Cómo comparar índices vectoriales en Azure AI Search
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
03:34 min - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
04:49 min - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
Cómo guardar embeddings en Parquet para la nube
03:13 min - 18
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
Cómo comparar índices vectoriales en Azure AI Search
Viendo ahora - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Cómo comparar índices vectoriales en Azure AI Search
Resumen
Comparar índices vectoriales en Azure AI Search te permite descubrir cuál algoritmo de compresión optimiza mejor tu proceso de RAG. Si trabajas con embeddings y necesitas decidir entre almacenamiento, velocidad y precisión, esta comparación práctica te muestra diferencias reales de hasta 25 veces en tamaño.
¿Cómo verificar que los índices se cargaron correctamente en Azure?
Después de ejecutar la carga, lo primero es validar que cada índice tenga sus registros completos antes de medir cualquier diferencia.
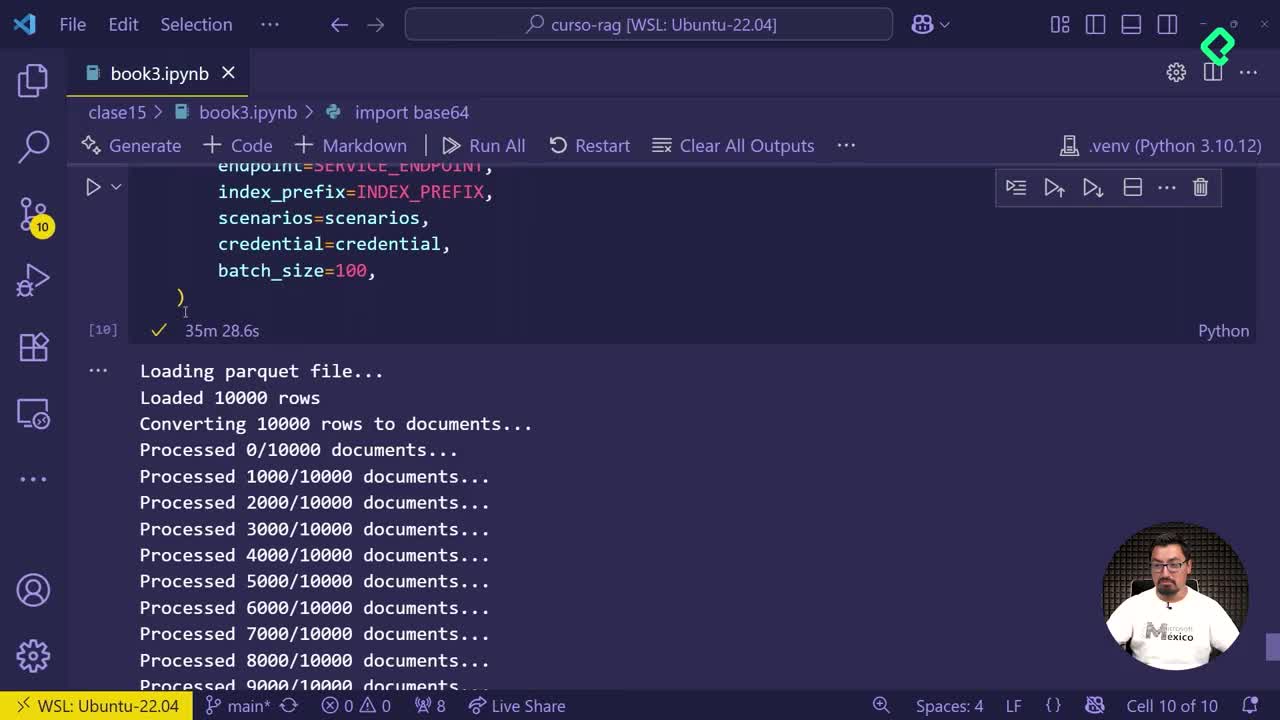
La operación completa tomó 35 minutos y 28 segundos, una señal de que la red de Platzi responde más rápido que un entorno local de pruebas. Al entrar al portal de Azure, cada índice creado aparece con sus 10.000 registros cargados, lo que confirma que la información está lista para ser evaluada.
Desde aquí puedes revisar el almacenamiento básico, pero para entender qué hace especial a cada índice necesitas algo más que el panel visual de Azure. Por eso el siguiente paso ocurre dentro de VS Code.
¿Qué es un índice vectorial en Azure AI Search? Es una estructura que almacena embeddings (representaciones numéricas de texto) para permitir búsquedas semánticas rápidas dentro de un sistema de RAG.
¿Cómo extraer metadatos de los índices con Python y Tabulate?
Para comparar índices necesitas una tabla que muestre nombre, escenario y tamaños lado a lado.
En VS Code creas un nuevo bloque de código que cumple dos funciones: instanciar el cliente que se conecta a Azure y usar el paquete Tabulate para presentar los resultados de forma legible. El método encargado de obtener el tamaño de los índices [12:00] extrae los metadatos complementarios y los organiza en columnas comparables.
Las variables que vas a visualizar son:
- Nombre del índice, para identificarlo rápido.
- Escenario, que define el algoritmo de compresión usado.
- Almacenamiento total en megas.
- Tamaño de los vectores por separado.
- Tamaño total combinado.
Con esta tabla puedes medir cómo cada estrategia de fragmentación impacta el almacenamiento real de tus chunks.
¿Qué son los chunks y por qué importan en RAG?
Los chunks son fragmentos de texto en los que se divide tu documento antes de convertirlos en vectores. Su tamaño y la forma en que se comprimen determinan cuánta memoria ocupa el índice y qué tan precisa será la búsqueda posterior.
¿Qué diferencias reales hay entre los escenarios de compresión vectorial?
Aquí es donde se ve por qué elegir el escenario correcto cambia todo el proyecto.
Ejecutas la tarea y la tabla revela contrastes enormes entre algoritmos aplicados sobre la misma información:
- Configuración básica: 382 megas de almacenamiento total.
- Reducción al tamaño de vectores: baja a 117 megas.
- Test binary truncated: cae hasta 15 o 16 megas, con apenas 1.8 megas en vectores.
La diferencia entre 382 megas y 16 megas usando los mismos 10.000 registros muestra que la elección del algoritmo no es un detalle técnico menor, es una decisión de arquitectura.
¿Cuándo conviene usar binary truncated frente a scalar full? Binary truncated es ideal para volúmenes grandes de información porque comprime de forma agresiva. Scalar full conviene cuando trabajas con pocos documentos y prefieres conservar precisión sobre ahorro de espacio.
¿Qué escenario elegir según el tipo de proyecto?
La decisión depende del volumen de información que vayas a procesar.
Si manejas larguísimos volúmenes de documentos, los escenarios con mayor compresión (como binary truncated) te ahorran espacio y costos. Si solo trabajas con seis o siete PDFs, un baseline S o un scalar full es suficiente: comprime menos, pero mantiene la información más fiel al original.
Tener todos estos índices con la misma cantidad de registros te da una base justa de comparación. Y esa comparación es la que define si tu sistema de RAG va a escalar bien o se va a quedar corto cuando crezca el corpus.
¿Cuál escenario crees que se ajusta mejor a tu caso de uso? Cuéntame en los comentarios qué tipo de documentos estás indexando.