Historia y futuro de RAG en los LLM
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
03:34 min - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
04:49 min - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
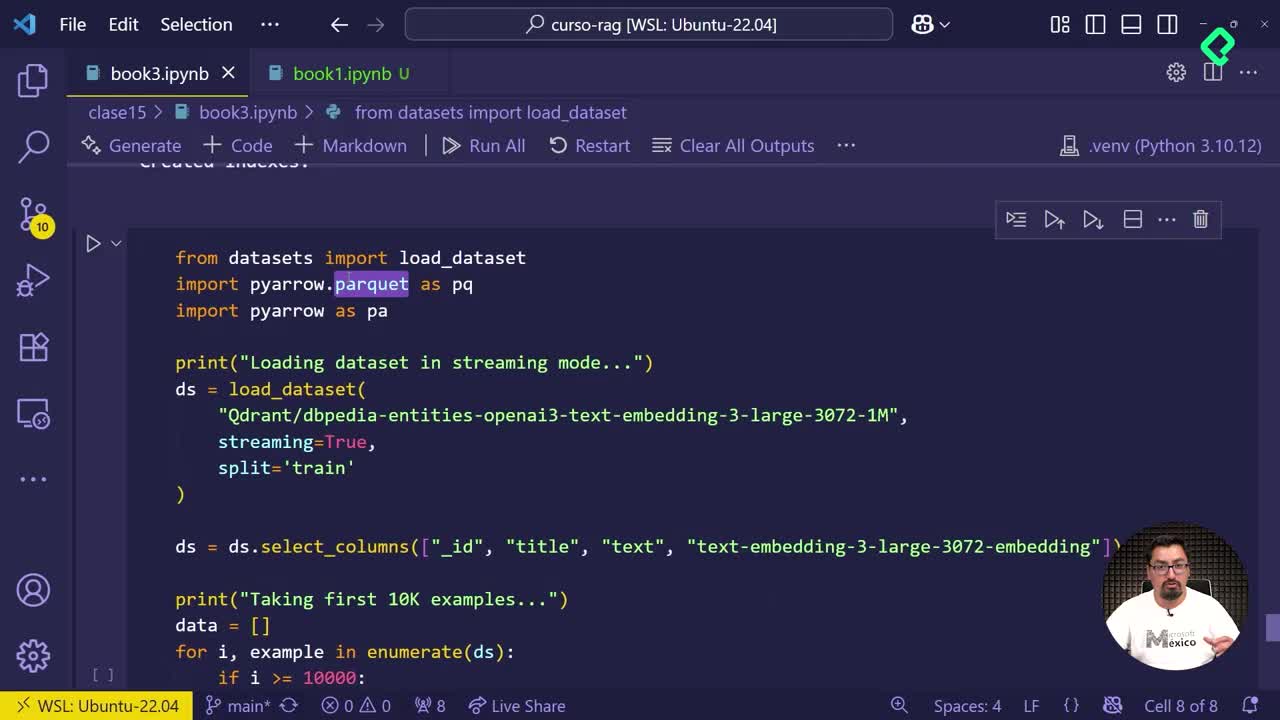
Cómo guardar embeddings en Parquet para la nube
03:13 min - 18
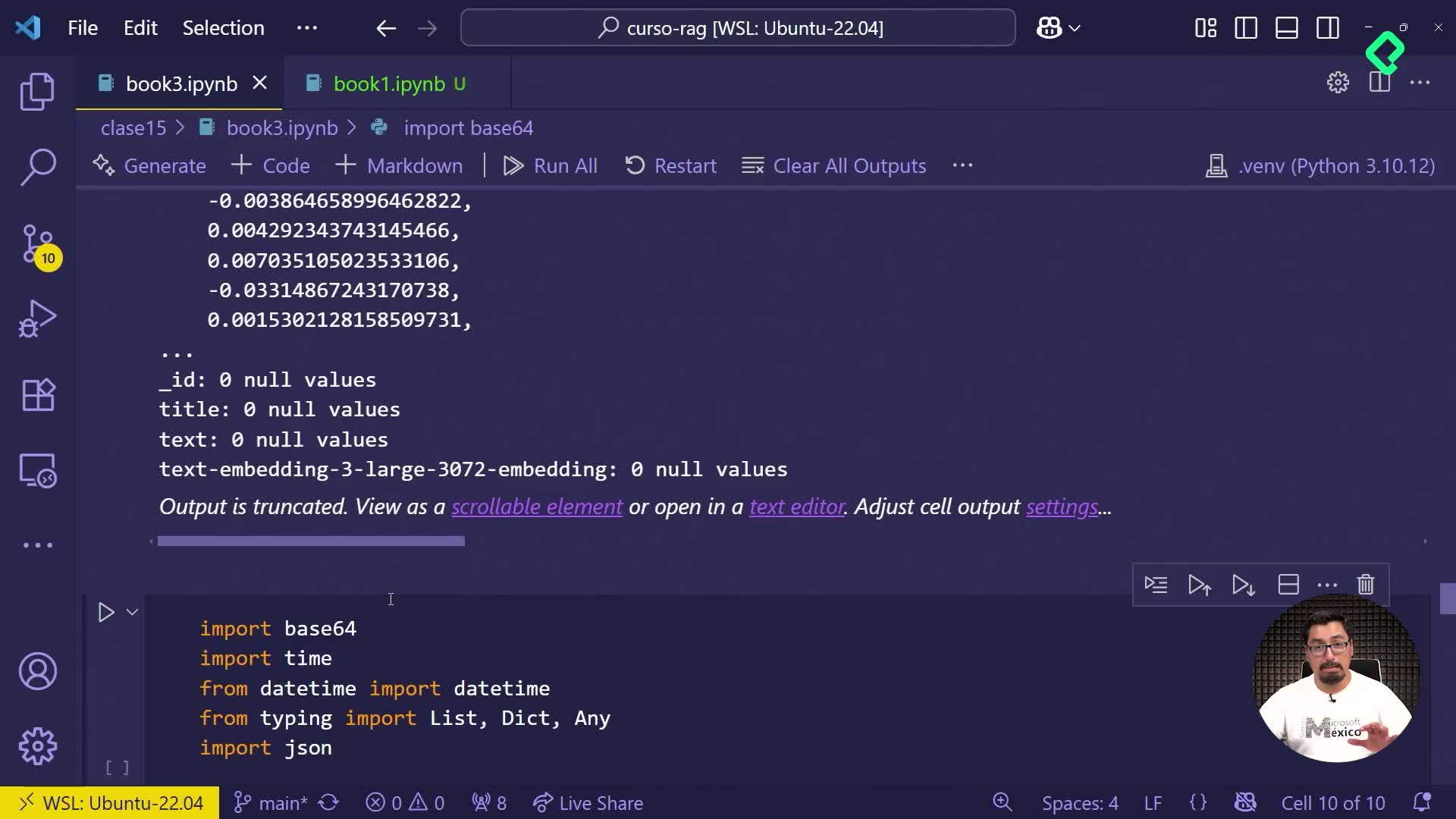
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
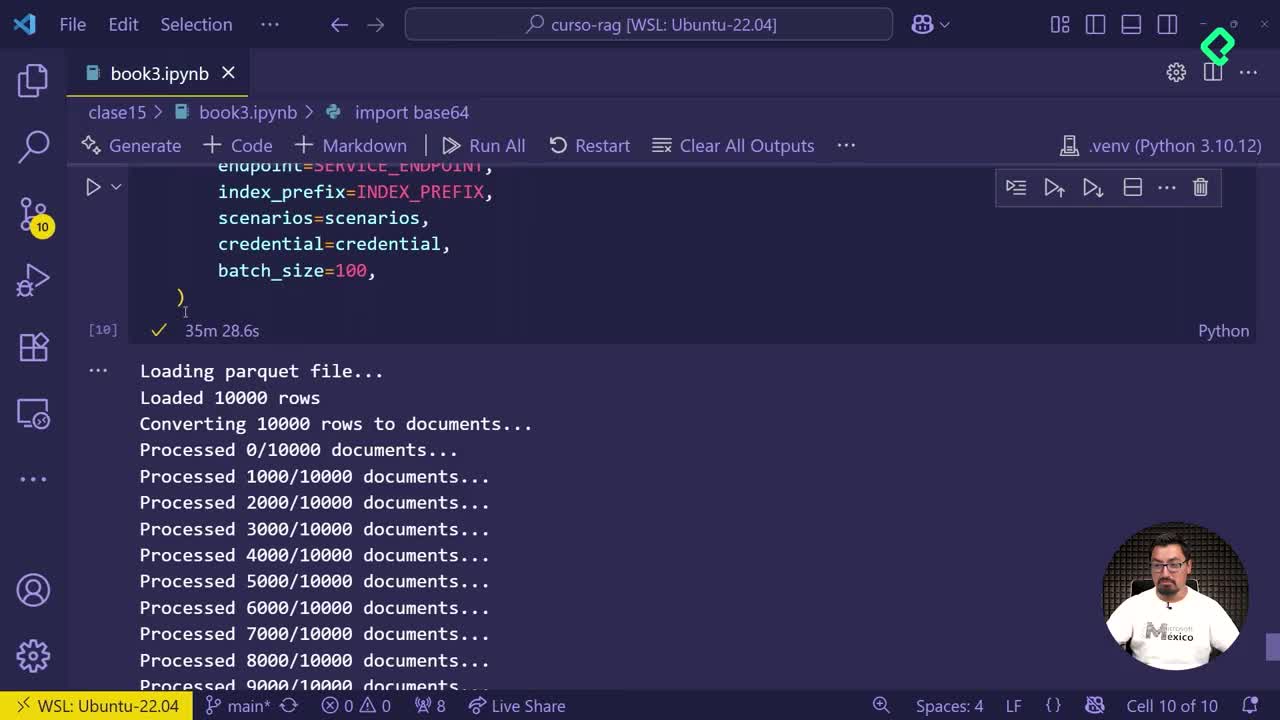
Cómo comparar índices vectoriales en Azure AI Search
03:58 min - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Historia y futuro de RAG en los LLM
Resumen
La arquitectura RAG (Retrieval Augmented Generation) transformó la manera en que los modelos de lenguaje acceden a información actualizada. Si te preguntas por qué ChatGPT hoy puede responder con datos de ayer y no solo con su entrenamiento original, la respuesta está en este sistema que aprendieron a integrar los LLM para dejar de quedarse anclados en el pasado.
Por qué RAG nació antes que los LLM modernos
Aquí pasó algo curioso con los tiempos. RAG no se inventó pensando en ChatGPT ni en los modelos gigantes que conocemos hoy.
