The row space and left null space complete the four fundamental subspaces of a matrix, and understanding their orthogonal relationship reveals one of the most elegant properties in linear algebra. If you already grasp the column space and null space, these two new subspaces will click quickly because they are mirror images obtained through transposition.
What are the four fundamental subspaces of a matrix?
Every matrix has four fundamental subspaces, and the last two come directly from transposing the matrix.
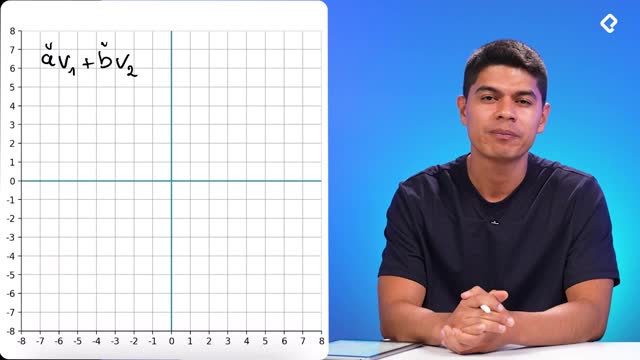
The row space is defined as the column space of the transposed matrix, written as col(Aᵀ). Since transposing swaps columns and rows, this subspace represents all linear combinations of the row vectors of the original matrix.
The left null space is the null space of the transposed matrix, written as null(Aᵀ). It follows the same logic as the regular null space, just applied to the rotated version of your matrix.
What is the row space of a matrix? It is the set of all linear combinations of the row vectors, formally written as col(Aᵀ). It contains every input direction that the matrix actually responds to.
How are the four subspaces related geometrically?
These subspaces do not live in isolation. They share a geometric relationship that ties the entire structure of the matrix together [1:30].
The row space col(Aᵀ) is always orthogonal to the null space null(A). And the column space col(A) is always orthogonal to the left null space null(Aᵀ). Orthogonal here means exactly what you would expect: any vector you pick from the row space forms a 90 degree angle with any vector you pick from the null space.
Why does this hold? Think of it this way: a vector X belongs to the null space when AX = 0. The operation AX is a series of dot products between the rows of A and the vector X. For the result to be zero, each dot product between a row of A and X must equal zero, and a dot product of zero is the very definition of orthogonality [2:15].
How do you verify orthogonality with a real example?
Let's use the matrix M with rows 1, 2 and 2, 4. One row vector is V1 = (1, 2), and from previous work we know that X = (-2, 1) makes AX = 0, placing it in the null space [3:00].
Graphically, V1 = (1, 2) points up and to the right, while X = (-2, 1) points up and to the left. They form a clean 90 degree angle.
Algebraically, the dot product confirms it:
- V1 · X = (1)(-2) + (2)(1).
- That equals -2 + 2.
- The result is 0.
What does it mean for two vectors to be orthogonal? It means their dot product equals zero, which geometrically translates to a 90 degree angle between them. In matrix terms, it signals that one vector lies entirely outside the other's subspace influence.
Why does this orthogonality matter in linear algebra?
The row space, which you can think of as the line of relevant inputs, and the null space, the line of inputs that get crushed to zero, are perfectly perpendicular. Together they describe the entire input space.
This separation is powerful because it lets you cleanly split any input vector into two parts:
- The portion that genuinely matters for the transformation, living in the row space.
- The portion that is completely ignored and collapsed to zero, living in the null space.
That decomposition is what makes orthogonality one of the most useful properties in linear algebra. It gives you a structural map of how a matrix treats every possible input.
Practice exercise to reinforce the concept
Using the same matrix M and the same row vector V1 = (1, 2), find a different vector X (not (-2, 1)) that still satisfies AX = 0. Then verify whether your new X is orthogonal to V1.
You can do this two ways:
- Graphically, by plotting both vectors and checking the angle.
- Algebraically, by computing the dot product and confirming it equals zero.
- Or both, to strengthen your intuition.
Share your vector and your verification in the comments. In the next lesson we'll look at how to find these subspaces for larger, more complex matrices and how to simplify a matrix without altering its fundamental subspaces.