En los últimos meses hemos visto grandes avances en el campo de la inteligencia artificial, con modelos como Dalle 2, AlphaCode, AlphaFold y uno muy especial que es stable diffusion. Este último no resalta solo por su excelente desempeño sino también porque es totalmente libre y de uso gratuito.
En esta ocasión te hablaré de Whisper, el nuevo modelo de speech recognition del equipo de OpenAI que tiene esa misma característica, asi es, un modelo totalmente libre y está recién salido del horno, pues lo publicaron el 21 de septiembre de 2022🔥

Es un modelo de ASR (Automatic Speech Recognition) entrenado con 680,000 horas de distintos audios en múltiples lenguajes y múltiples acentos. De esta manera, Whisper con una arquitectura de transformers es capaz de detectar el idioma en el que cualquier persona habla y pasar este audio a texto en la misma lengua o completamente traducido al inglés.
¿Problemas con las tildes? Mira estos ejemplos de palabras esdrújulas

Está basado en una arquitectura de codificadores y decodificadores con trasnformers. El audio es capturado y separado en partes de 30 segundos para pasar a un codificador que lo transforma en secuencias que el modelo puede entender.
Luego cada una las partes se pasan a un decodificador entrenado para transcribir la voz a texto, utilizando features especiales que dirigen al modelo único. Este realiza tareas como identificación de idioma, marcas de tiempo a nivel de frase, transcripción de voz multilingüe y traducción de voz al inglés.
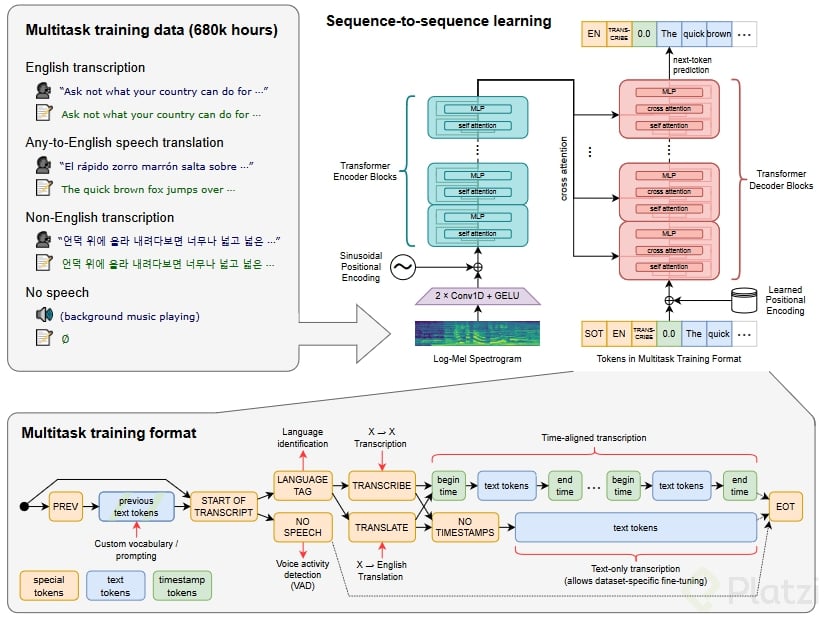
Además, Whisper, como muchos otros modelos, cuenta con distintas versiones para su uso. Estas versiones cambian en la cantidad de parámetros que tienen y, por supuesto, el peso de cada modelo en tamaño es afectado por la cantidad de parámetros con los que fue entrenado, de modo que a más parámetros más pesa el modelo y más recursos requiere.

