Cómo guardar embeddings en Parquet para la nube
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
03:34 min - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
04:49 min - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
Cómo guardar embeddings en Parquet para la nube
Viendo ahora - 18
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
Cómo comparar índices vectoriales en Azure AI Search
03:58 min - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Cómo guardar embeddings en Parquet para la nube
Resumen
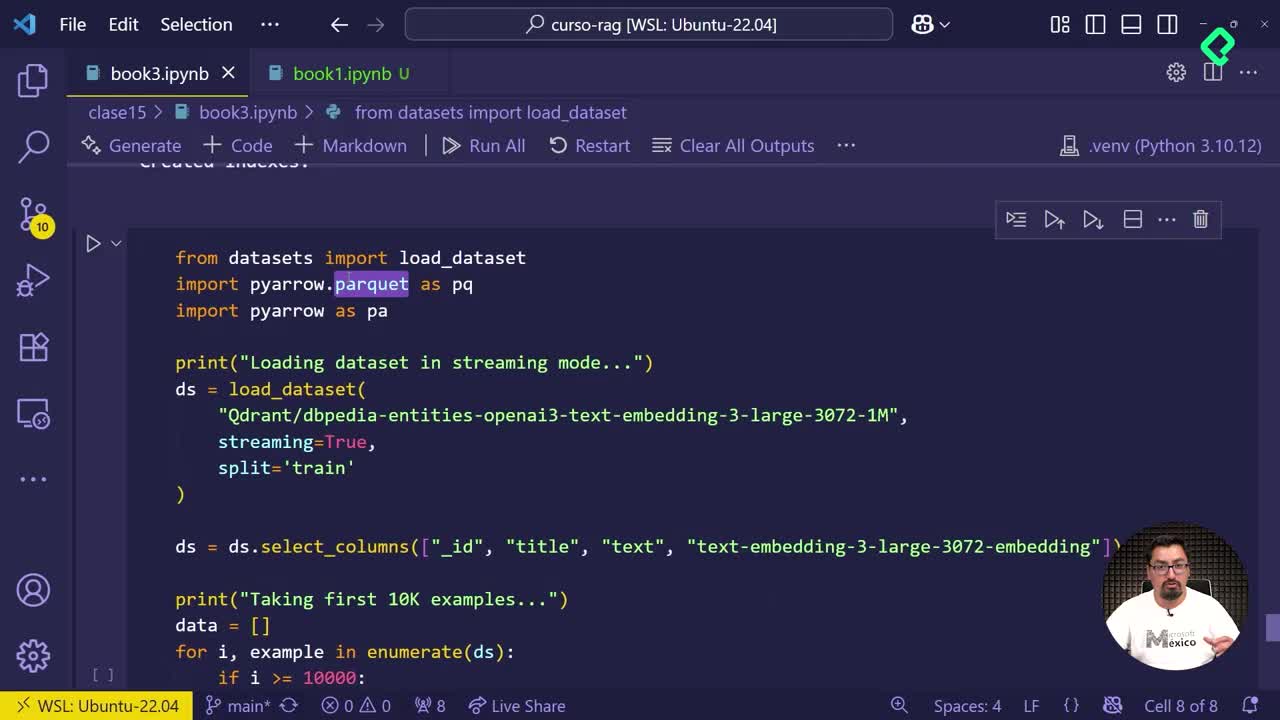
Cuando trabajas con grandes volúmenes de datos vectoriales, generar embeddings localmente y almacenarlos en un formato eficiente es el paso previo indispensable antes de migrar todo a la nube. Aquí verás cómo crear un dataset de 10.000 registros usando un archivo Parquet y un modelo large, listo para indexarse y subirse a un entorno cloud.
¿Por qué usar Parquet para almacenar embeddings?
Parquet es un formato columnar muy popular en ciencia de datos porque comprime la información y permite leerla por columnas, lo que acelera el análisis cuando manejas miles o millones de registros.
En el flujo de trabajo, este archivo cumple tres funciones clave:
- Guardar los datos dummy generados con el modelo.
- Mantener una estructura estable que luego se transforma en tabla.
- Servir como puente entre el procesamiento local y la subida a la nube.
¿Qué es un archivo Parquet? Es un formato de almacenamiento columnar usado en análisis de datos. Comprime mejor que un CSV y permite leer solo las columnas que necesitas, ahorrando memoria y tiempo.
¿Cómo configurar el modelo y el tamaño del dataset?