El término apareció por primera vez en un estudio de abril de 2021, publicado por el área de investigación de Facebook. En ese momento, los LLM como los entendemos no existían a nivel masivo (eso pasó en 2022). Lo que sí existía era el Natural Language Processing o NLP, que en la práctica eran bots bastante limitados comparados con lo que vino después.
Los investigadores que propusieron RAG querían llevar a los modelos NLP a otro nivel. No imaginaban que del otro lado del patio estaban naciendo los LLM, que terminarían adoptando esta arquitectura como suya.
¿Qué significa RAG? Son las siglas de Retrieval, Augment, Generate: obtener información externa, aumentar el contexto del modelo con ella y generar una respuesta más precisa.
Cómo le da RAG esteroides a un LLM
Piensa en un LLM como alguien muy inteligente pero con la información congelada en la fecha de su entrenamiento. Sin ayuda externa, no sabe lo que pasó ayer.
Cuando OpenAI lanzó ChatGPT, su información estaba muy desactualizada. La solución fue agregarle un sistema RAG y búsqueda web, lo que le permitió consultar fuentes frescas antes de responder. Esa es la magia: el modelo deja de depender solo de su memoria y empieza a apoyarse en datos que recupera en tiempo real.
Este salto explica por qué hoy puedes preguntarle a un asistente sobre noticias recientes y obtener una respuesta coherente. La arquitectura RAG funciona como un acelerador que conecta al modelo con información viva.