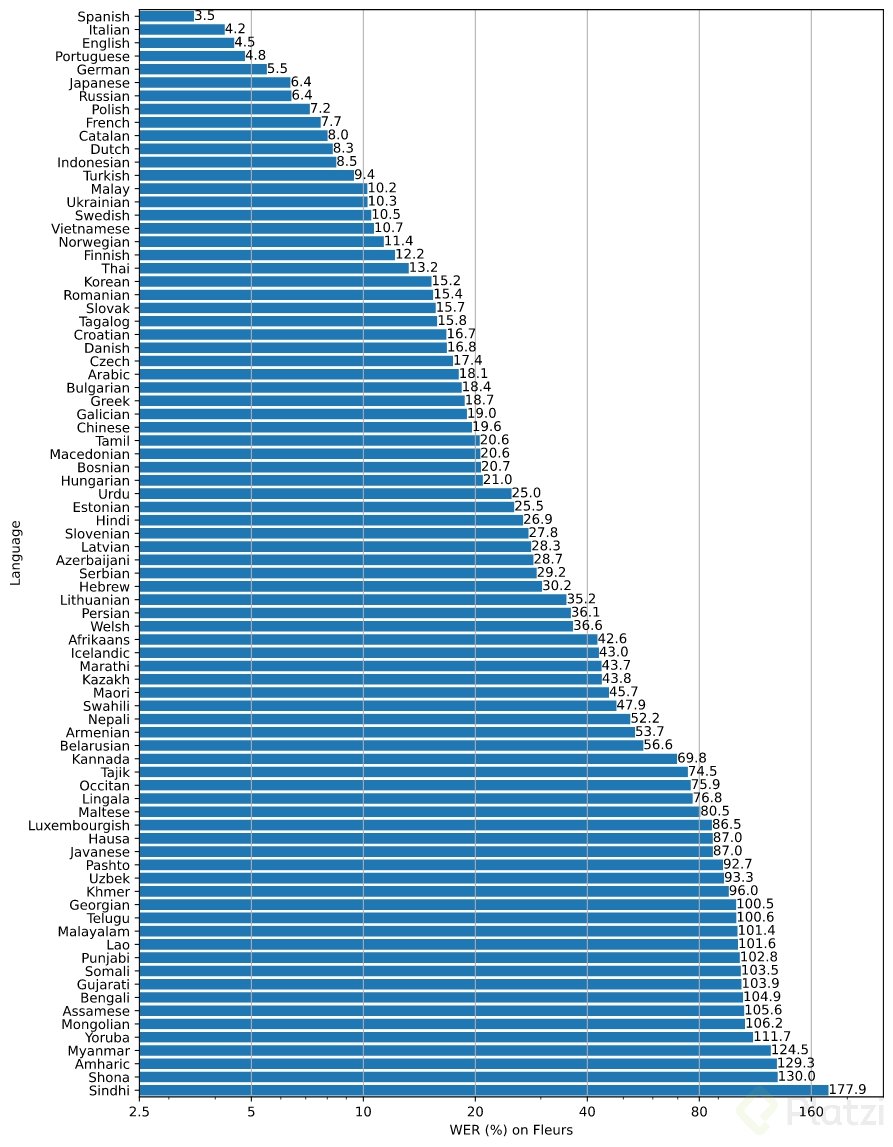
Y por supuesto, al tener múltiples lenguajes no todos tienen el mismo performance, la pregunta que seguro te estás haciendo en este momento es su funcionamiento en español.
La respuesta es, aparentemente, muy bien, los siguientes son los resultados con el modelo más robusto, en el cual miden el WER (word error rate) que mide el performance en la salida del texto y la referencia del script.
En Python, es bastante sencillo, lo puedes ejecutar incluso en un notebook de Colab.
Este es el código:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
De no tener whisper como librería solo debes instalarla con :
pip install whisper
o
pip install git+https://github.com/openai/whisper.gitDesde luego, trae muchas más opciones de configuración y parametrización, pero esta es la base para usar este modelo, ¡totalmente gratis!
