesita confirmacion de terminos, de modo que si no te sale para aceptarlos, no pasa nada y puedes continuar con el tutorial
3. Genera un Token en HuggingFace:
Si ya lo tienes solo hace falta copiar el token, que se usará más adelante.
4. Abre el siguiente enlace de Google Colab
Es un notebook creado previamente que contiene todo lo necesario para ejecutar el entrenamiento
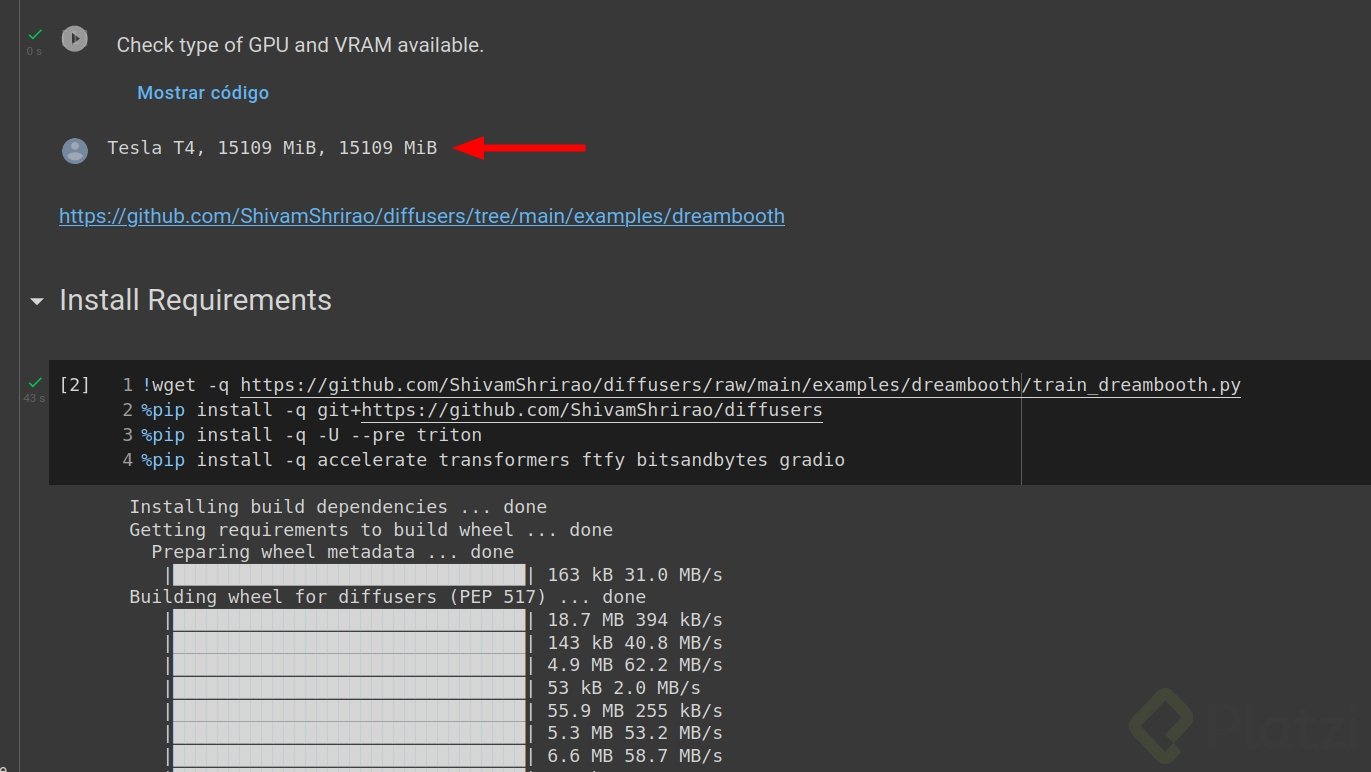
5. Ejecuta las primeras celdas y valida que tengan esta salida
es importante que se este ejecutando un entorno de trabajo con GPU para el entrenamiento.