La configuración inicial define dos cosas: el modelo large que generará los embeddings y la cantidad de muestras a procesar. En el ejemplo se trabaja con 10.000 registros, suficiente para una clase práctica sin saturar el equipo [00:35].
Si cuentas con más recursos, puedes escalar a 100.000 registros para medir mejor el impacto real del modelo large. Cuanto mayor sea la muestra, más representativo será el resultado al momento de hacer búsquedas vectoriales.
El ciclo recorre las muestras, genera los vectores y guarda todo en un archivo llamado dbpedia-10000.parquet.
¿Qué estructura tiene el dataset generado?
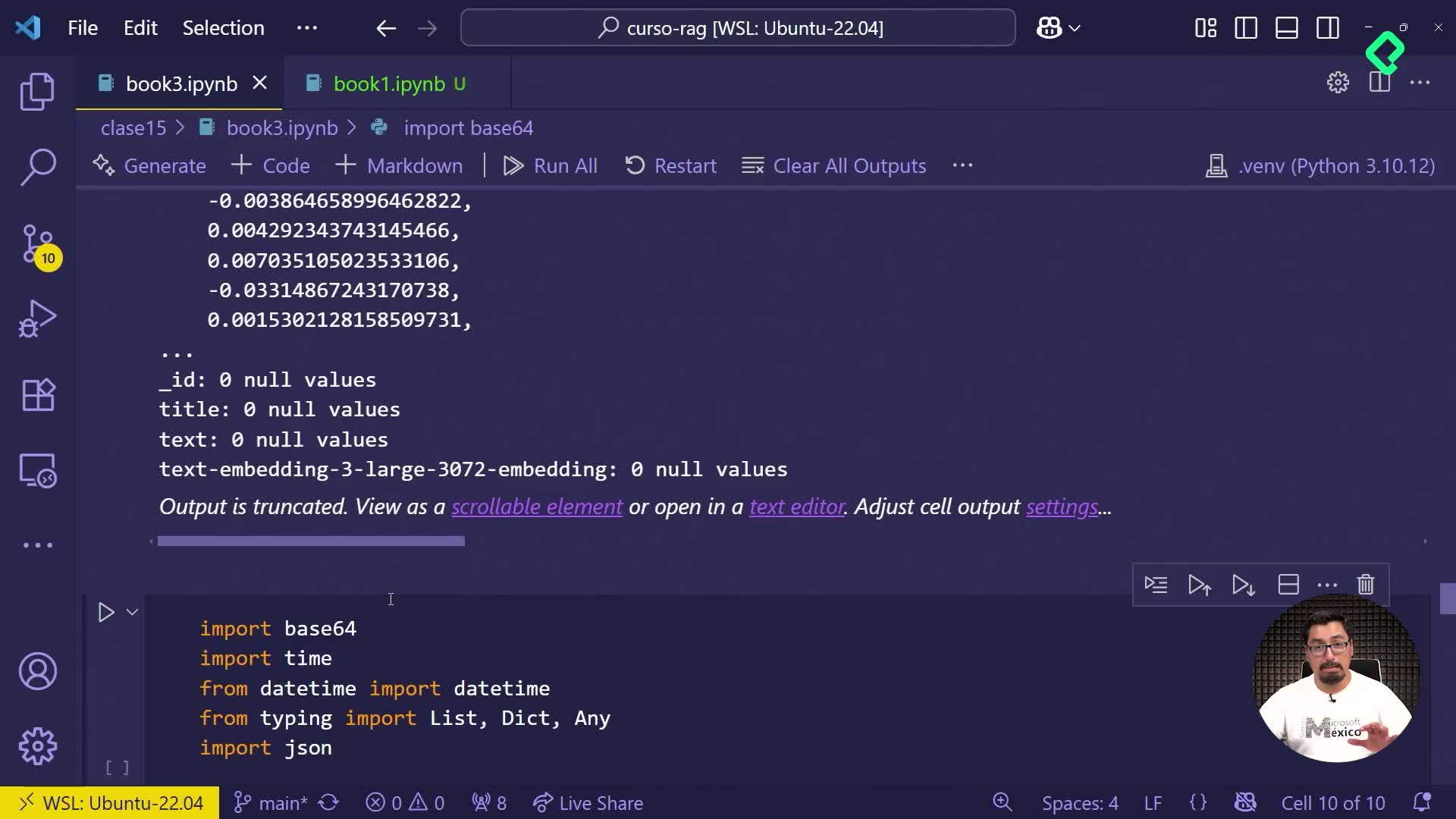
Después de 58 segundos de ejecución, el dataset queda guardado con 10.000 filas y cuatro columnas [01:30]:
- ID: identificador único de cada registro.