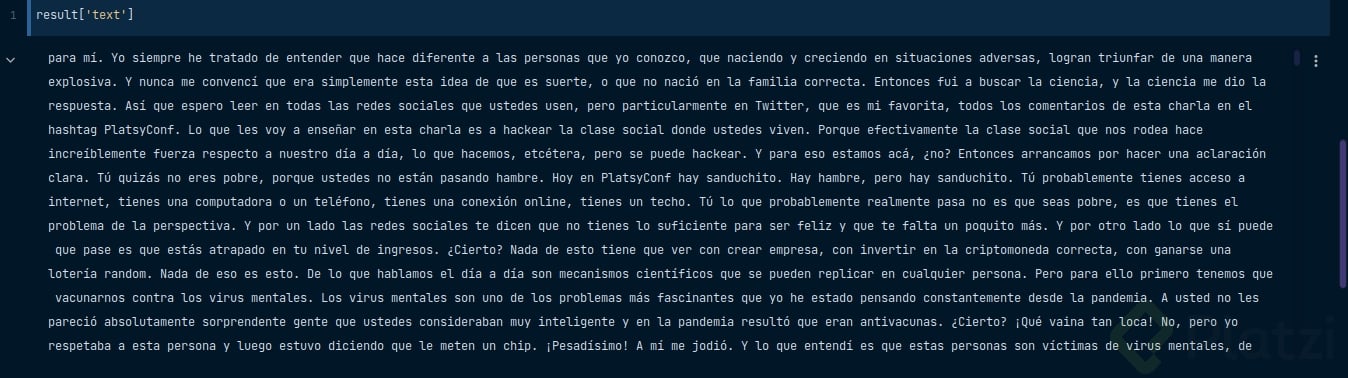
Los resultados de un modelo medium en español sobre la charla de Freddy en #PlatziConf son bastante satisfactorios pues incluso whisper es capas de transcribir correctamente signos de puntuación, signos de exclamación y pregunta 🤯
Te invito a dejar tus opiniones en el sistema de comentarios o mis
redes sociales, pues es una conversación muy interesante en la industria 🙂
Si te interesa conocer más acerca de este tema, te recomiendo leer estos contenidos.
En caso de que quieras descubrir qué son las redes neuronales artificiales, te invito a tomar el Curso de redes Neuronales de Python y Keras, donde explico sus fundamentos.
¡Sígueme en Instagram/Twitter/TikTok como @alarcon7a y hablemos de datos, hasta una próxima!







Les cuento que no me funcionó la forma mostrada por el profe Alarcón, pero encontré una forma que sí lo hizo.
Primero, en el notebook de Google Colab, ingresé a la opción “Runtime/Change runtime type”. Allí activé la aceleración de hardware con la GPU.
Luego, el código que usé fue el siguiente:
!pip install git+https://github.com/openai/whisper.git !sudo apt update && sudo apt install ffmpeg !whisper "audio.mp3"Al ejecutarlo, mi audio fue transcrito sin errores y fue maravilloso.
PD:
Hola isaaleonardo, cómo ingresaste a la opción runtime/change runtime type?
Hola, David! Espero que esta imagen te ayude para ingresar a la opción:
Me funcionó perfectamente, muchas gracias por tu ayuda.
al parecer no se instala correctamente, en la documentación de guthub sugiere:
pip install git+https://github.com/openai/whisper.git
¡Excelente post! 😄
Al cargar audio grabado entiendo que no es en Tiempo Real, para eso se necesitaría HW asíncrono. Aun así, es muy interesante.
Llama la atención el WER del Español, mejor que el inglés, muy buen rendimiento.
No sé por qué Platzi aún no ha puesto subtítulos a sus clases para acercar el conocimiento a todas las personas, incluidas las que tengan problemas auditivos.
Creo que solo lo hacen en las clases de inglés, pero hay muchas herramientas para facilitarlo.
¡Saludos! 😃
es tan eficiente que puede llegar muy cercano a tiempo real
Es una API o toda la funcionalidad se obtiene solo instalando la librería?
😱 Tremendamente increible.
Que bueno que ya se estan viendo estas aplicaciones en audio y video (no solo imagen) de estas RN basadas en transformers.
Muchas gracias por dar la informacion tan oportuna, se me ocurren muchas aplicaciones,
A darle duro para aprovechar mientras sea gratis. 👌