6. Continúa ejecutando hasta llegar a Login to HF and run:
En esta sección debes ejecutar la celda y copiar el token generado en el paso 3

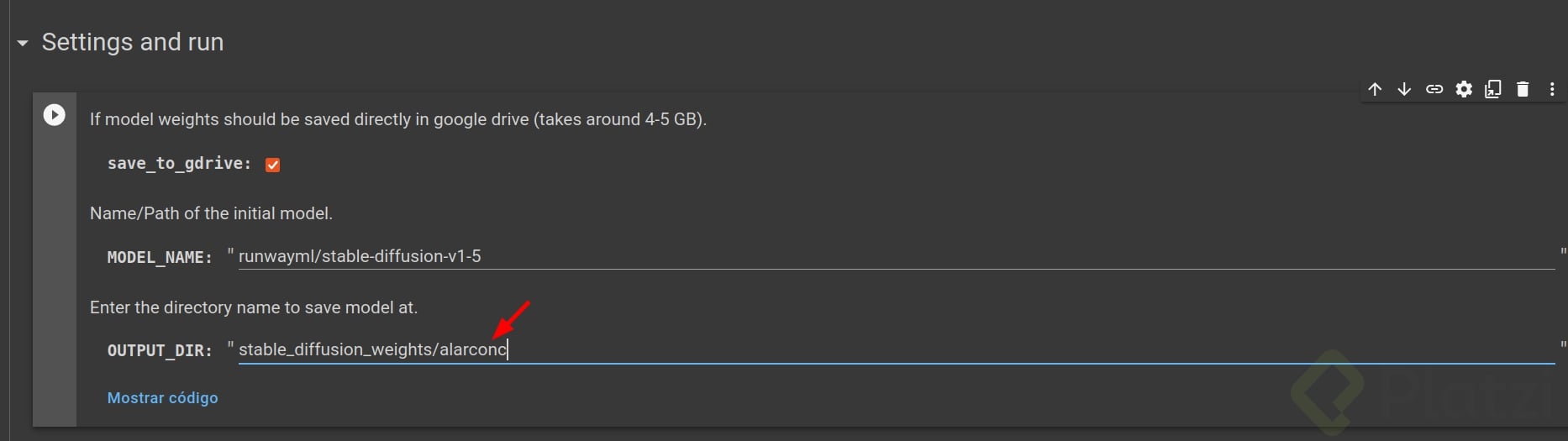
7. Configurar parámetros:
Ejecutar las celdas hasta este punto en donde hice estos cambios pues quiero que se me me identifique como “alarconc”. También quiero que la información del entrenamiento se almacene en mi drive, a lo que le debo dar permisos posteriormente al ejecutar esta celda.
