Qué son las bases de datos vectoriales
Contenido del curso
Etapas de RAG
- 5

Embeddings y vectorización en RAG
03:34 min - 6

RAG en Azure en lugar de local
03:51 min - 7

Qué son las bases de datos vectoriales
Viendo ahora - 8

Desplegando infraestructura RAG en Azure
05:15 min - 9

Despliegue de modelos GPT-4 y embeddings en Azure OpenAI
03:01 min - 10

Configuración de Jupyter Notebook y ambientes virtuales en Python
03:36 min
Tecnicas de RAG
- 11
Vectorización de documentos con Azure Search y OpenAI
06:15 min - 12
Configuración de Azure OpenAI y AI Search en Jupyter Notebook
06:56 min - 13

Integración de LLM para optimizar respuestas en Jupyter Notebook
03:09 min - 14

Reindexar nuevos PDFs en Azure AI Search
03:16 min - 15
Búsqueda tradicional, vectorial e híbrida en Azure AI Search
06:04 min
RAG avanzado
- 16
Creación de múltiples índices en Azure AI Search con Jupyter
09:40 min - 17
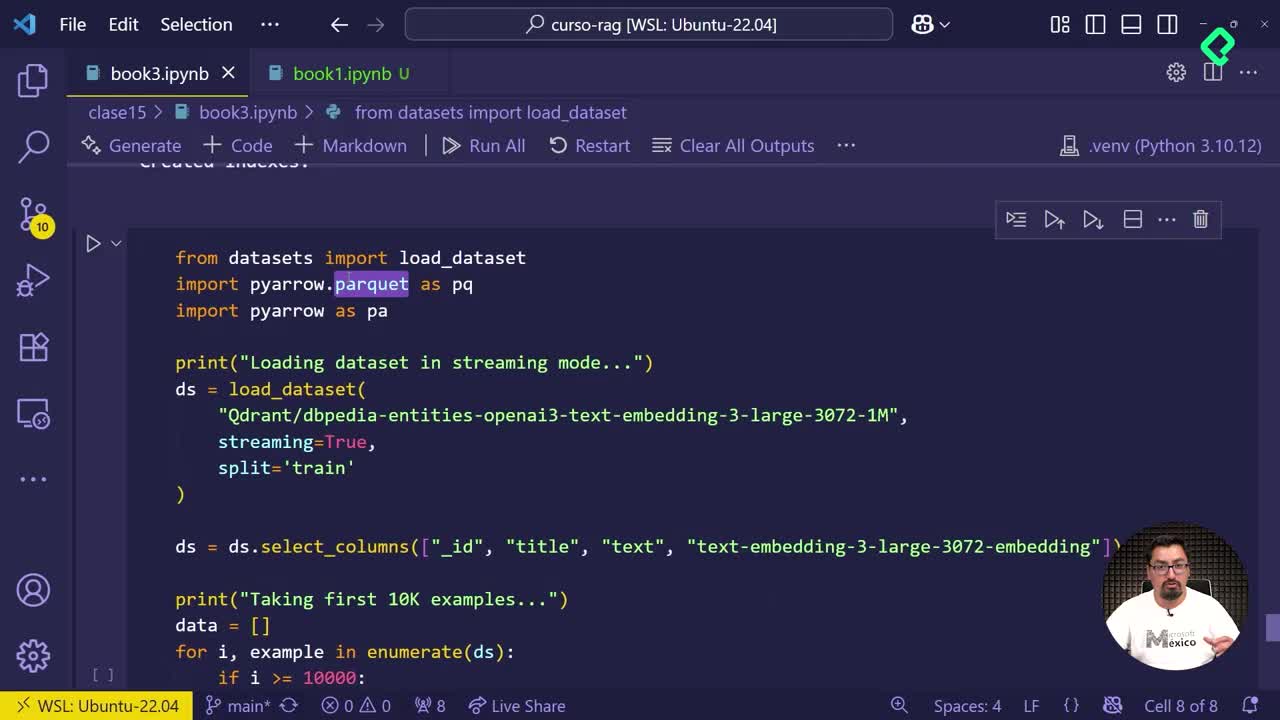
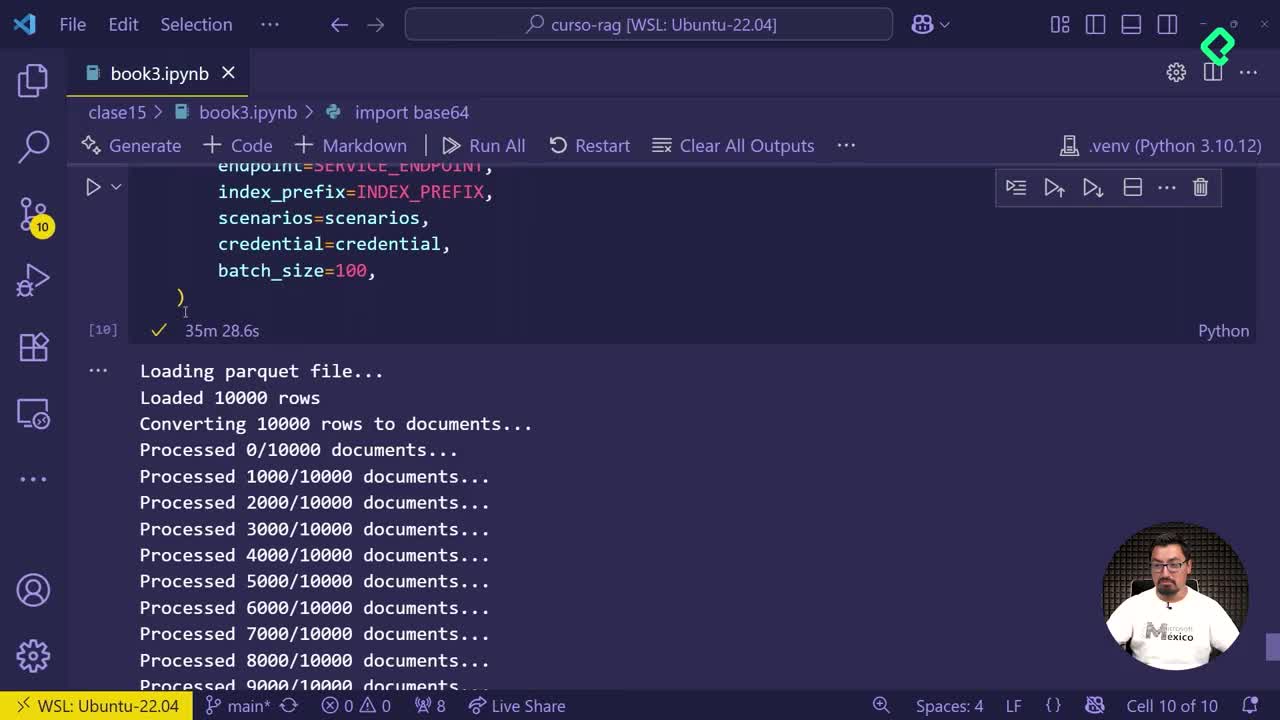
Cómo guardar embeddings en Parquet para la nube
03:13 min - 18
Subida automática de documentos fragmentados a Azure AI Search
02:52 min - 19
Cómo comparar índices vectoriales en Azure AI Search
03:58 min - 20

