Arquitetura RAG: agente antes do LLM
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
03:34 min - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
04:49 min - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
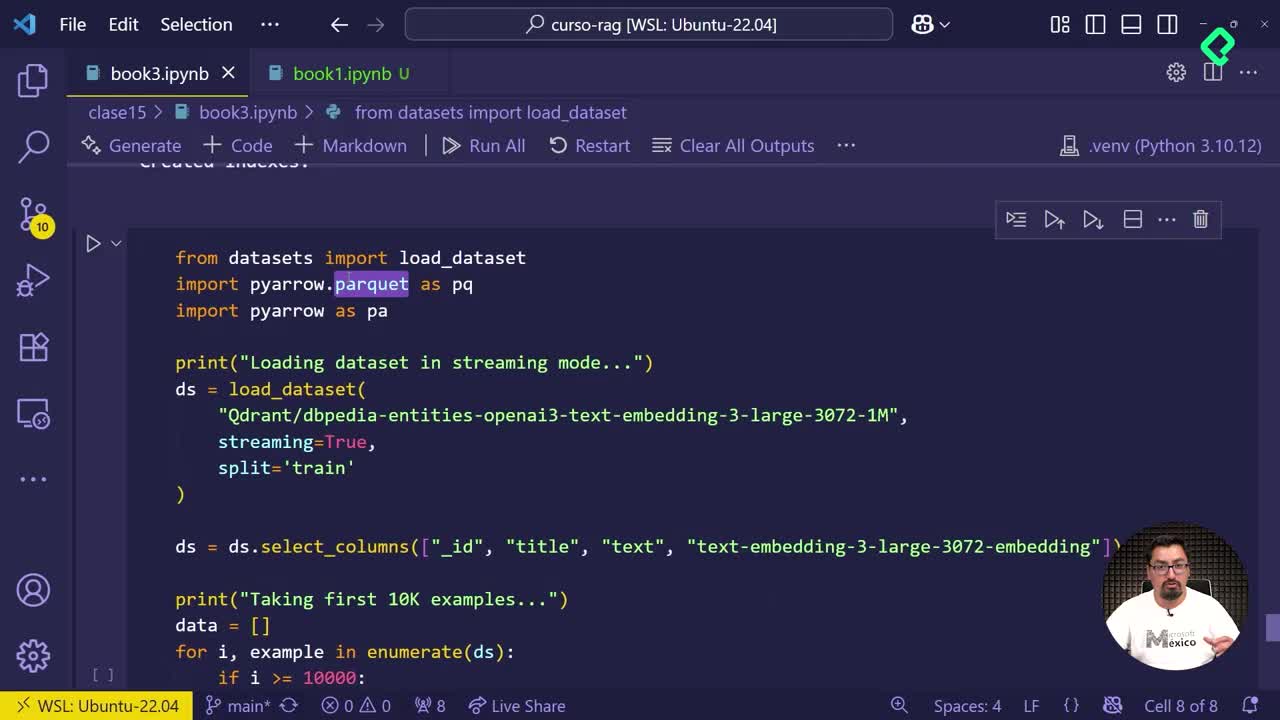
Cómo guardar embeddings en Parquet para la nube
03:13 min - 18
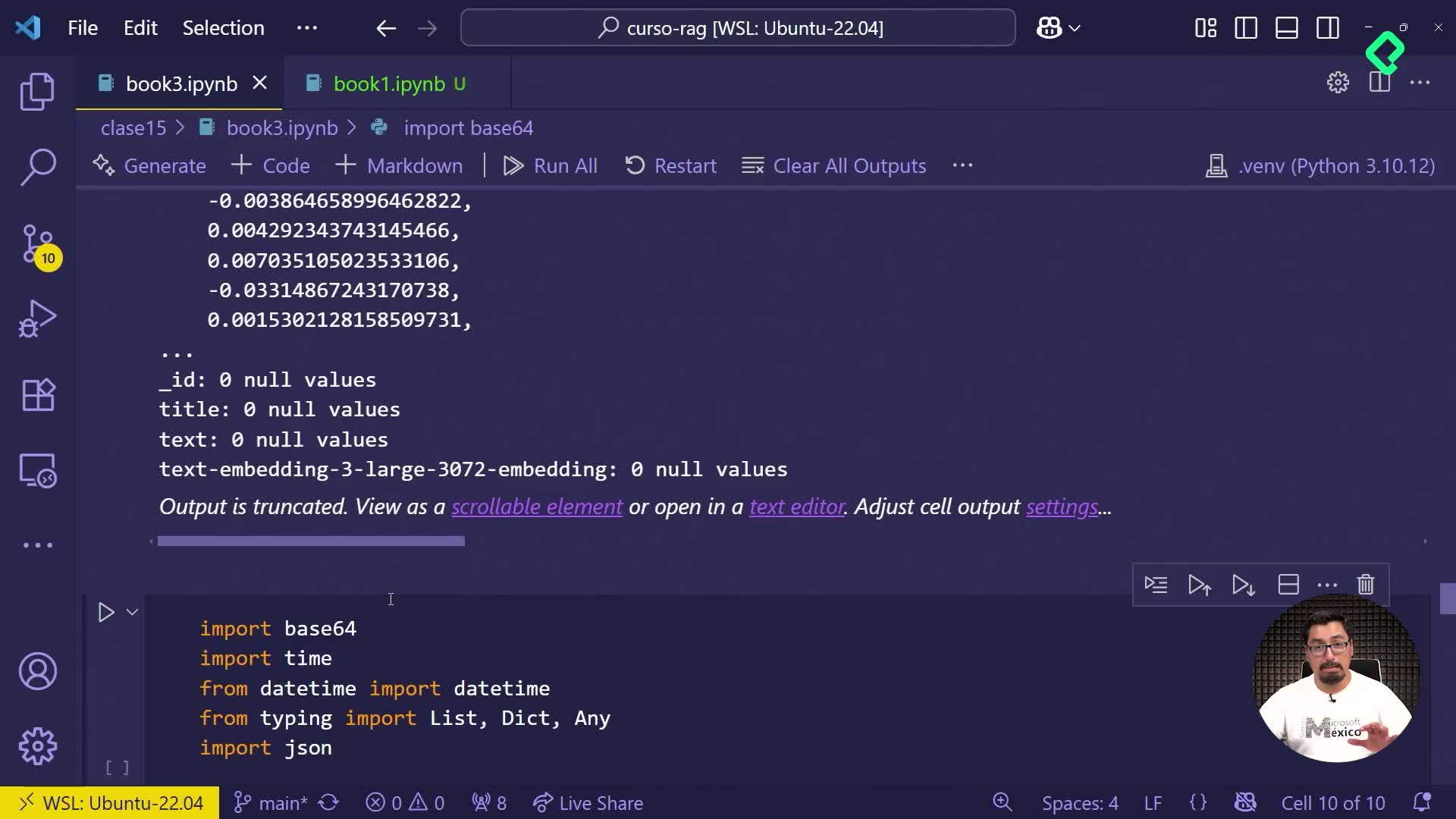
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
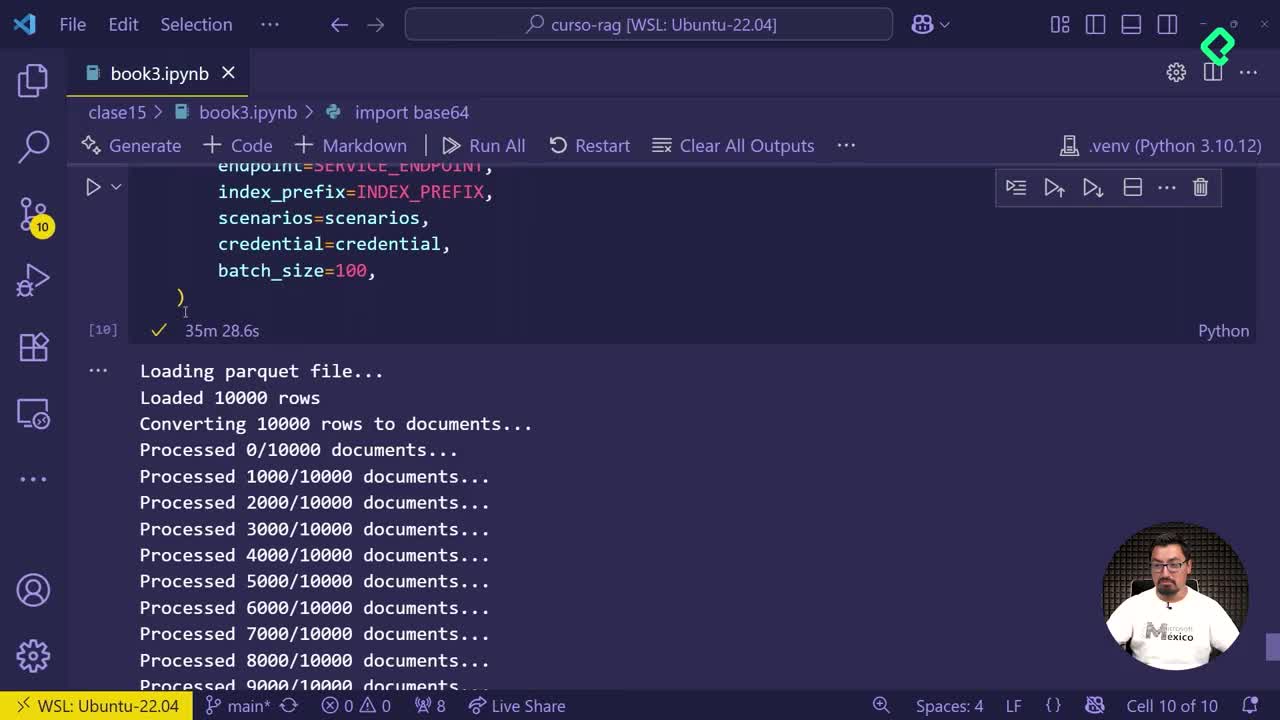
Cómo comparar índices vectoriales en Azure AI Search
03:58 min - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Arquitetura RAG: agente antes do LLM
Resumen
Entender la arquitectura de un sistema RAG cambia por completo la forma en que diseñas aplicaciones con inteligencia artificial. Aquí descubrirás por qué el agente de orquestación, y no el LLM, es el verdadero centro del flujo, y cómo este conocimiento te ahorra errores costosos al construir tus primeros sistemas inteligentes.