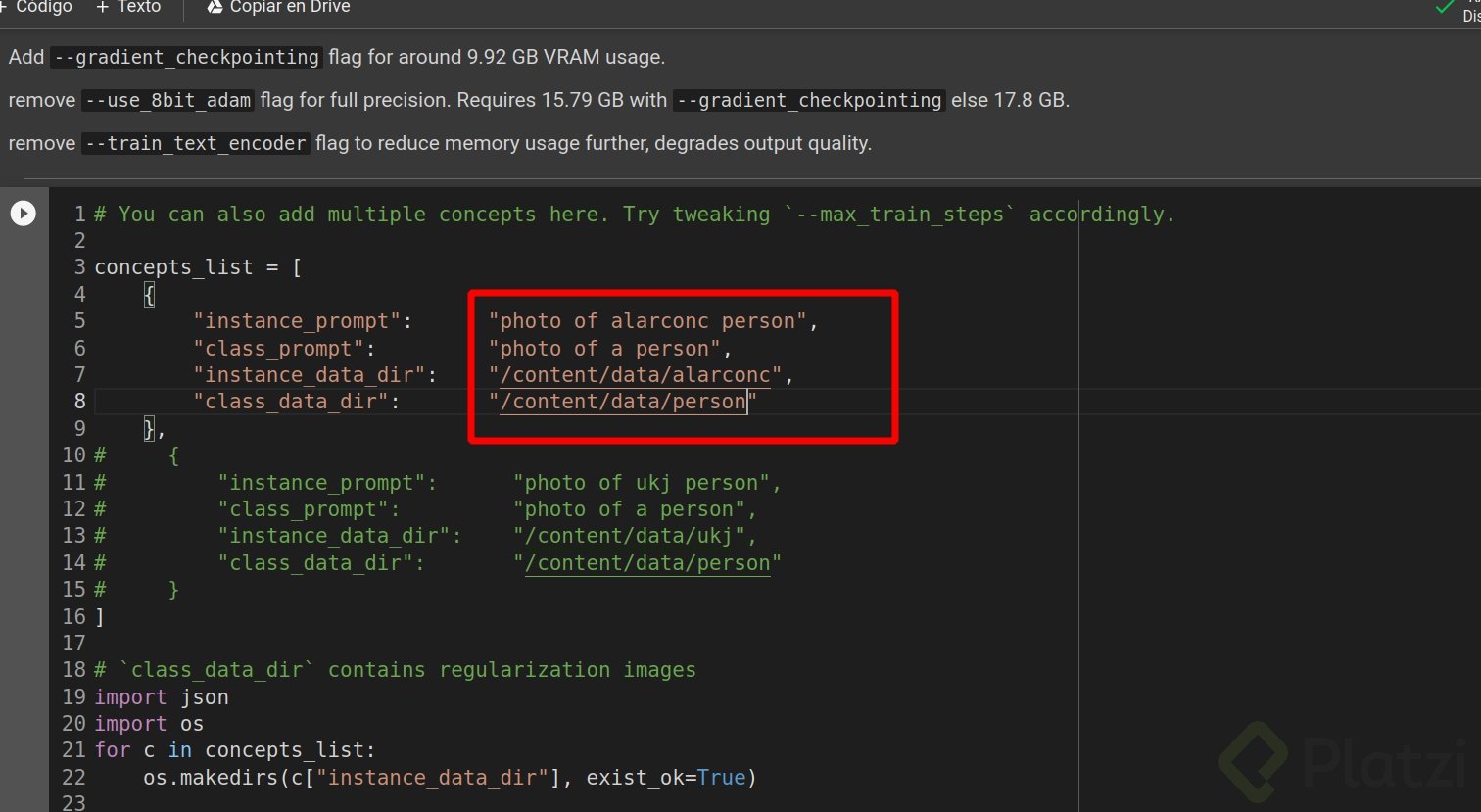
Y posteriormente esta configuracion en donde especifico donde quedaran las imagenes con las que entrenaremos el modelo y que para mi caso quiero que se me asocie al conepto de persona “person”
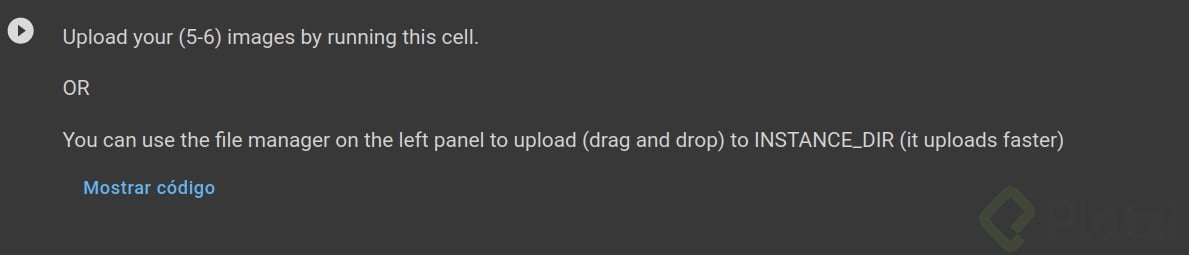
8. Ejecutar las celdas hasta este punto:
No debes ejecutar esta celda
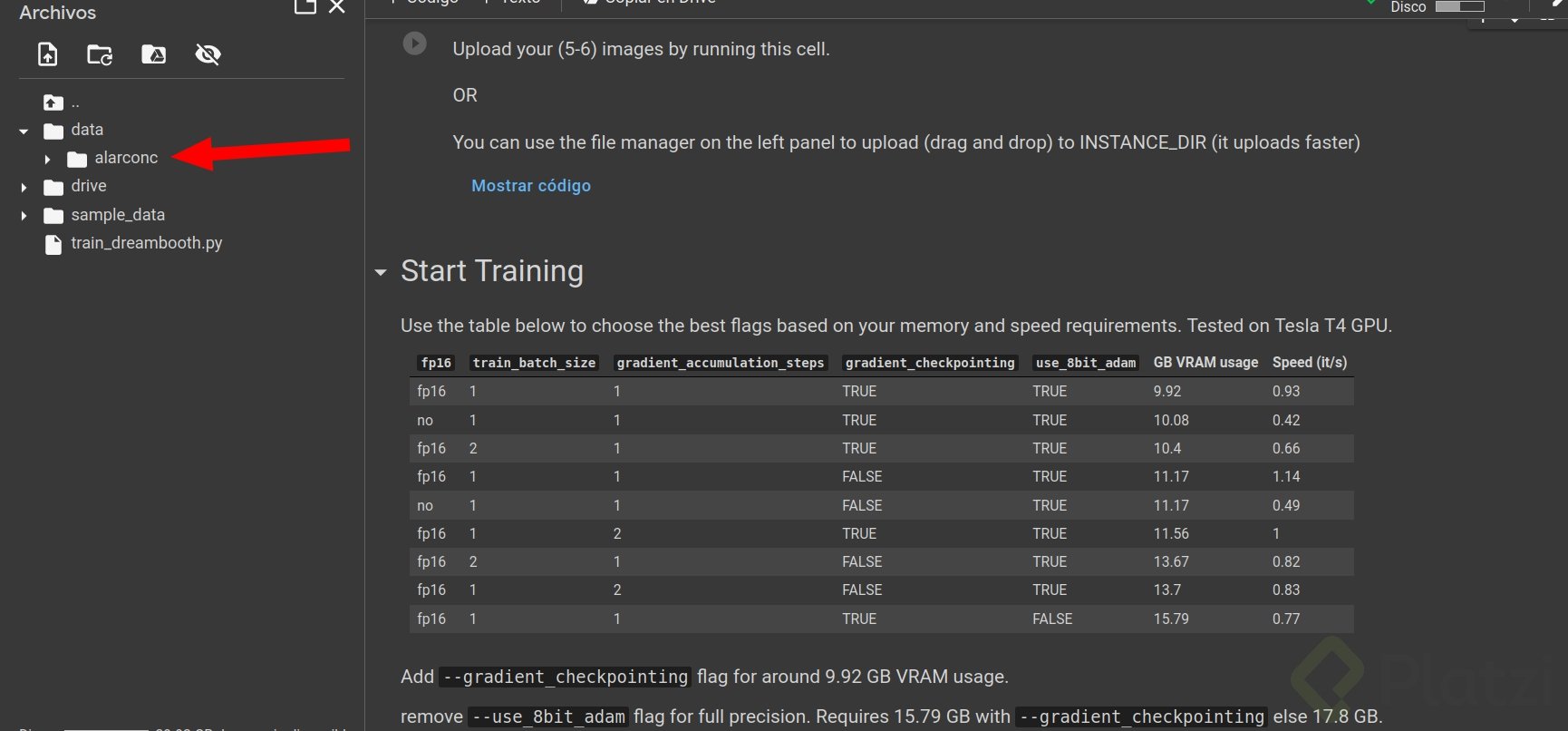
9. Subir imágenes de tu rostro:
Subir 5 o 7 imágenes tuyas en la carpeta con el nombre que dejaste. Para mi caso alarconc, esto se logra simplemente arrastrando las imágenes:
10. Entrenamiento:
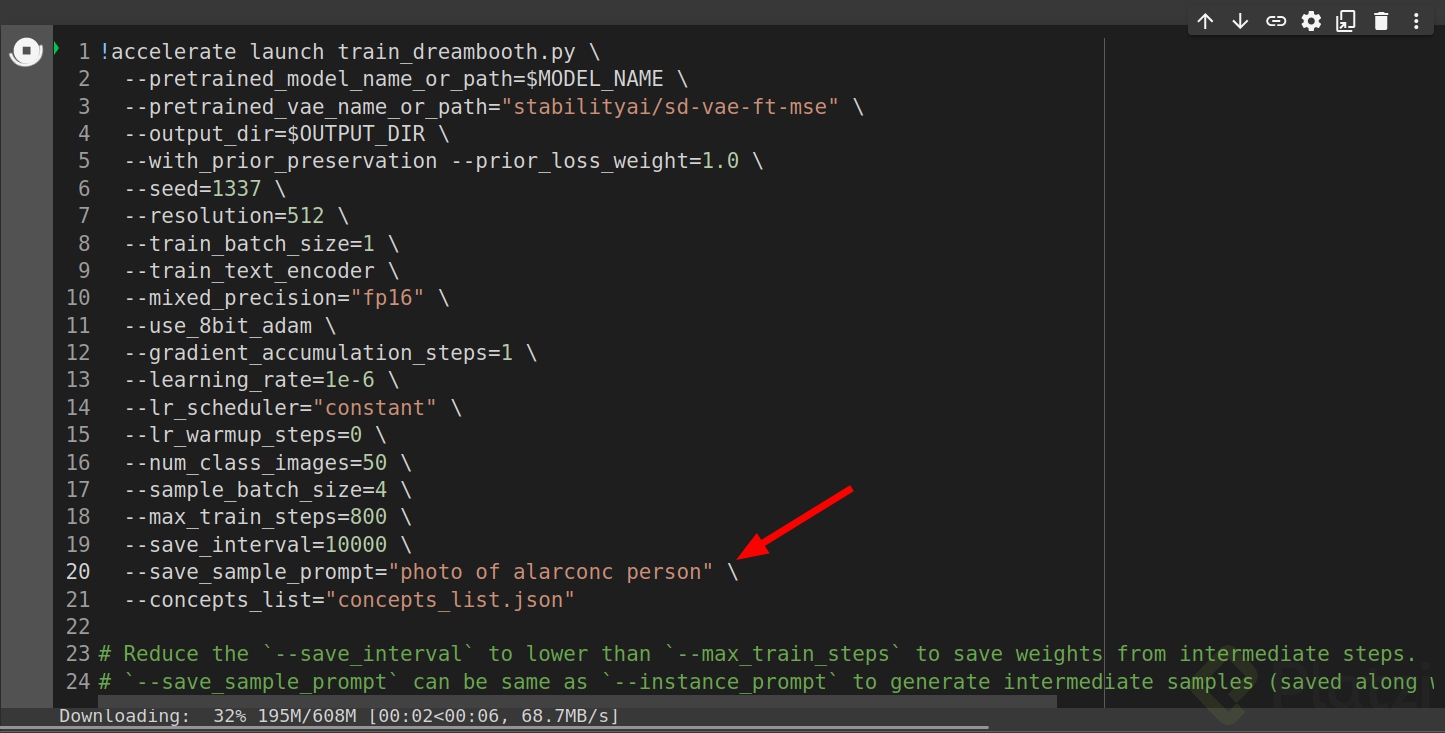
Es momento de entrenar, ejecuta las celdas que falten hasta este punto y remplaza en los parámetros por el nombre que definiste previamente, en mi caso “alarconc”. Este proceso puede tardar un poco.
tambien puedes probar cambiar ciertos valores como:
- –max_train_steps que representa la cantidad de iteraciones del modelo, a mayor iteraciones mejores resultados, pero con 800 es suficiente (ademas puede que muchos parametros sobrepasen la GPU actual)
- –num_class_images que representa la cantidad de imagenes de regularizacion de la misma clase que definiste para el proceso de entrenamiento
en lo personal lo deje con los parametros por default que son los que ves en la imagen.