- Título: nombre o referencia del documento.
- Texto: contenido textual original.
- Text embedding: representación vectorial generada por el modelo.
Esta estructura es la base para cualquier operación de búsqueda semántica posterior.
¿Cómo preparar los datos para subirlos a la nube?
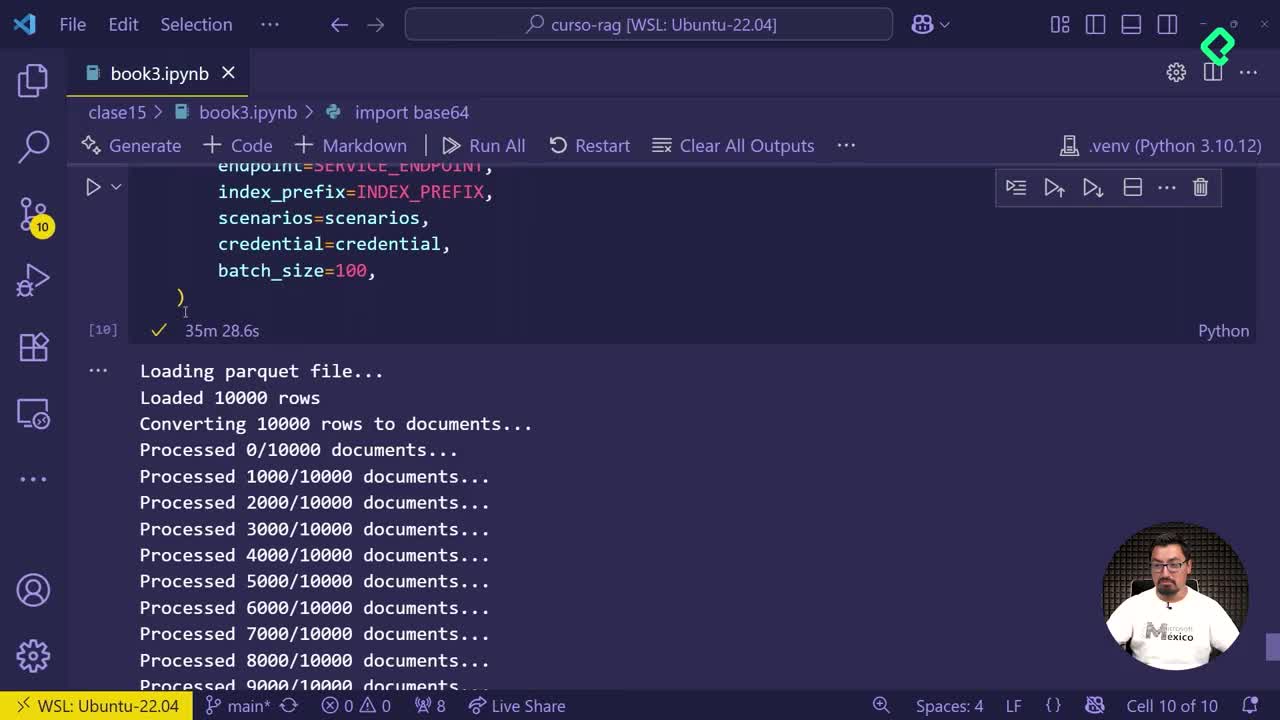
Una vez creado el Parquet, el siguiente bloque de código toma esa información y le da formato de tabla con un índice adecuado. Ese índice es lo que permitirá que la nube reconozca y organice los vectores correctamente.
¿Para qué sirve el índice en una tabla de embeddings? Sirve para identificar y recuperar cada vector de forma rápida. Sin índice, las búsquedas vectoriales serían lentas e ineficientes a gran escala.
Al visualizar la primera estructura del documento, los embeddings aparecen como vectores numéricos extensos. Una sola muestra tarda alrededor de 2,1 segundos en procesarse, pero al desplazarte por el dataset completo notarás que las muestras se multiplican rápidamente [02:25].
¿Qué sigue después de generar los vectores?
Con los vectores generados y los índices listos, solo queda un paso: mover toda esta información a la nube. Ese será el siguiente movimiento, donde el dataset Parquet pasa de ser un archivo local a un recurso consultable desde cualquier lugar.
¿Qué tamaño de dataset usarías tú para probar el modelo large? Cuéntalo en los comentarios.