¿Por qué una aplicación no se comunica directamente con un LLM?
Uno de los errores más comunes al empezar con RAG es asumir que tu aplicación web, móvil o de televisión habla directamente con un modelo como GPT-4, Ollama o Gemini. La realidad es otra.
La aplicación se comunica con un agente de orquestación, y ese agente es el que realmente importa. Si quieres cambiar de modelo, solo ajustas unas pocas líneas para adaptarte. Lo esencial vive en ese agente que coordina todo el flujo.
¿Qué es un agente de orquestación en RAG? Es el componente que coordina la comunicación entre tu aplicación, el sistema RAG y los modelos LLM. Decide qué consultar primero y cómo presentar la respuesta final.
¿Cómo fluye la información entre el agente, el RAG y el LLM?
El flujo correcto rompe con la intuición inicial. No es el modelo quien busca la información, sino el orquestador quien dirige el tráfico.
El recorrido se da en este orden:
- La aplicación envía la consulta al agente de orquestación.
- El agente acude primero al sistema RAG, no al LLM.
- El RAG busca en sus fuentes de información y devuelve los datos al agente.
- El agente entrega esa información al LLM para que la presente de forma comprensible.
Este detalle, pasar primero por el RAG y después por el LLM, es lo que marca la diferencia entre un sistema que responde con contexto real y uno que alucina respuestas.
¿Qué tipos de fuentes consulta el sistema RAG?
El sistema RAG es el único componente que se conecta directamente con tus fuentes de datos. Puede consultar:
- Bases de datos estructuradas.
- Bases de datos no estructuradas.
- Bases de datos vectoriales, un concepto clave que se aborda más adelante.
Ningún modelo habla de forma directa o abierta con un sistema RAG. Siempre lo hace a través de la orquestación.
¿Por qué el orquestador concentra la mayor responsabilidad del sistema?
Cuando piensas en un proyecto más complejo, el orquestador puede comunicarse con múltiples sistemas RAG y múltiples modelos LLM al mismo tiempo. Esa flexibilidad lo convierte en la pieza con mayor carga de responsabilidad de toda la arquitectura.
Gracias a él, la información fluye de manera mucho más eficaz, y puedes escalar tu sistema sin reescribirlo desde cero cada vez que quieras integrar un nuevo modelo o una nueva fuente de datos.
¿Por qué el agente consulta primero el RAG y no el LLM? Porque el RAG aporta la información real y actualizada desde tus fuentes. El LLM solo se encarga de redactar la respuesta final con ese contexto ya recuperado.
¿Qué conceptos debes dominar antes de programar tu primer RAG?
La ingeniería de software tradicional te dice que guardar un documento en una base de datos es sencillo. En RAG, el concepto cambia por completo. Añadir información adicional a un agente para que la consulte tampoco es trivial, y muchos fracasan en ese camino.
Los pilares conceptuales que necesitas tener claros son:
- La experiencia de usuario como punto de entrada al sistema.
- El agente de orquestación como cerebro coordinador.
- El sistema RAG como único puente con las fuentes de datos.
- Los modelos LLM como capa de presentación del contenido recuperado.
- Las bases de datos vectoriales como pieza específica dentro del ecosistema de fuentes.
Domina este flujo general y ya tienes la mitad del camino recorrido en el aprendizaje de sistemas RAG. Repítelo, dibújalo, practícalo mientras sales a correr si hace falta. Lo importante es que el modelo mental quede grabado.
¿Cómo imaginas tu primer agente de orquestación? Comparte en los comentarios qué fuentes de datos te gustaría conectar primero.