Embeddings y vectorización en RAG
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
Viendo ahora - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
04:49 min - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
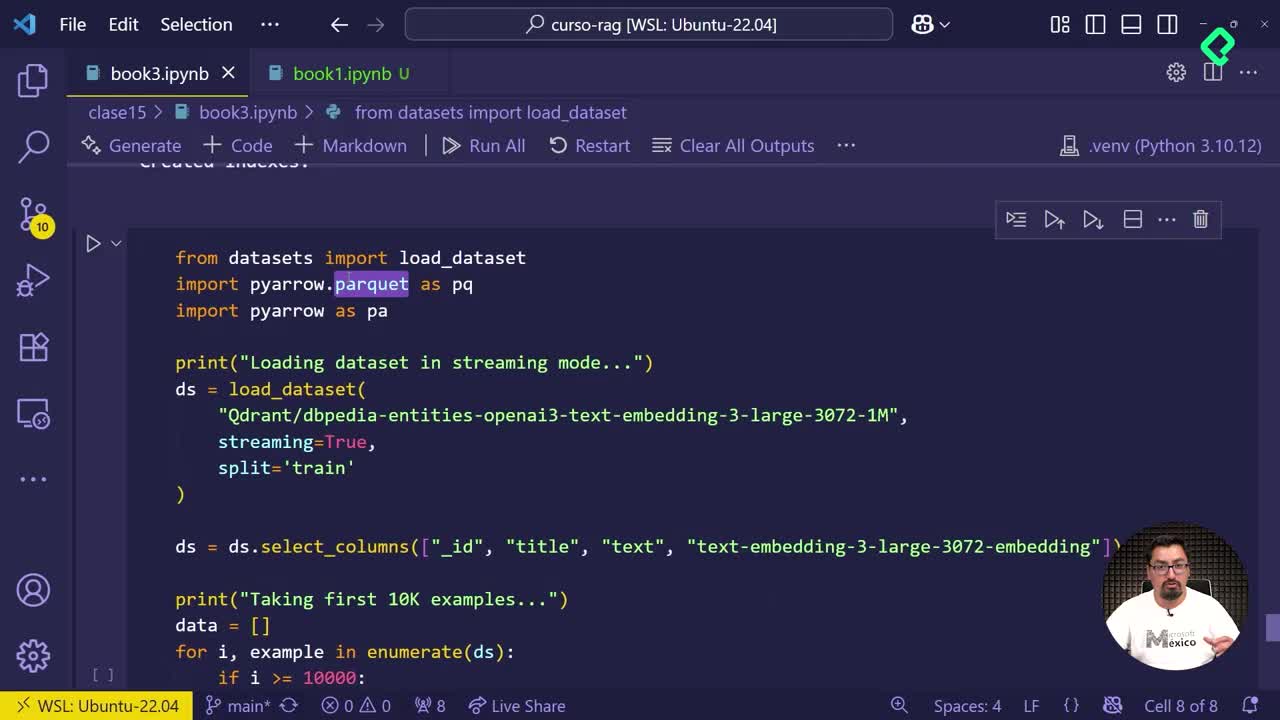
Cómo guardar embeddings en Parquet para la nube
03:13 min - 18
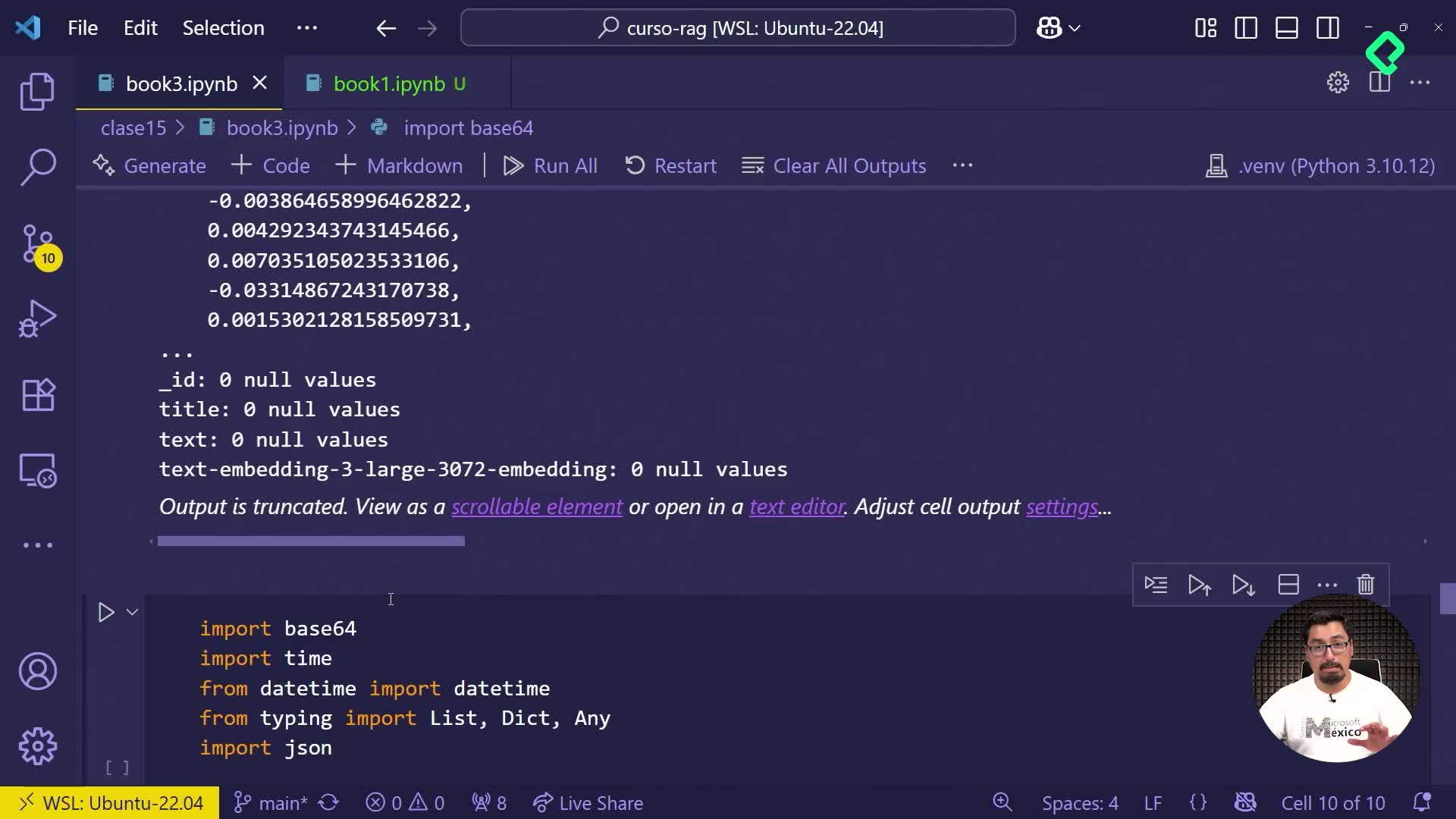
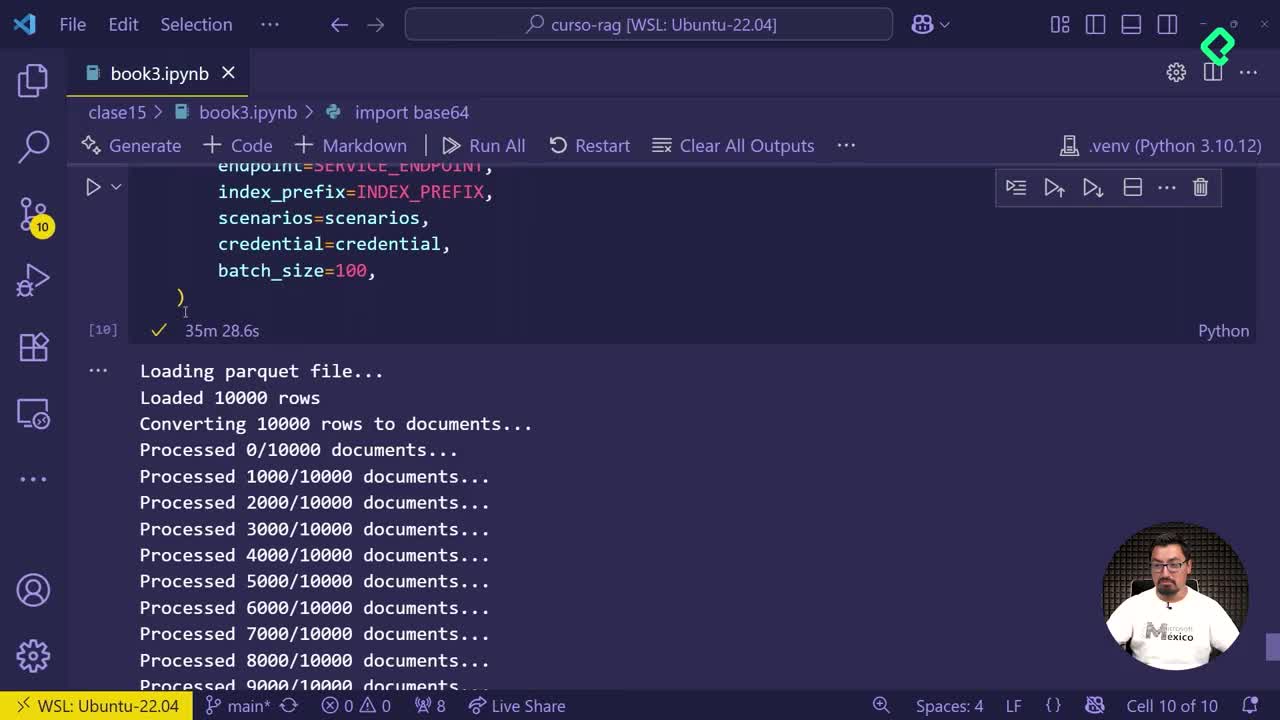
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
Cómo comparar índices vectoriales en Azure AI Search
03:58 min - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Embeddings y vectorización en RAG
Resumen
Los embeddings son la pieza que convierte tus documentos en información que un modelo puede entender y consultar dentro de un sistema RAG. Si vienes del mundo de los chunks, este es el siguiente paso lógico: aquí aprendes cómo tus textos, imágenes, audios y videos terminan ordenados dentro de una base de datos vectorial lista para responder preguntas.
Qué es un embedding y por qué importa en RAG
Piensa en cualquier archivo que tengas a la mano: un PDF, una imagen, un audio, un video. Para nosotros tiene sentido porque le damos coherencia, pero por dentro no es más que un arreglo de bytes, información estructurada esperando ser procesada.
Un embedding model toma esos archivos, los fragmenta y los transforma en vector embeddings, que son representaciones numéricas con las que sí puede trabajar un sistema de búsqueda inteligente. Y aquí viene lo interesante: existen muchos modelos distintos, y cada uno responde mejor a ciertos formatos. Hay modelos más afines a imágenes, otros a PDFs, otros a videos.
¿Qué es un embedding? Es la representación numérica (un vector) de un fragmento de información, ya sea texto, imagen, audio o video, que permite que un sistema lo organice y lo consulte por similitud.
Cómo se procesa la información paso a paso
El camino que recorre un archivo hasta volverse consultable tiene etapas muy claras, y vale la pena entenderlas en orden porque cada una depende de la anterior.
- Ingesta de datos: envías toda tu información al embedding model que elegiste.
- Procesamiento del modelo: el modelo limpia y normaliza los archivos según el formato con el que es más compatible.
- Chunking: los archivos se dividen en fragmentos manejables que luego se organizan en la base de datos.
- Vectorización: cada chunk recibe un valor numérico y se convierte en un vector.
- Indexación: esos vectores se ordenan de la forma que el modelo considera más eficiente para consultarlos después.
Después de la indexación, los chunks ya tienen un orden fijo y pueden guardarse en una base de datos vectorial. Desde ahí puedes consultarlos y generar información adicional con tu agente.
Por qué la indexación es la etapa más crítica
La indexación define la calidad de tus respuestas. Según el modelo de embeddings que uses, el orden de los vectores cambia, y con ese orden cambian también los resultados que obtienes al hacer una consulta.
Eso significa que dos sistemas RAG con los mismos documentos pueden entregarte respuestas distintas solo por haber usado embedding models diferentes. Por eso elegir bien el modelo no es un detalle, es la decisión que más impacta el desempeño.
¿Por qué la indexación define la calidad de un RAG? Porque el orden numérico que el modelo asigna a cada vector determina qué fragmentos se recuperan ante una consulta. Si el orden no es bueno, las respuestas tampoco lo serán.
Cómo elegir el embedding model adecuado
No necesitas construir un embedding model desde cero. Los proveedores de nube ya tienen modelos creados y hospedados listos para usarse, así que tu trabajo es seleccionar el que mejor se adapte a tu caso.
Un tip práctico: prueba el mismo proceso con varios embedding models distintos. Vas a equivocarte, sí, pero ahí está el aprendizaje real. Comparar resultados te muestra cuál modelo se siente más cómodo con tus tipos de archivo y con las preguntas que tu sistema necesita responder.
Aunque en un entorno de práctica puedes trabajar con elementos locales, lo ideal para un sistema verdaderamente productivo es apoyarte en un proveedor de nube. Ahí mandas tu información al embedding model, dejas que haga el procesamiento pesado y conectas todo a tu agente con RAG.
¿Dónde están los embedding models listos para usar? Están hospedados en los principales proveedores de nube, así que puedes consumirlos como servicio sin entrenar nada por tu cuenta.
¿Con qué tipo de archivos estás pensando alimentar tu primer sistema RAG? Cuéntame en los comentarios qué embedding model vas a probar primero.