¿Por qué los LLM necesitan RAG? Porque su conocimiento tiene fecha de caducidad. RAG les permite recuperar datos nuevos y responder con contexto actualizado sin tener que reentrenar el modelo.
Qué futuro tiene RAG frente a los agentes inteligentes
La pregunta interesante es qué pasará cuando los agentes evolucionen lo suficiente. Existe la posibilidad de que un agente llegue a indexar su propio contenido y absorba las funciones que hoy cumple un sistema RAG por separado.
Mientras eso ocurre, después de cuatro años desde aquel estudio fundacional de 2021, RAG sigue siendo una pieza clave para construir agentes más eficientes. Y esto aplica en dos terrenos:
- A nivel público, en herramientas como ChatGPT que millones de personas usan a diario.
- A nivel empresarial, donde las compañías necesitan que sus agentes consulten documentación interna, bases de datos y fuentes propias.
- En la evolución de los propios agentes, que hoy dependen de RAG para tomar mejores decisiones con información contextual.
La arquitectura ya cruzó la frontera de los NLP a los LLM, y todo apunta a que seguirá adaptándose conforme los agentes ganen autonomía.
¿Tú cómo estás usando RAG en tus proyectos con LLM? Cuéntame en los comentarios qué casos de uso te están funcionando mejor.