Demo app de Azure AI Search en minutos
03:38 min
Fusionando RAG con un agente
Qué son las bases de datos vectoriales
Resumen
Las bases de datos vectoriales son el motor que permite que sistemas como Netflix, Spotify y los flujos RAG encuentren información por similitud semántica en lugar de coincidencias exactas. Si vienes de SQL o MongoDB, este modelo cambia las reglas: ya no piensas en filas ni documentos, piensas en espacios tridimensionales.
¿Qué es una base de datos vectorial y por qué importa?
Una base de datos vectorial organiza la información en un núcleo de tres dimensiones, donde cada chunk se ubica cerca de otros con significado parecido. Si tienes fragmentos sobre computadoras, se agrupan en una zona; si el mismo documento también habla de reciclaje electrónico, esos fragmentos viajan a otra zona vinculada con hogar y familia. Y si aparece un tercer tema, ocupa un tercer vector.
Esta lógica rompe con lo que veníamos haciendo. Las bases de datos relacionales como SQL, MySQL u Oracle trabajan con tablas y estructura rígida. Las no relacionales guardan documentos completos para consultarlos rápido. Los grafos saltan entre nodos para encontrar relaciones. Pero ninguna piensa en tres dimensiones [01:00].
¿Qué es una base de datos vectorial? Es una base de datos que almacena pequeños pedazos de información (chunks) en un espacio tridimensional, donde la cercanía entre puntos representa similitud semántica. No guarda información lineal, sino fragmentos indexados para búsqueda por significado.
¿Cómo funciona la búsqueda por similitud semántica?
A diferencia de los documentos lineales de una base no relacional, aquí la información se almacena en pedazos pequeños que quedan estructurados gracias a los índices generados en la etapa de indexación. Cuando haces una consulta, la base no busca palabras exactas: busca el chunk que mejor encaje dentro de esa conversación.
Imagina que preguntas sobre planetas. La base recorre el espacio tridimensional, descarta zonas vacías y elige el índice más cercano al sentido de tu pregunta. Esa es la similitud semántica: encontrar lo más parecido en significado, no en letras [02:30].
¿Quién usa esto en producción?
Netflix y Spotify ya lo aplican. Cuando terminas una canción o una película, sus bases vectoriales identifican los índices más parecidos a lo que acabas de consumir y te recomiendan el siguiente contenido. Ese flujo de recomendación instantáneo vive sobre vectores.
¿Cuáles son las mejores bases de datos vectoriales del mercado?
El mercado de bases vectoriales está creciendo y conviven dos tipos de jugadores: los tradicionales con soporte vectorial añadido y los nativos.
- PostgreSQL: soporta búsquedas vectoriales, útil si quieres mezclar relacional y vectorial en un solo motor.
- Cassandra: también admite vectores, aunque no es su fuerte.
- LanceDB, Milvus, Vespa, Chroma: jugadores nativos que dominan hoy el espacio vectorial.
Que una base relacional soporte vectores no significa que sea la mejor opción. PostgreSQL puede funcionarte si necesitas algo híbrido rápido, pero se queda corto frente a las opciones nativas cuando el volumen y la precisión importan [04:15].
¿Conviene usar PostgreSQL para vectores o una base nativa? Depende del caso. PostgreSQL sirve para proyectos pequeños o híbridos, pero si tu producto depende de búsqueda semántica a escala, una base nativa como Milvus o Chroma rinde mucho mejor.
¿Una sola base o arquitectura híbrida?
La decisión inteligente, desde la perspectiva de un arquitecto de software, suele ser usar dos bases de datos en paralelo: una vectorial para búsqueda semántica y una estructurada para datos lineales. Así obtienes lo mejor de ambos mundos sin forzar a un motor a hacer lo que no fue diseñado para hacer.
¿Cómo se conecta esto con un proceso RAG?
La indexación es el corazón del asunto. Cada chunk recibe un índice que define su posición dentro del espacio vectorial, y ese ordenamiento es lo que permite que un proceso de RAG (Retrieval Augmented Generation) recupere fragmentos relevantes para alimentar al modelo.
Dominar esta lógica te da tres habilidades concretas:
- Entender cómo se acomodan los índices dentro del espacio tridimensional.
- Estructurar chunks de forma que la búsqueda semántica devuelva resultados útiles.
- Extraer información precisa para enriquecer respuestas generativas con RAG.
Visualizar un entorno tridimensional cuesta trabajo, no te voy a mentir. Yo mismo sigo aprendiendo a conceptualizarlo después de años trabajando con SQL. Pero una vez que lo asimilas, abres la puerta a construir buscadores, recomendadores y asistentes con IA que entienden lo que el usuario realmente quiere decir.
¿Ya estás usando alguna base vectorial en tus proyectos? Cuéntame en los comentarios cuál te ha funcionado mejor.