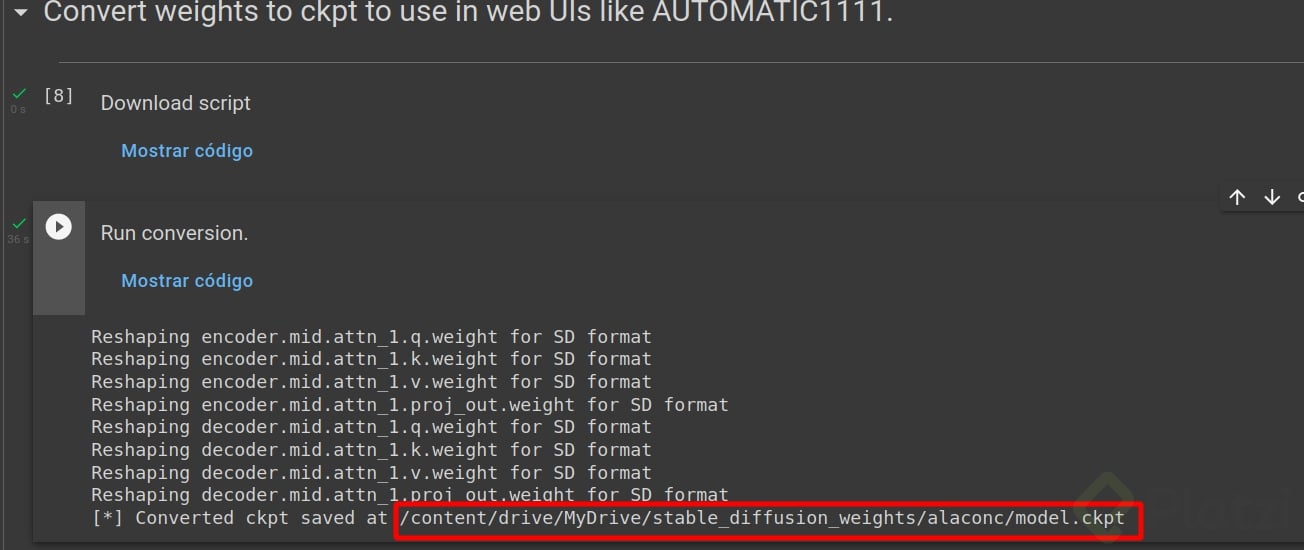
11. Crear archivo CPKT:
Ejecutar las siguientes celdas para guardar tu modelo cpkt. Este modelo lo puedes usar en cualquier herramienta de generación automática como lo es AUTOMATIC1111 sin tener que re entrenar el modelo.
12. Valor de semilla (seed):
Ejecutar las celdas hasta este punto, puedes dejar -1 para que genere un resultado aleatorio siempre o cualquier número específico para replicar algún resultado.

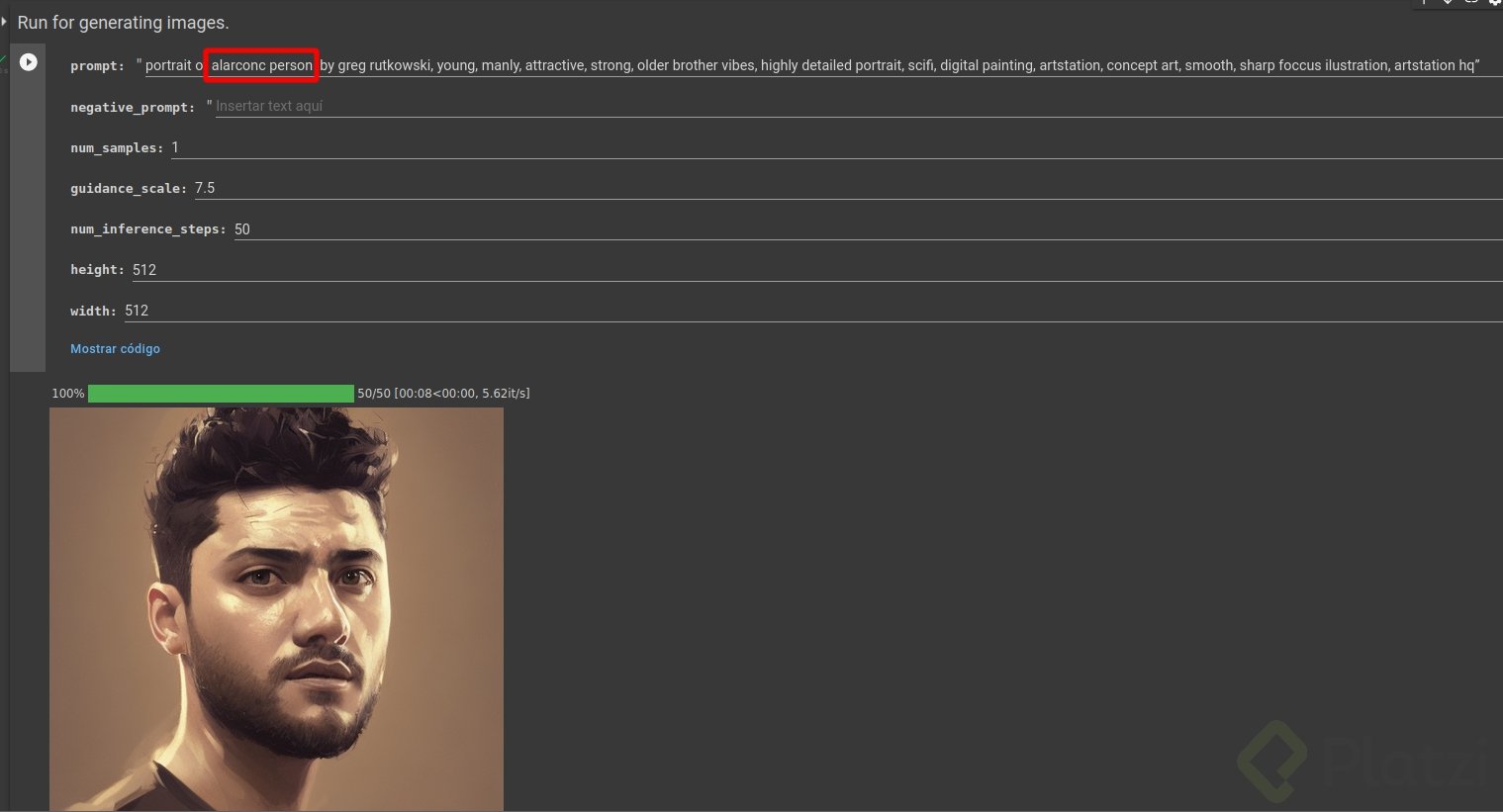
13. Ejecutar el modelo:
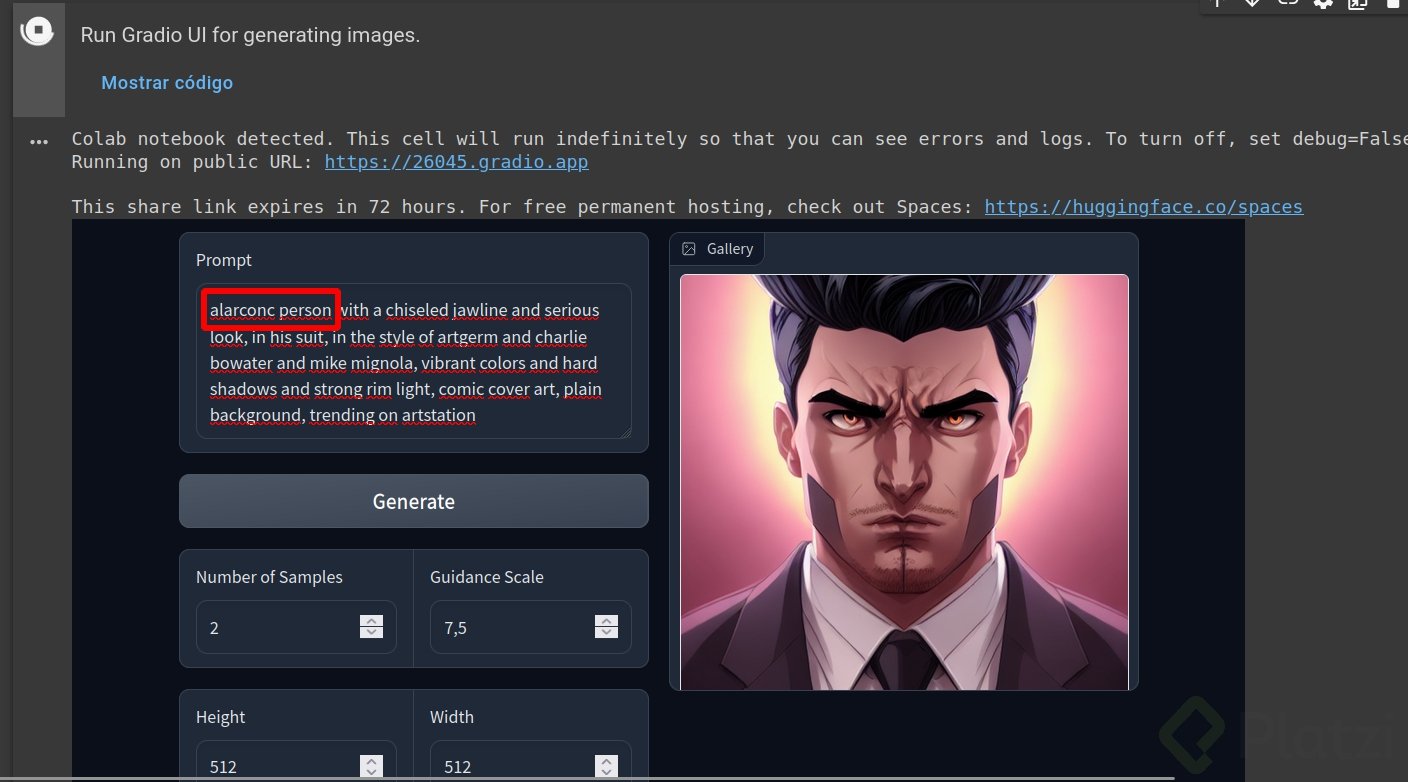
SIEMPRE debes ejecutarlo con la configuración que creaste en el punto 8, de esta forma, en mi caso alarconc person. Y listo, disfruta generando imágenes en esta celda, y cambiando los parámetros de cantidad de imágenes, número de iteraciones, etc etc.
14. Ejecutar el modelo con UI:
La siguiente celda que proporciona una interfaz gráfica de Gradio UI que también puedes usar, no hay diferencia con el punto 13 en resultados, pero puede ser mas cómoda de usar
🧠 ¡Diviértete!
¡Ahora puedes generar tu rostro en distintos estilos! Recuerda que todo gran poder conlleva una gran responsabilidad, por ello, no entregues el modelo cpkt a extraños. Esta tecnología cambiara la economía de cómo se hacen ediciones y creaciones digitales, así que úsala con cuidado.
Créditos a los owners de los siguientes repositorios. Puedes agradecer con un star ⭐ o aportando a sus repos:
https://github.com/ShivamShrirao/diffusers/tree/main/examples/dreambooth
https://github.com/JoePenna/Dreambooth-Stable-Diffusion (Si quieres resultados mas increibles puedes seguir los pasos del notebook en este repositorio pero requiere al menos 24 GB de GPU)
En caso de que quieras descubrir qué son las redes neuronales artificiales, te invito a tomar el Curso de redes Neuronales de Python y Keras donde explico sus fundamentos.
Y claro algunos enlaces que te pueden interesar:
- Stable Diffusion: crea arte con una AI totalmente libre
- Pagina de Stable Diffusion
- Paper de DreamBooth
- Pagina oficial de DreamBooth
- Lexica: una página para mejorar tus promts
Para aprender más de estos modelos de difusión, y generar más imágenes con diferentes estilos, te invito a tomar el Curso de Generación de Imágenes con IA: Dall-E, Midjourney y Stable Diffusion del que tengo el gusto de acompañarte como profesor. 🚀
¡Sígueme en Instagram/Twitter/TikTok como @alarcon7a, espero ver tus imágenes generadas y comparte tus creaciones con la comunidad 🙂
Curso de Generación de Imágenes con IA: Dall-E, Midjourney y Stable Diffusion
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE





